
ARTICULO
RESUMEN RESULTADOS
- Validez de la Entrevista Conductual Estructurada (ECE)
- Diseño del estudio
- Validez de la ECE por ocupaciones
DISCUSION
La entrevista es el instrumento más empleado en selección de personal, a pesar de que parece tener baja fiabilidad y escasa validez. Recientemente, diversos autores sugirieron que ciertos cambios mejorarían la validez la entrevista. Las modificaciones se refieren a su estructura y su contenido. Varias entrevistas, que por sus similitudes denominamos "conductuales estructuradas" (ECE), parecen poseer una validez aceptable. Para comprobar la validez de la ECE y su generalización, un método adecuado es el meta-análisis. El objetivo principal de esta investigación fue la integración de los coeficientes de validez de la ECE. El segundo era comprobar si el tipo de diseño de validación tiene efectos sobre el coeficiente de validez. El tercer objetivo fue estimar la validez de la ECE para distintas ocupaciones. Los resultados indican que la ECE es fiable (acuerdo entre jueces =.75) y válida (r=.28, N=2121), similar a la de otros instrumentos de selección (por ej., tests de habilidades cognitivas). Los coeficientes de validez de los diseños concurrentes son similares o más altos que los que resultan con diseños predictivos. En tercer lugar, la ECE es válida para cualquier tipo de ocupación. Por último, se discuten las implicaciones de los resultados para la aplicación de la ECE y se señalan algunas áreas de investigación futura.
Personnel selection interviews were criticized for low reliability and validity. However, the interviews based on behavior descriptions appear to have an acceptable validity to predict job performance. To check that point we conduct several meta-analyses. The main objective of this article was to integrate the validity coefficients of structured behavioral interviews (SBI). The second objective was to test if the research design (concurrent vs. predictive) has some effect on the coefficients. The third goal was to estimate the BSI validity for several occupational groups. Results show that BSI is a reliable (inter-rater reliability =.75) and valid procedure (r=.28, N=21.21). Second, the coefficients from concurrent designs are similar or slightly higher than the coefficients from predictive designs. Third, SBI is a valid procedure for all occupational groups. Finally, the implications of these results are discussed and future areas for research are suggested.
Entrevista Conductual Estructurada, Validez, Meta-Análisis.
Structured Behavioral Interview, Validity, Meta-Analysis.
La entrevista de empleo es, probablemente, el instrumento de selección de personal más utilizado de cuantos están a disposición de los profesionales de recursos humanos (Schneider y Schmidt, 1986). Esta afirmación se ha visto reforzada por varios estudios recientes realizados en diversos países europeos (Schackleton y Newell, 1991; Smith y Abrahamsen, 1992). En una encuesta efectuada por Roberston y Markin (1986) entre las 1000 empresas más importantes del Reino Unido, la entrevista emplea en más del 90 por ciento de los casos. En Francia, Bruchon- Schweitzer y Ferrieux (1991) encontraron que el 95 por ciento de las empresas emplean la entrevista. En España, Rodríguez, Chinchilla, Casanova y Renter (1990) y Ruiz, Fernández y Franza (1992) han encontrado que la entrevista es el factor determinante en la toma de decisión para cualquier nivel de empleo y lo mismo sugieren Prieto, Blasco y Quintanilla (1991). En conjunto, los resultados de estos estudios muestran sin lugar a dudas que la entrevista se utiliza en más del 90% de las contrataciones y, excepto el currículum vitae, ningún otro instrumento de selección se le aproxima en uso.
Esta utilización masiva de la entrevista no parece guardar relación con las características psicométricas (fiabilidad y validez) y económicas (utilidad) de la misma. En los últimos 50 años se han realizado al menos 7 grandes revisiones cualitativas de la literatura científica sobre la entrevista de selección (Wagner, 1949; Mayfield, 1964; Ulrich y Trumbo, 1965; Wright, 1969; Schmidt, 1976; Arvey y Campion, 1982) y todos los autores coinciden en que la entrevista presenta una fiabilidad en un rango de moderada a baja y apenas validez de criterio (predictiva y concurrente), de donde se sigue una utilidad (rendimiento económico) prácticamente nula como instrumento de selección. A los mismos resultados llegan los meta-análisis de los resultados de la investigación realizados por Reilly y Chao (1982) y Hunter y Hunter (1984). Puesto que estos hallazgos no justifican el uso tan desmedido de la entrevista, los revisores de la literatura científica suelen explicar tal empleo afirmando que: a) es un instrumento aparentemente fácil de usar por cualquiera aunque no esté instruido al respecto, b) es muy versátil ya que sirve para cualquier puesto, organización o situación, c) es relativamente más barato que otros instrumentos de selección ("assessments centers", por ejemplo), d) ofrece algunas ventajas que nd poseen los restantes, como el conocimiento personal de los evaluados, e) permite dar información personalizada sobre la organización al entrevistado, y f) los managers y solicitantes la aceptan mejor que otros instrumentos en los procesos de selección.
Tales consideraciones, aunque importantes para incluir la entrevista entre los instrumentos de selección, no permiten defender el uso de la misma como herramienta de apoyo para la toma de decisiones de contratación. Si, tal como los revisores de la literatura afirman, la entrevista carece de validez o no incrementa la conseguida por otros instrumentos, su utilización encarece el proceso de selección, lo alarga innecesariamente e introduce un sesgo subjetivo en los procesos de selección, con consecuencias negativas tanto para las organizaciones como para los candidatos. Tal sesgo negativo será máximo cuando la entrevista sea la única fuente de recogida de información para la toma de decisiones de contratación, situación bastante frecuente.
Sin embargo, en la última gran revisión cualitativa de la literatura sobre la entrevista, Harris (1989) señala el cambio que se está produciendo en los últimos años, indicando que las recientes investigaciones sugieren que la entrevista puede ser mucho más válida y eficaz de lo que habían mostrado las anteriores revisiones. En opinión de Harris, las recientes investigaciones indican que, con determinadas características y en ciertas condiciones, la entrevista de selección posee fiabilidad, validez, incrementa la validez de las baterías de instrumentos de selección y presenta una apreciable utilidad económica.
Así, por ejemplo, Arvey, Miller, Gould y Burch (1987) presentan datos que muestran la entrevista estructurada tiene una validez aceptable para la selección de personal de puestos de venta. Campion, Pursell y Brown (1988) llegan a resultados semejantes con un formato de entrevista estructurado para la selección de empleados de una empresa papelera. Resultados todavía más contundentes son los presentados por Wiesner y Cronshaw (1988) en su meta-análisis de los coeficientes de validez de la entrevista, donde se muestra que la entrevista tiene una validez predictiva similar a los restantes instrumentos de selección más eficaces (tests de habilidades cognitivas, assessment centers, biodata, evaluaciones de pares) o inclusive superiores, dependiendo del criterio utilizado y del formato de la entrevista. A resultados semejantes llega el meta-análisis realizado por McDaniel, Whetzel, Schmidt y Maurer (1994).
En el formato (grado de estructuración) y en el contenido de las preguntas de la entrevista parecen residir dos de los aspectos fundamentales para la validez de la entrevista. Para incrementar---la validez se han propuesto varias alternativas como la entrevista "estructurada desarrollada a partir de un análisis del puesto (EEAP)" (Campion, Pursell y Brown, 1988; Wright, Lichtenfels y Pursell, 1989), la "entrevista situacional (ES)" (Latham, Saari, Pursell y M. Campion, 1980; Latham, 1989) o la entrevista "estructurada de descripción de conducta (EEDC)" (Janz, 1982, 1989), la ,,entrevista multi-modal (EMM)" (Schuler, 1989; Schuler y Funke, 1989), la ,,entrevista conductual (EC)" (Green y Horgan, 1982), y la "entrevista conductual estructurada (ECE)" (Motowidlo et aL, 1992). Estos tipos de entrevista, aunque difieren en ciertos aspectos, Comparten muchos puntas en común que permiten englobarlas en una categoría general a la que se puede denominar "entrevista conductual estructurada (ECE)".
Las principales características que comparten los tres tipos de entrevista anteriores y que definirían a la entrevista conductual estructurada son las siguientes: 1) las preguntas que componen la entrevista se desarrollan a partir de un análisis de puestos, 2) se formulan a cada candidato todas las cuestiones desarrolladas; 3) se repite todo el proceso de entrevista con todos los entrevistados; 4) las respuestas de los sujetos se evalúan mediante "escalas de conductas observadas" (Quijano, 1992).
En dos de los meta-análisis generales realizados hasta el momento sobre la validez y la fiabilidad de la entrevista de empleo (Hunter y Hunter, 1984; Wiesner y Cronshaw, 1988) no figuran datos referentes a la entrevista estructurada basada en conducta, mientras que sí se poseen sobre otras modalidades de entrevista no estructurada, estructurada con un participante y un entrevistador, entrevista de panel, etc. En el meta-análisis realizado por Wright et al. (1989), que recoge parte de la investigación realizada con esta modalidad de entrevista, los resultados indican un coeficiente de validez promedio de 0.34. Desafortunadamente, en dicho estudio solo está incluida una parte muy pequeña de los estudios realizados y tal circunstancia podría modificar sustancialmente los resultados finales. Por su parte, McDaniel et al. (1994) obtienen un coeficiente de validez no corregida .25 para la entrevista situacional. Sin embargo, estos últimos autores, aunque realizan un meta-análisis específico para la entrevista situacional, consideran que la entrevista de Janz, la realizada por Arvey et al., la de Green y Horgan, o la de Motowidlo et al. no son semejantes a la situacional. Además, no incluyen varios estudios realizados con la entrevista situacional ni consideran la entrevista multi-modal de Schuler. Tampoco estudian los efectos del diseño de validación (concurrente frente a predictivo) ni la validez de la entrevista para diferentes puestos. Así pues, parece conveniente una integración cuantitativa de las investigaciones realizadas con la entrevista conductual estructurada para conocer el grado de validez que posee. De esta misma opinión es Harris (1989), quien en su revisión aboga por investigaciones sobre las propiedades psicométricas de los diferentes formatos de entrevista.
Este trabajo tiene como primer objetivo realizar una integración cuantitativa de los coeficientes de validez de la ECE, que se han publicado hasta el momento. En segundo lugar, se pretende comprobar si los diseños de validación de criterio empleados (predictivos y concurrentes) producen tamaños de efectos diferentes. Es habitual que se sostenga que los diseños concurrentes producen coeficientes de validez de tamaño inferior a los predictivos (Guion, 1965), sin embargo en una reciente investigación Schmidt, Gooding, Noe y Kirsch (1984) encontraron que los diseños concurrentes mostraban valores semejantes -a los predictivos e incluso ligeramente superiores. Y por último, intentaremos comprobar el grado de validez de la ECE para diferentes grupos ocupacionales.
Para realizar las integraciones optamos por la metodología propuesta por Schmidt y Hunter (1977), Hunter y Schmidt, (1990), Hunter, Schmidt y Jackson, (1982), consistente en calcular el tamaño de efecto medio como una estimación del tamaño del efecto de la población y corregir la varianza de los coeficientes muestrales descontando los errores artifactuales (errores -muestrales, fiabilidad del criterio y los predictores, etcétera).
Realizamos una búsqueda por ordenador, desde 1980 a 1994, utilizando los términos "Situacional Interview", "Behavioral Interview", y "Structured Interview" en la base de datos PSYCLIST. A la lista de trabajos resultante se le añadieron algunos artículos publicados que figuraban en el trabajo de McDaniel et al. (1994) y que no aparecían en la lista. Finalmente, al conjunto anterior se añadieron algunos trabajos no citados por McDaniel et al. ni tampoco recogidos en el PSYCLIST (por ej., Deller y Kleinmann, 1993; Schuler, 1989; Schuler y Funke, 1989). En total obtuvimos 16 trabajos que incluían 26 muestras independientes.
El objetivo de la búsqueda bibliográfica fue identificar todos los estudios publicados que presentasen estadísticos relacionales (por ejemplo, correlaciones producto momento de Pearson) o datos de los que pudieran derivarse dichos estadísticos (por, ejemplo, análisis de varianza, chi cuadrado, etc.) entrevista estructurada basada en conducta y un criterio de rendimiento en el puesto de trabajo. Pe cada estudio fue registrada la siguiente información, si estaba disponible: a) características de la muestra, tales como edad, sexo, profesión, etc.; b) tipo de diseño de validación empleado (predictivo/concurrente); c) tipo de medida de criterio usado; d) fiabilidad de las medidas de rendimiento y de la entrevista, e) tamaño de las muestras; f) estadísticos de relación entre entrevista y rendimiento.
En algunos estudios figuraban varios coeficientes de validez empleando la misma muestra. En este caso, procedimos a promediar los coeficientes para obtener un único coeficiente de validez para cada muestra. De este modo, puesto que teníamos 26 muestras nos resultaron 26 coeficientes de validez. Todos los coeficientes, excepto uno, eran positivos, con un rango de .04 a .64. El único coeficiente negativo que encontramos, lo consideramos un caso excepcional y, siguiendo las sugerencias de Hunter y Schmidt (1990), lo eliminamos la muestra final de coeficientes. De este modo, los meta- análisis se realizaron sobre un conjunto de 25 muestras independientes con otros tantos coeficientes de validez. Después de reunir los estudios y registrar sus características, el siguiente paso fue aplicar las fórmulas meta-analíticas desarrolladas por Hunter y Schmidt (1990).
La gran mayoría de los trabajos incluían información sobre la fiabilidad de la entrevista conductual estructurada. La información se refería tanto a la fiabilidad por acuerdo entre jueces como a la fiabilidad por consistencia interna. Desde el punto de vista de la selección de personal, la información más relevante es la que corresponde al acuerdo entre jueces. En la Tabla 1 figura la distribución de frecuencias de la fiabilidad por acuerdo entre jueces. Con los datos anteriores, la entrevista conductual estructurada tiene una fiabilidad promedio de .75 (SD=A2), muy semejante a la de otros instrumentos de selección como los cuestionarios de personalidad o algunos tests de habilidades.

También una gran parte de los trabajos incluían información sobre la fiabilidad del criterio, cosa infrecuente en los estudios meta-analíticos, y prácticamente todos los trabajos utilizaban escalas de valoración como medidas -del criterio. La gran mayoría de los trabajos que aportaban tal información presentaban coeficientes de acuerdo entre jueces. La distribución de frecuencias puede verse en la Tabla 2.
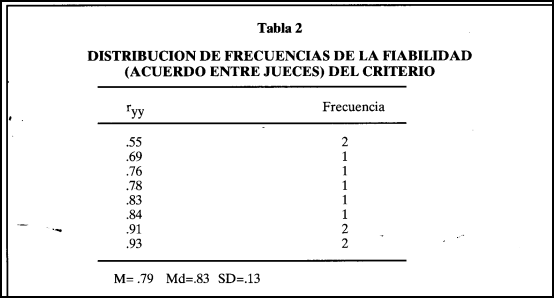
La fiabilidad promedio del criterio es .79 (SD =.13), un coeficiente sustancialmente más alto que el encontrado por Rothstein (1990; ryy=.48) y más elevado que el empleado por McDaniel et al. (1994) en sus correcciones de la validez observada. Estos últimos autores utilizan un coeficiente de .60 como fiabilidad de las valoraciones del rendimiento en el trabajo y lo aplican a todas las categorías de entrevista
que utilizan. Es posible que dicho valor se aproxime mucho a la fiabilidad del criterio en la mayoría de los estudios incluidos por McDaniel et al. (1994). Sin embargo, el caso de la entrevista conductual estructurada es especial, entre otras cosas, por el tipo de medidas del criterio utilizadas. Como se señaló antes, las "escalas de conductas observadas" y las "escalas de valoración con anclajes conductuales" presentan una fiabilidad sensiblemente más alta que otras escalas de valoración (ver Quijano, 1992). De aquí resulta que si se emplea .60 como valor de fiabilidad del criterio en las entrevistas situacionales se producirá una sobrecorrección de la validez.
Dado que no en todos los estudios figuraban los datos completos (fiabilidad del predictor, fiabilidad del criterio y restricción del rango, fundamentalmente) necesarios para efectuar las oportunas correcciones de los errores artifactuales, lo más conveniente es usar la estrategia denominada por Hunter y Schmidt (1990) metaanálisis de las correlaciones usando distribuciones de artificios. El análisis de los resultados se realizó empleando el programa INTNL (Schmidt, 1994) que permite el cálculo de las distribuciones de los errores artifactuales (debido a los errores de medida, restricción del rango y error de muestreo) y seguidamente corregir tanto la correlación media como la varianza observadas para obtener, finalmente, la validez verdadera media (p) y la varianza y desviación típica de la validez verdadera.
En la Tabla 3 figuran los resultados del meta-análisis realizado usando todos los coeficientes de correlación entre la ECE y un criterio de rendimiento. Puede observarse que la correlación promedio observada es de .28 y que, cuando se corrige por el error de medida en el criterio y la restricción del rango, la validez promedio verdadera asciende a .32. Cualquiera de los dos datos refleja una validez importante, por encima de la mayoría de las valideces tanto para tests de habilidades cognitivas como para predictores alternativos como assessment centers o evaluaciones de pares mostradas en investigaciones previas (por ejemplo, Hunter y Hunter, 1984; Reilly y Chao, 1982; Schmitt et al., 1984). La desviación típica observada indica que existe cierto grado de variabilidad, pero el error de muestreo explica más del 72%, y los cuatro artificios corregidos explican en conjunto más del 81%, lo que permite hipotetizar que la restante puede ser debida a otras fuentes de error no corregidas (errores de registro, de transcripción, etc.) y no consecuencia de factor el intrínsecos al estudio de validez (por ejemplo el puesto de trabajo, la organización, la muestra de sujetos, etc.). Dos datos más hay que destacar, en primer lugar que el tamaño medio de la muestra de los estudios de validez de la ECE es pequeño y similar a los encontrados por Lent, Aurbach y Levin (1971a, b) en los estudios de validez de los predictores. El segundo dato es el del valor de credibilidad del 90%. Este valor, si se aparta sustancialmente de cero, permite afirmar que la validez es generalizable entre muestras, puestos y organizaciones. De acuerdo al mismo, puede esperarse que el 90% de los casos en los que se emplee la ECE presenten como mínimo un tamaño de efecto de .24, ciertamente respetable.

Si el valor de la validez verdadera y el valor de credibilidad del 90% hallados en este estudio se comparan con los valores mostrados por McDaniel et al. (1994) para la entrevista situacional (.50 y .43 respectivamente) puede apreciarse que los encontrados aquí son bastante más bajos. Sin embargo, la validez promedio observada es similar en los dos casos (.28 aquí y .27 en McDaniel et al.). Una posible explicación vendría del hecho de que nosotros empleamos algunos estudios no utilizados por McDaniel et al. y de la inclusión en la categoría de "entrevista conductual estructurada" de algunos estudios de McDaniel et al. incluyen en la categoría de "entrevistas relacionadas con el puesto" (por ej., las de Janz). Sin embargo, la explicación más verosímil tiene que ver con los valores de fiabilidad del criterio y restricción del rango usadas por McDaniel et al. Como ya se señaló, éstos autores utilizan un valor de fiabilidad del criterio que sobrecorrige la validez observada y lo mismo sucede con el valor de restricción del rango. Unicamente, en dos estudios incluidos en nuestra muestra se produce un efecto de restricción del rango, siendo el promedio .99 (SD = .037). Por su parte McDaniel et al., que utilizan el mismo valor para todas las categorías y en todas las correcciones que efectúan, emplea .68 como valor de la restricción del rango. Es posible que este valor sea adecuado para la mayoría de las entrevistas utilizadas por McDaniel et al., pero se aleja mucho de valor adecuado para las entrevistas situacionales.
Si aplicamos a nuestros datos los valores de fiabilidad del criterio y de restricción del rango empleados por McDaniel et al. (1994), los valores resultantes son una validez verdadera de .63 y un valor de credibilidad de .46. Es decir, comparados con los valores de McDaniel et al., los nuestros serían algo más altos que los suyos. Al mismo tiempo, sin nuestros valores de fiabilidad y restricción del rango se aplicaran al valor de la validez observada obtenido por McDaniel et al., sus resultados serían p =.31 y VC =.25, es decir, idénticos a los nuestros. En consecuencia, puesto que los valores de fiabilidad del criterio y restricción del rango empleados en el presente estudio se derivan directamente de los trabajos con la entrevista conductual estructurada y su número es lo suficientemente representativo para que el promedio se pueda considerar una buena estimación de la fiabilidad del criterio y la restricción del rango, parece que los valores obtenidos aquí (p=.32; VC=.24) se ajustan más a la "verdadera" validez de la entrevista conductual estructurada y al valor mínimo esperable.
En la Tabla 4 aparecen los datos relevantes para la cuestión referente al tipo de diseño de validación empleado. Las diferencias en el coeficiente de validez promedio derivados de los dos tipos de diseños parecen tener cierta importancia. Habitualmente se suele indicar que la estrategia concurrente suele subestimar la validez del instrumento, pero en el presente caso no es así. Por lo que se refiere a los coeficientes promedio observados, los diseños concurrentes muestran un coeficiente de .32 mientras que el de los predictivos es de .24 y, cuando dichos coeficientes se corrigen por los errores de medida y restricción del rango, los coeficientes "verdaderos" son de .41 y .33 respectivamente. Así pues, en el caso de la ECE parece que la estrategia concurrente produce mejores coeficientes de validez, lo cual es contrario a la creencia tradicional pero concuerda con los resultados obtenidos por Schmitt et al. (1984) cuando analizan los efectos del tipo de diseño de validación sobre los instrumentos de selección de personal (no incluida la entrevista).
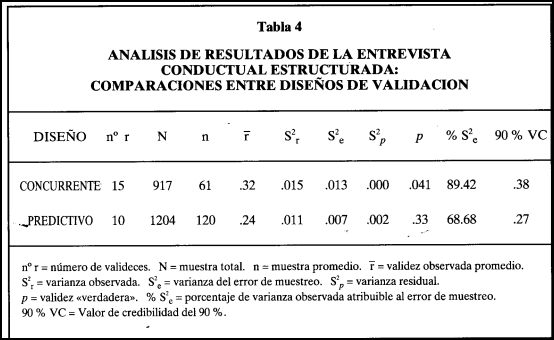
Un segundo dato a tener en cuenta es la variabilidad de los coeficientes de validez obtenidos con cada estrategia. Los diseños concurrentes presentan una menor variabilidad que los predictivos como lo reflejan sus respectivas desviaciones típicas observadas. La desviación en los diseños concurrentes es de .021 y la de los diseños predictivos es de .049. En cualquier caso, puede considerarse que la variabilidad es pequeña y por debajo de la obtenida en el meta-análisis global realizado por Schmitt et al. (1984) y considerablemente menor que la variabilidad que encuentran Wiesner y Cronshaw (1988) en cualquier tipo de entrevista.
Es de destacar que también existen diferencias notables en cuanto a los tamaños medios de las muestras empleadas en los diseños de validación. Mientras la muestra media de los diseños concurrentes es de 61 sujetos, en los diseños predictivos la muestra media es de 120 sujetos. De aquí resulta que el error de muestreo sea mucho mayor en los diseños concurrentes que en los predictivos. El error de muestreo explica más del 89% de la variabilidad encontrada en los diseños concurrentes, porcentaje que supera el 97% cuando se suman otras fuentes explicativas de varianza, por lo cual puede considerarse dicha variabilidad de naturaleza totalmente artificial. En los diseños predictivos el error de muestreo explica más del 68% de la varianza y cuando se añade la variabilidad explicada por los otros errores artificiales considerados en el meta-análisis, el porcentaje de varianza explicada es del 78%.
Los valores de credibilidad del 90% en los dos tipos de diseños son positivos y muy por encima de cero. El valor mínimo esperable en una validación concurrente es de .38 y el de una validación predictiva es de .27.
En la Tabla 5 pueden verse los resultados del meta-análisis empleando el tipo de ocupación como categoría de agrupamiento de la validez.
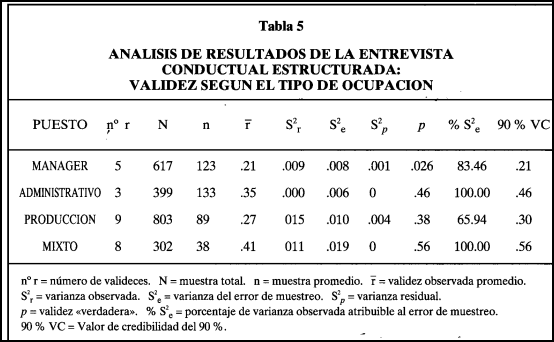
Los distintos puestos empleados en los estudios de validación de la entrevista conductual estructurada los agrupamos en tres categorías ocupacionales específicas managers, administrativos y producción. La agrupación la efectuamos usando como criterio de inclusión la similitud de tareas entre los puestos. Después de clasificar las distintas muestras, encontramos que algunas tenían un número excesivamente pequeño para constituir una categoría aparte (por ej., profesores, vendedores, policías, etc.). Todas estas muestras las agrupamos en una única categoría a la que denominamos mixta.
La entrevista conductual estructurada resulta ser válida para todas las ocupaciones, teniendo un rango de validez "verdadera" promedio de .26 para managers a .56 para el grupo mixto. Considerando exclusivamente los grupos ocupacionales bien definidos, la ECE parece ser especialmente válida para puestos administrativos (VC=A6) y puestos de producción (VC=30).
Los valores de la validez de la ECE para las distintas ocupaciones son particularmente relevantes porque son superiores a los obtenidos por Schmitt et al. (1984) para cualquier tipo de predictor y muy semejante a los valores obtenidos por Glauger, Rosenthal, Thorton y Bentson (1987) para los centros de evaluación ("assessment centers") que habitualmente son considerados los predictores con validez más elevada. Así pues, los resultados -obtenidos sugieren que la entrevista conductual estructurada es uno de los mejores, predictores del rendimiento en el trabajo para cualquier tipo de ocupación.
La opinión tradicional de que la entrevista de selección de personal es un instrumento pobre para predecir la posterior conducta en el puesto no parece consistente con las recientes investigaciones que se ocupan de comprobar la validez de ciertas modalidades de entrevista (McDaniel et al., 1994; Weisner y Cronshaw, 1988). Tanto los resultados de los meta-análisis que se presentan en este artículo como los resultados de las recientes investigaciones sobre la entrevista situacional, la entrevista estructurada de descripción de conducta y la entrevista estructurada basada en el análisis de puestos, sugieren que la entrevista de selección puede tener tanta capacidad predictiva como los mejores instrumentos de selección (por ejemplo, los tests de habilidades cognitivas, los "assessment centers" o las evaluaciones de pares). Para conseguir tal nivel predictivo, la entrevista habrá de ser desarrollada mediante un análisis de puestos sistemáticos, centrarse en los contenidos relevantes para el puesto y validarse contra criterios conductuales que hagan mínimos los efectos subjetivos de la valoración del rendimiento (por ej., escalas de conductas observadas).
Un segundo aspecto a considerar es el referente a la validez asociada con diseños concurrentes y predictivos. En el caso presente, los diseños concurrentes muestran un coeficiente de validez promedio más elevado que los predictivos. Aunque ello parece contradictorio con las opiniones tradicionales (Guion, 1965), concuerda con los datos obtenidos por Glauger et al. (1987) o por Schmitt y cols. (1984), y tomando los dos resultados es posible sugerir una revisión de la opinión tan extendida respecto de la mayor eficacia de los diseños predictivos.
Una tercera consideración se refiere a la generalización de la validez a diferentes muestras y ocupaciones. De los resultados obtenidos se desprende que la ECE es válida para cualquier tipo de ocupación y organización.
Junto con los resultados positivos anteriores deben hacerse ciertas matizaciones. Si bien los resultados de los meta- análisis presentados en este artículo apoyan la capacidad predictiva de la ECE, las características de la misma imponen ciertas restricciones a su empleo sistemático como instrumento de selección. Algunas de las razones esgrimidas para justificar el elevado uso de la entrevista (ver Harris, 1989: Schneider y Schmitt, 1986), a pesar de que mostraba baja fiabilidad y muy escasa validez, eran su facilidad de uso (cualquiera con apenas preparación podía realizarla), su generalidad (podía emplearse prácticamente en cualquier puesto) y su escaso coste de producción (limitado al tiempo empleado en la realización práctica de la entrevista). Ninguno de estos factores es característico de la ECE. Aunque es posible que con un entrenamiento adecuado cualquier profesional pueda realizarla, se requiere una formación y experiencia previa profunda tanto en su conducción como en su valoración, lo cual reduce considerablemente el número de posibles usuarios. En segundo lugar, dado que la ECE está condicionada a un análisis de puesto pormenorizado (habitualmente mediante la técnica de los incidentes críticos) su amplitud de uso es menor que los otros tipos de entrevistas. En tercer lugar, los costes de producción de una ECE son tan elevados como los de los instrumentos de selección más costosos (por ejemplo, tests de personalidad o "assessment centers"), ya que requieren la realización de análisis de puestos sistemáticos, precisa de un número elevado de expertos en el puesto y obliga a importantes análisis psicométricos previos a su validación y utilización.
Estas tres consideraciones sugieren que debe hacerse una evaluación pormenorizada de pros y contras antes de decidirse a un -uso generalizado de la ECE. Además, la evidencia encontrada indica que deben matizarse las características de la entrevista de selección, ya que habrá de diferenciar las de cada tipo de entrevista y no será adecuado hablar de las ventajas de la entrevista de selección de un modo general.
Por último, y con vistas a futuras investigaciones, la cuestión relativa a la contribución que la ECE hace sobre la validez predictiva obtenida por otros instrumentos (por ej., tests de habilidades cognitivas, biodata, et ' c.), todavía no ha sido investigada suficientemente. El asunto de la validez diferencial de la ECE es importante, puesto que algún estudio sugiere que la ECE no aporta varianza explicada sobre otros instrumentos (por ej., Gabris y Rock, 1991). La cuestión anterior y la relativa a la validez de constructo de la ECE son temas de investigación para el futuro.
En resumen, la ECE es un instrumento muy adecuado para la selección de personal caracterizado por las siguientes ventajas: a) posee una capacidad predictiva elevada, similar a las de los mejores instrumentos, y b) de donde se deriva una utilidad económica importante en términos de ganancia de productividad, al conseguir situar a personal más adecuado en los puestos y reducir considerablemente en número de malas colocaciones. Junto con estas ventajas, tiene las siguientes limitaciones: a) requiere un entrenamiento previo importante; b) reduce el número de posibles usuarios; c) requiere un elaborado proceso de producción; d) incrementa los costes del proceso de selección. No obstante, considerando conjuntamente las ventajas y las limitaciones, la ECE parece uno de los mejores instrumentos predictivos para la selección de personal.
