


The Relationship between Complications, Common Knowledge Details and Self-handicapping Strategies and Veracity: A Meta-analysis
[La relación de las complicaciones, los detalles de observación común y las estrategias de autojustificación con la veracidad: un meta-análisis]
Aldert Vrij1, Nicola Palena2, Sharon Leal1, and Letizia Caso3
1University of Portsmouth, United Kingdom; 2University of Bergamo, Italy; 3University of Lumsa, Rome, Italy
https://doi.org/10.5093/ejpalc2021a7
Received 25 January 2021, Accepted 12 April 2021
Abstract
Practitioners frequently inform us that variable ‘total details’ is not suitable for lie detection purposes in real life interviews. Practitioners cannot count the number of details in real time and the threshold of details required to classify someone as a truth teller or a lie teller is unknown. The authors started to address these issues by examining three new verbal veracity cues: complications, common knowledge details, and self-handicapping strategies. We present a meta-analysis regarding these three variables and compared the results with ‘total details’. Truth tellers reported more details (d = 0.28 to d = 0.45) and more complications (d = 0.51 to d = 0.62) and fewer common knowledge details (d = -0.40 to d = -0.46) and self-handicapping strategies (d = -0.37 to d = -0.50) than lie tellers. Complications was the best diagnostic veracity cue. The findings were similar for the initial free recall and the second recall in which only new information was examined. Four moderators (scenario, motivation, modality, and interview technique) did not affect the results. As a conclusion, complications in particular appear to be a good veracity indicator but more research is required. We included suggestions for such research.
Resumen
Los profesionales dicen con frecuencia que la variable “detalles totales” es adecuada para la detección de mentiras en las entrevistas de la vida real. No pueden contar el número de detalles en tiempo real y se desconoce el umbral de detalles necesario para clasificar a alguien como sincero o mentiroso. Los autores comenzaron a abordar estos temas analizando tres nuevos indicadores verbales de veracidad: las complicaciones, los detalles de conocimiento público y las estrategias de falta de capacidad. Se presenta un meta-análisis de estas tres variables y se comparan los resultados con los “detalles totales”. Los sujetos que dicen la verdad dan más detalles (d = 0.28 hasta d = 0.45) y complicaciones (d = 0.51 hasta d = 0.62) y menos detalles de conocimiento público (d = -0.40 hasta d = -0.46) y estrategias de justificación (d = -0.37 hasta d = -0.50) que los que mienten. Las complicaciones resultaron ser el mejor indicador diagnóstico de veracidad. Los resultados fueron iguales en la primera entrevista en recuerdo libre y en la segunda entrevista, en la que solo se analizaba información nueva. No influyeron en los resultados cuatro moderadores: el escenario, la motivación, la modalidad y la técnica de entrevista. Como conclusión, las complicaciones parecen ser un buen indicador de veracidad aunque es necesaria más investigación. Se discuten las futuras líneas de investigación.
Keywords
Meta-analysis, Complications, Common knowledge details, Self-handicapping strategies, Bayes factorsPalabras clave
Meta-análisis, Complicaciones, Detalles de dominio público, Estrategias de falta de capacidad, Factores de BayesCite this article as: Vrij, A., Palena, N., Leal, S., and Caso, L. (2021). The Relationship between Complications, Common Knowledge Details and Self-handicapping Strategies and Veracity: A Meta-analysis. The European Journal of Psychology Applied to Legal Context, 13(2), 55 - 77. https://doi.org/10.5093/ejpalc2021a7
aldert.vrij@port.ac.ukT Correspondence: aldert.vrij@port.ac.ukT (A. Vrij).From verbal cues to deception that have been frequently examined, total details emerged as the best diagnostic cue (Amado et al., 2016). Truth tellers typically report more details than lie tellers (d = 0.55), representing a medium effect size. However, practitioners frequently tell us that variable total details is not useful to them, mainly for two reasons: 1) it is not possible to count the number of details in an interview in real time and 2) it can never be established in an individual interview how many details are required to judge somebody as a truth teller or lie teller. Vrij et al. (2017) started to address these two problems by introducing three new verbal veracity cues: complications, common knowledge details, and self-handicapping strategies. To date they have published 18 samples measuring complications, 12 samples measuring common knowledge details, and 13 samples examining self-handicapping strategies. In this article we present a meta-analysis of that research. This meta-analysis has three aims: to determine the diagnostic value of these three cues to differentiate truth tellers from lie tellers; to assess the gaps in knowledge concerning these three cues; and to encourage other researchers to examine these and other cues. Complications, Common Knowledge Details, and Self-Handicapping Strategies Complications are occurrences that affecs the story-teller and make a situation more complex (“Initially we did not see our friend, as he was waiting at a different entrance”) (Vrij, Deeb et al., 2021). Complications are thought to occur more often in truthful statements than in deceptive statements. Making up complications requires imagination but lie tellers may not have adequate imagination to fabricate these (Köhnken, 2004; Vrij, 2008). In addition, lie tellers prefer to keep their stories simple (Hartwig et al., 2007), but adding complications makes the story more complex. Complications as introduced by Vrij and colleagues differs from the unexpected complications criterion that is part of the Criteria-Based Content Analysis (CBCA) tool (Amado et al., 2016). The main difference is that in CBCA complications are necessarily unexpected occurrences, whereas this is not the case in Vrij and colleagues’ definition. Thus, when someone says that when driving from their hometown A to their holiday destination C they briefly visited town B, this visit to town B is considered a complication by Vrij and colleagues but not according to the CBCA definition. In other words, Vrij and colleagues’ definition solely focuses on ‘complexity’ without taking any unexpected elements into account. A second, less important, difference is how the coding takes place. Vrij and colleagues always apply frequency coding whereas CBCA-coders often use scales (3-point or 5-point scales) (Vrij, 2008). Frequency coding is more detailed and probably more reliable than scale coding. Common knowledge details refer to strongly invoked stereotypical information about events (“The event had an Oscars theme so everybody was dressed up”). Lie tellers are thought to report more common knowledge details than truth tellers. Truth tellers have personal experiences of an event and are likely to report these (DePaulo et al., 1996). If lie tellers do not have personal experiences of the event they report or do not have experiences of events related to the to-be-discussed event, they will draw upon general knowledge to construe the event (Sporer, 2016). Common knowledge details have never been examined before in deception research. Deception researchers have discussed scripts, without actually examining them (Köhnken, 2004; Sporer, 2016; Volbert & Steller, 2014). Scripts are different from common knowledge details. A script is a stereotyped sequence of actions that defines a well-known situation (Schank & Abelson, 1977, p. 41) (e.g., ‘John went to a restaurant. He ordered lobster. He paid the check and left’). Common knowledge details do not necessarily involve a sequence of events. Thus, the sentence ‘We spent a couple of hours at the National Museum’ classifies as a common knowledge detail but not as a script. Self-handicapping strategies refer to justifications as to why someone chooses not to provide information (“There isn’t much to say about the actual bungee jump as it took only a few moments”). A real life example occurred with Dominic Cummings, a former advisor to the British Prime Minister Boris Johnson. Cummings travelled from London to Durham during lockdown. This is what he said when he was asked whether he had discussed this trip with Johnson: “At some point during the first week, when we were both sick and in bed, I mentioned to him what I had done. Unsurprisingly, given the condition we were in, neither of us remember the conversation in any detail.” (https://inews.co.uk/news/dominic-cummings-lockdown-statement-pm-adviser-said-meant-barnard-castle-431111). For lie tellers, not having to provide information is an attractive strategy. However, they are also concerned about their credibility and believe that admitting lack of knowledge and/or memory appears suspicious (Ruby & Brigham, 1998). A potential solution is to provide a justification for the inability to provide information. Self-handicapping strategies have never been examined in deception research before. Real Time Coding A detail is a unit of information and each new piece of information counts as a detail. This means that many details can occur in a statement, far too many to count in real time. Complications and common knowledge details are clusters of details. Therefore, fewer of them occur in a statement which makes them easier to count in real time. To return to the example mentioned earlier, the sentence “Initially we did not see our friend, as he was waiting at a different entrance” contains seven details but only one complication and the sentence “The event had an Oscars theme so everybody was dressed up” contains four details but only one common knowledge detail. Someone who just listens to those two sentences will have difficulty in counting the details but should be able to spot the complication and common knowledge detail. Self-handicapping strategies are also relatively easy to spot in real time as it typically contains a statement why some information cannot be provided followed by a justification for it. Note that the coding of complications, common knowledge details, and self-handicapping strategies occurs in addition to frequency of details coding and not instead of such coding. Frequency of details coding can be further specified, for example in contextual details. Again, this would occur in addition to the coding of complications, common knowledge details, and self-handicapping strategies. For example, the sentence “We spent a couple of hours at the National Museum” includes two contextual details (a time detail – couple of hours – and a location detail – National Museum) but the entire sentence constitutes one common knowledge detail. Contextual details are typically reported more often by truth tellers than by lie tellers (Amado et al., 2016), but the way they are reported in this sentence makes it a common knowledge detail and such details are more likely to be reported by lie tellers than by truth tellers. Decision-Making in Individual Cases Most verbal deception research examines verbal cues to truthfulness, that is, verbal cues that truth tellers report more frequently than lie tellers. For example, all 19 CBCA criteria, including the variable ‘total details’, are cues to truthfulness. Only examining cues to truthfulness poses a problem for practitioners: how many details should someone report to classify as a truth teller or a lie teller? This question is impossible to answer. The number of details reported is not only dependent on veracity but also on the interviewee and situation. That is, some individuals are more talkative than other individuals and some events can be described in much more detail than other events (Nahari & Pazuelo, 2015; Nahari & Vrij, 2014; Vrij, 2016). A practitioner would be in a much stronger position to determine that an interviewee is lying if s/he records not only cues that truth tellers are more likely to report (cues to truthfulness) but also cues that lie tellers are more likely to report (cues to deceit). Examining complications, common knowledge details, and self-handicapping strategies does exactly that: it measures a mixture of cues to truthfulness and cues to deceit. Someone could be more confident that somebody is telling the truth if complications are present and common knowledge details and self-handicapping strategies are largely absent (rather than just complications present) and, vice versa, someone could be more confident that someone is lying when complications are largely absent and common knowledge details and self-handicapping strategies occur. Hypotheses Truth tellers will report more complications (Hypothesis 1) and fewer common knowledge details (Hypothesis 2) and self-handicapping strategies (Hypothesis 3) than lie tellers. The procedure applied for conducting this meta-analysis followed the APA Meta-Analysis Reporting Standard (Cooper, 2011) and a recently published meta-analysis on the verifiability approach (Palena et al., 2020). We searched the literature for empirical studies examining complications, common knowledge details and/or self-handicapping strategies and used the following inclusion criteria: (1) the study involved one interviewee rather than pairs or groups (see for studying groups, Leal et al., 2018; Vernham et al., 2020); (2) the study measured the total frequency of complications, common knowledge details, and/or self-handicapping strategies; (3) the study used the coding procedure first outlined by Vrij et al. (2017); (4) veracity was manipulated (either within-subjects or between-subjects); (5) the study could either be based on a single interview or follow the within-subjects approach as outlined in Vrij, Leal, and Fisher (2018), where the interviewee is first asked a free recall, then s/he is exposed to any manipulation (e.g., the model statement), and then asked a second free recall; (6) statements were coded manually; and (7) articles were written in English. If in the selected articles ‘total details’ was reported, we included this variable in the analyses. The first moderator was the deception scenario. This is an important moderator for applied reasons as it examines whether effects can be generalised across scenarios. We distinguished between two categories: i) trip/memorable event, when the participants discussed a trip they had made or a memorable event which was out of the ordinary, and ii) spy mission, where the participants performed a spy mission (Moderator 1). A second moderator was the level of motivation, because research has found that cues to deception are more evident in motivated rather than unmotivated senders (DePaulo et al., 2003). Building on DePaulo et al. (2003) and Suchotzki et al. (2017), we introduced two categories: (i) participants who received an incentive for their participation, such as money, university credits, a present etc., or (ii) participants who did not receive an incentive (Moderator 2). Following Palena et al. (2020), we also coded the modality of the interview on two levels: i) whether the participants were interviewed, or ii) provided a written statement (Moderator 3). Last, since several interviewing techniques have been introduced in lie detection research (e.g., model statement, Vrij, Leal, & Fisher, 2018, sketching while narrating, Vrij, Leal, Fisher, et al., 2018), we also coded whether or not any manipulation was used in the experiment (Moderator 4). Analyses showed no variability for the moderators incentive (Moderator 2) and modality (Moderator 3) since all studies included an incentive and no study involved a written statement (see Appendix C). Hence, the effect of these moderators was not explored. Search Strategies and Studies Selection We conducted the literature search in October 2020, and used the following databases: PsycINFO, PsycARTICLES, Web of Science, and Scopus. We looked for any type of work (article, review, book chapters, etc.) that included terms (“complication*” OR “common knowledge” OR “self-handicapping”, in title/abstract/keywords) and (“decept*” OR “deceit” OR “lie” OR “lying” OR “truth*”, in title/abstract/keywords) but did not include the terms (“collect*” OR “pair*”, in title/abstract/keywords). We limited our research to the psychological, social sciences, and art and humanities areas, and to sources produced from 2017 onwards. We also: i) contacted scholars who previously published articles in which complications, common knowledge details, or self-handicapping strategies were reported; ii) visited the webpages of scholars working on these types of detail; iii) searched the reference list of the selected papers; iv) searched the 2019-2020 conference programs of the European Association of Psychology and Law (EAPL), and the 2017-2020 conference programs of the American Psychology and Law Society (AP-LS), and the International Investigative Interviewing Research Group (iIIRG); v) and conducted a search on ResearchGate. The selection process was conducted by two researchers with experience in the field. Inter-rater agreement was calculated via Cohen’s k and was 1.00 (100% of agreement). Appendix A shows the illustration of the selection process via the Prisma diagram (Moher et al., 2010) and Appendix B reports a description of the included studies and reasons for the exclusion of studies. A coding protocol was applied to extract all the relevant information needed for the meta-analysis from the selected papers. The following variables were coded: (a) truth tellers’ and lie tellers sample sizes; (b) mean and standard deviation of complications, common knowledge details, self-handicapping strategies, and total details; (c) the deception scenario; (d) whether or not an incentive was provided; (e) whether the participants provided an oral or a written statement; and (f) whether or not any interviewing technique (e.g., model statement, sketching while narrating, etc.) was used. Regarding (b), the descriptives required to compute the effect sizes were obtained from three different outcome variables: i) “initial recall” – this refers to the first statement provided by interviewees who were asked to provide more than one statement, or the only statement provided by interviewees who provided only one recall; ii) “second recall” – this refers to “new” information (complications, common knowledge details etc) not already mentioned in the initial recall provided by the interviewee in a second recall; and iii) “total recall” – this refers to the sum of initial and second recall. Regarding Moderator 4 (presence of manipulation), for “initial recall” and “second recall” data, we coded each study as “manipulation present” if the interviewees were exposed to any manipulation at any of these recall stages and as “manipulation absent” if they were not. For “total recall” data, we coded manipulation as “present” if participants were exposed to any manipulation at their “initial recall”, at “second recall”, or at both (see Appendix B for more information concerning the coding of Moderator 4). Inter-rater agreement for non-categorical moderators was analysed via percentage of agreement and was 100%. Inter-rater agreement for categorical moderator was calculated via Cohen’s k and was 1.00. Effect sizes were computed as d with Cohen’s formula when the study sample sizes were equal, and Hedges’ formula when the sample sizes were unequal. We obtained Cohen’s d from the selected studies wherever possible. In all other cases, we contacted the authors to request any missing data (data requested to authors are reported in Appendix B). Cohen’s d was computed so that positive values indicate a higher frequency amongst truth tellers than amongst lie tellers. For each effect size, 95% CIs, standard error, variance, and the level of significance were computed. However, Cohen’s d is not always straightforward to interpret. For this reason, we also reported two additional statistics for the estimation of the magnitude of the effect: the probability of superiority of the effect size (PSES) and the probability of inferiority score (PIS) (Arias et al., 2020; Monteiro et al., 2018). The former is a transformation of the observed effect size as a percentile. For example, if a positive effect size represents a higher frequency of details amongst truth tellers than lie tellers, a PSES = .30 indicates that the observed effect size is greater than 30% of all possible effect sizes. PIS is the probability that truth tellers obtain a score that is lower than the mean score of lie tellers. For example, if PIS = .30, 30% of truth tellers would report an amount of detail lower than the mean score of lie tellers. The effect sizes obtained from the selected sources were analysed via standard meta-analytic procedures (Borenstein et al., 2011) via the meta-analytic software ProMeta3. All effect sizes were pooled via the inverse-variance method. All outcomes concerning the initial recall, and total detail and complications for second and total recall were pooled via a random-effects model as it allows to account both for within-studies and between-studies variances. In contrast, common knowledge details and self-handicapping strategies for second recall and total recall were pooled using the fixed-effect method. Heterogeneity was explored using the Q statistic (indicating a lack of homogeneity if significant), and the I2 statistic, which estimates what proportion of the observed variance is related to real differences in the analysed effect sizes. An I2 of 70% or more is deemed as a high difference, 50% as moderate, and 25% as low (Borenstein et al., 2011; Cooper, 2015). Moreover, we explored the standardised residuals of each study to detect possible outliers and sensitivity analyses (where one study at a time is removed) were conducted to explore the (in)stability of the results. Publication bias was explored via the trim and fill method. We also carried out meta-analyses via the Bayesian model averaging method (Gronau et al., 2017, 2020). See Appendix J. Included Studied Description One-hundred and twenty-one records were found through the database search, and three records through other sources. After removing the duplicates, 105 records were screened in their titles and abstracts. Eighty-three records did not relate to verbal credibility assessment and were thus excluded. One was excluded because, although focusing on verbal credibility assessment, it did not analyse complications, common knowledge details, or self-handicapping strategies (Leal et al., 2018), and one was excluded because it focused on pairs of interviewees (Vernham et al., 2020). The remaining 20 records were read in full to evaluate if they matched the eligibility criteria. Three of them were excluded because they did not contain new data (Vrij & Leal, 2020; Vrij, Leal, Mann, et al., 2019; Vrij & Vrij, 2020); one was excluded because it was theoretical rather than empirical (Vrij, Leal, & Fisher, 2018); one was excluded because the only cue that they examined – complications – did not occur frequently enough to be analysed leaving us with no data to report (Verigin, Meijer, Vrij et al., 2020); and one was excluded because we did not manage to obtain the required data from the authors (Verigin, Meijer, & Vrij, 2020). In the end, 14 studies were included in the meta-analysis, and all of them employed a between-subjects design for veracity (participants were either asked to tell the truth or to lie). Three articles included two independent subgroups, where one was exposed to a manipulation (e.g., the model statement) and the other was not (Vrij, Leal, Fisher, et al., 2018; Vrij et al., 2017; Vrij, Mann et al., 2020). Two studies included three recalls and four subgroups, where one subgroup was exposed to a manipulation only the first time they recalled the event, one was exposed to a manipulation only the second time they recalled the event (with a one-week delay), one was exposed to a manipulation at both times, and one at neither (see Appendix B, for an explanation concerning how we treated these groups in the analyses) (Deeb et al., 2020; Deeb et al., 2021). One article included two studies with independent samples (Vrij, Leal, et al., 2020), of which the second study included three subgroups. Also, Leal et al. (2019) and Vrij, Leal, Fisher, Mann, Jo, et al. (2019) included three subgroups. In Vrij, Leal, Deeb, et al. (2020), Leal et al. (2019), and Vrij, Leal, Fisher, Mann, Jo, et al. (2019) the three subgroups differed in their exposure (or not) to a specific manipulation technique. All subgroups of these studies were therefore independent. Appendix B reports the characteristics of all studies and specific notes for each of them, including how the independent subgroups were treated for the analyses. Complications were measured in every study, but the other variables were not (see Appendix C). In the end, we analysed the 14 articles that fit eligibility criteria. Appendix C reports main characteristics of included studies, which are marked in the reference list with an asterisk. Overall Effect Sizes Estimation Initial recall. A random-effects meta-analysis of the 17 samples related to the “frequency of total details” (N = 2,083) showed that truth tellers reported more total details than lie tellers, with a moderate effect size (Cohen, 1988), d = 0.45, 95% CI [0.32, 0.59], p < .001, PSES = .251, PIS = .326 (see forest plot in Appendix D). The meta-analysis also showed moderate heterogeneity, Q(16) = 36.07, p < .01, I2 = 55.65. When exploring the residuals of each study and their significance, one study appeared to be an outlier (Vrij, Mann, et al., 2020). A sensitivity analysis showed that the effect size ranged from d = 0.41, 95% CI [0.29, 0.53], p < .001, when the outlier study was excluded, to d = 0.48, 95% CI [0.35, 0.61], p < .001. Moderator’s effects for manipulation (k = 13 for “manipulation absent”, d = 0.44 and k = 4 for “manipulation present”, d = 0.53) and scenario (k = 13 for “past trip event”, d = 0.40 and k = 4 for “spy mission”, d = 0.63) were not significant (Table 1), indicating that neither of the two moderators had a significant effect on the frequency of total details provided by truth tellers vs. lie tellers. The funnel plot showed to be asymmetric to some degree (Appendix E), and the trim and fill method trimmed two studies. Yet, both observed (d = 0.45) and estimated (d = 0.40, PSES = .221 and PIS = .345) effect sizes were in the moderate effect size region. Table 1 Initial Recall for Total details - Moderator Analysis 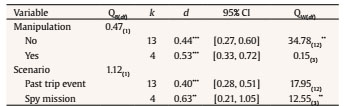 Note. A positive d indicates that truth tellers reported more details than lie tellers; CI = confidence interval; QB = heterogeneity between factors levels; QW = heterogeneity within factors levels. *p < .05, **p < .01, ***p < .001. A random-effects meta-analysis of the 18 samples for “frequency of complications” (N = 2,163) showed that truth tellers reported more complications than lie tellers, with a moderate effect size of d = 0.58, 95% CI [0.48, 0.68], p < .001, PSES = .318, PIS = .281 (Appendix D). This supports Hypothesis 1. Q statistic was not significant, Q(17) = 21.32, p = .21, and I2 = 20.25 showed low heterogeneity. Due to the lack of heterogeneity there is no need to conduct moderator analyses neither for manipulation (k = 14 absent, k = 4 present) nor for scenario (k = 14 past trip event, k = 4 spy mission). Sensitivity analyses showed that effect sizes ranged from d = 0.56, 95% CI [0.47, 0.66], p < .001, to d = 0.62, 95% CI [0.53, 0.71], p < .001, when the only outlier study (Vrij, Leal, Fisher, Mann, Deeb, et al., 2019) was excluded. The funnel plot was asymmetric (Appendix E) and three studies were trimmed. Yet, observed (d = 0.58) and estimated (d = 0.54) effect sizes were comparable. A random-effects meta-analysis on the 12 samples for “frequency of common knowledge details” (N = 1,498) showed that truth tellers reported fewer common knowledge details than lie tellers, with a moderate effect size of d = -0.40, 95% CI [-0.52, -0.27], p < .001, PSES = .221, PIS = .655 (Appendix D). This supports Hypothesis 2. There was low heterogeneity between studies, I2 = 26.91, Q(11) = 15.05, p = .18. Due to the lack of heterogeneity, there is no need to conduct moderator analyses neither for manipulation (k = 8 absent, k = 4 present) nor for scenario (all studies belonged to the past trip event category). Sensitivity analyses showed that the effect ranged from d = -0.37, 95% CI [-0.49, -0.25], p < .001 to d = -0.44, 95% CI [-0.55, -0.33], p < .001, when the only outlier study was excluded (Vrij, Leal, Fisher, Mann, Deeb, et al., 2019). The funnel plot did not show a clear asymmetry, and two studies were trimmed (Appendix E). Again, observed (d = -0.40) and estimated (d = -0.36) effect sizes were comparable. Finally, a random effects meta-analysis on the 13 samples for the “frequency of self-handicapping strategy” (N = 1,620) showed that truth tellers reported fewer self-handicapping strategies than lie tellers with a small effect size of d = -0.37, 95% CI [-0.53, -0.20], p < .001 (Appendix D). This supports Hypothesis 3. There was moderate heterogeneity between studies, I2 = 63.63, Q(12) = 32.99, p < .01. Moderator effects for manipulation (“manipulation absent” k = 9, “manipulation present” k = 4, Qbetween(1) = 0.49, p = .48) and scenario (past trip event k = 12, spy mission k = 1, Qbetween(1) = 0.68, p = .41) were not significant. Sensitivity analyses showed that the effect size ranged from d = -0.31, 95% CI [-0.44, -0.17], p < .001, when the only outlier record was excluded (Vrij et al., 2017, subgroup 2, manipulation present), to d = -0.41, 95% CI [-0.57, -0.24], p < .001. The funnel plot did not show a clear asymmetry and no study was trimmed (Appendix E). Second recall. A random-effects meta-analysis on the 17 samples focusing on “new total detail” (N = 1,658) showed that truth tellers reported more new details than lie tellers with a small effect size of d = 0.28, 95% CI [0.17, 0.39], p < .001 (Appendix F). There was low heterogeneity, I2 = 27.22, Q(16) = 21.98, p = .14. Hence, this means that there is no need to conduct any moderator analysis for manipulation (k = 6 absent, k = 11 present) nor for scenario (k = 13 past trip event, k = 4 spy mission). Further, sensitivity analyses showed that the effect size ranged from d = 0.25, 95% CI [0.16, 0.35], p < .001, when the only outlier study was excluded (Vrij, Mann, et al., 2020, subgroup 2, manipulation present), to d = 0.30, 95% CI [0.19, 0.41], p < .001. The funnel plot appeared symmetric and no study was trimmed (Appendix G). A random-effects meta-analysis on the 17 samples focusing on “new complications” (N = 1,658) indicated that truth tellers reported more new complications than lie tellers with a moderate effect size, d = 0.51, 95% CI [0.42, 0.61], p < .001, PSES = .281, PIS = .305 (Appendix F). This supports Hypothesis 1. There was no heterogeneity, I2 = 0.00, Q(16) = 13.01, p = .67; hence, no moderator analysis was conducted for manipulation (k = 6 absent, k = 11 present) nor for scenario (k = 13 past trip event, k = 4 spy mission). There were no outlier studies and the effect size ranged from d = 0.50, 95% CI [0.40, 0.60], p < .001 to d = 0.53, 95% CI [0.43, 0.63], p < .001. The trim and fill method trimmed no study and the funnel plot appeared symmetrical (Appendix G). A fixed effect meta-analysis on the 10 samples focusing on “new common knowledge details” (N = 1,149) showed that truth tellers report fewer new common knowledge details than lie tellers with a moderate effect size, d = -0.46, 95% CI [-0.58, -0.35], p < .001, PSES = .259, PIS = .677 (Appendix F). This supports Hypothesis 2. There was no heterogeneity, I2 = 0.00, Q(9) = 5.85, p = .75; hence no moderator analysis was conducted for manipulation (k = 4 absent, k = 6 present) nor for scenario (all studies belonged to the past event trip category). No study was an outlier and a sensitivity analysis showed that the effect size ranged from d = -0.45, 95% CI [-0.57, -0.32], p < .001, to d = -0.50, 95% CI [-0.62, -0.38], p < .001. One study was trimmed via the trim and fill method (Appendix G), and the observed (d = -0.46) and the estimated (d = -0.45) were almost identical. A fixed-effect meta-analysis on the 10 samples focusing on “new self-handicapping strategies” (N = 1,067) showed that truth tellers report fewer new self-handicapping strategies than lie tellers with a moderate effect size, d = -0.50, 95% CI [-0.56, -0.44], p < .001, PSES = .274, PIS = .691 (Appendix F). This supports Hypothesis 3. There was moderate heterogeneity, I2 = 55.66, Q(9) = 20.30, p < .05. There was a significant effect for manipulation, Qbetween(1) = 7.41, p < .01. Studies in the “manipulation absent” category (k = 4) obtained a smaller effect size (d = -.23, 95% CI [-.43, -.04], p < .05, Qwithin(3) = 1.58, pQwithin = .66) than those in the “manipulation present” category (k = 6, d = -.52, 95% CI [-.59, -.46], p < .001, Qwithin(5) = 11.31, p = .05). The effect of the moderator “scenario” was not significant (past trip event k = 8, spy mission k = 2, Qbetween(1) = 1.81, pQwihin = .18). There was one outlier study (Vrij, Leal, Jupe, et al., 2018). Sensitivity analyses showed that the effect ranged from d = -0.27, 95% CI [-0.39, -0.15], p < .001, when such study was excluded, to d = -0.51, 95% CI [-0.57, -0.45], p < .001. The trim and fill method showed that no study was trimmed (Appendix G). Total recall. A series of meta-analyses for “total recall” showed a pattern that was similar to that of second recall (see Appendices H and I). Truth tellers reported more unique total details and unique complications but fewer unique common knowledge details and unique self-handicapping strategies than lie tellers. Heterogeneity analyses were not significant (Table 2). Table 2 Meta-analysis for Total Recall Data  Note. 1random-effects model; 2fixed effect model. The meta-analysis showed support for all three hypotheses and revealed that truth tellers reported more complications and fewer common knowledge details and self-handicapping strategies than lie tellers. Findings were very similar for first initial recall, the ond recall (where only new information after first recall was examined), and for total recall (initial and second recalls combined). The finding that the pattern of results obtained in a first recall tends to repeat itself in a second recall should increase confidence amongst practitioners when they use these variables in a two recall interview when attempting to detect deceit. It may also indicate robustness of the findings. All effect sizes were moderate but they were somewhat larger for complications (d ranged from 0.51 to 0.62) than for common knowledge details (d ranged from -0.40 to -0.46) and self-handicapping strategies (d ranged from -0.37 to -.50). Further, the PIS indicated that a greater proportion of truth tellers would obtain the expected scores when focusing on complications (higher scores than lie tellers) than when focusing on common knowledge or self-handicapping strategies (lower scores than lie tellers). The relatively weaker results for common knowledge details and self-handicapping strategies (both cues to deceit) than for complications (cue to truthfulness) is unfortunate. The verbal deception field is in much stronger need of cues to deceit than cues to truthfulness because so few verbal cues to deceit do exist (Nahari et al., 2019). Although complications can be coded in probably most statements, common knowledge details and self-handicapping strategies do not always occur (Vrij, Granhag, et al., 2021). They are typically examined in a ‘travel’ scenario where participants report a trip they allegedly have made in the last twelve months. Making a trip is arguably a somewhat scripted activity, which makes common knowledge details more likely to occur (“We visited the famous market, after which we went to the beach. We had dinner in a Mexican restaurant”). And when the trip was not recent, it gives lie tellers a good opportunity to include self-handicapping strategies (“I cannot remember which restaurants we went to in the evenings, because we went there three months ago”). The situation is different when someone describes a unique event that just happened. It seems reasonable to suggest that lie tellers are more likely to report common knowledge details when describing a somewhat scripted event than a unique event and that they are more likely to report self-handicapping strategies when describing an event that occurred in the past as opposed to an event that occurred recently. Truth tellers may also include common knowledge details in their statements and perhaps particularly so when they do not see the relevance of describing the experience in more detail. These common knowledge details will be impossible to distinguish from those reported by lie tellers. A possible solution is to stress to interviewees that they should report every detail they can remember even the insignificant ones. An alternative solution is to expose interviewees to a model statement, an example of a detailed account (Leal et al., 2015), so that interviewees are made aware of the amount of detail they are expected to provide. A model statement has shown to be an effective method to generate information (Vrij, Leal, & Fisher, 2018). Truth tellers may also admit lack of memory when an event happened some time ago and, as a result, may include self-handicapping strategies in their statement (“I cannot remember which restaurants we went to in the evenings, because we went there three months ago”). Admitting lack of memory is a CBCA criterion and truth tellers report those more frequently than lie tellers (Amado et al., 2016). There are two differences between self-handicapping strategies and admitting lack of memory. First, admitting lack of memory becomes a self-handicapping strategy only when it is followed by a justification: In the sentence above: “… because we were there three months ago.” Thus, the sentence “I cannot remember which restaurants we went to in the evenings” would classify as admitting lack of memory in CBCA but does not constitute a self-handicapping strategy. Second, self-handicapping strategies do not just include admitting lack of memory; it also includes admitting lack of perceptual experiences. The example “There isn’t much to say about the actual bungee jump as it took only a few moments” constitutes a self-handicapping strategy of the lack of perceptual experiences type. Perhaps a distinction between these two types of self-handicapping strategies, an admitting lack of memory type and an admitting lack of experiences type, may make the difference between truth tellers and lie tellers more pronounced. That is, perhaps truth tellers are more likely to include in their statements the memory-type of self-handicapping strategies than the experience-type. This suggests that the experience-type will be the strongest veracity indicator. Complications was not only a stronger veracity indicator than common knowledge details and self-handicapping strategies, it was also a more diagnostic veracity indicator than total details. This was particularly the case in the second recall (d = 0.51 for complications and d = 0.28 for total details). The relatively low d score for total details in a second recall suggests that the finding obtained for complications (pattern of results obtained in a first recall repeats itself in a second recall) does not apply to total details to the same extent. This makes total details a more problematic cue to use for lie detection purposes than complications. A possible benefit of total details is that the cue always can be examined, because even brief statements (perhaps with the exception of ‘no comment’) always include details. Very short statements may not include complications. Whether total details emerges as a strong veracity cue in short statements is an empirical question. This may not be the case, because verbal cues to deception are more likely to occur in longer statements because words are the carriers of verbal cues to veracity (Vrij et al. 2007). It is also an empirical question whether complications emerge as a stronger veracity indicator than total details in deception scenarios other than the ones examined in this meta-analysis. All we can conclude at this stage is that complications emerged as a stronger veracity indicator than total details in the scenarios examined in this meta-analysis. The moderators did affect only the results for new self-handicapping strategies in the second recall. It means that effect sizes were mostly homogeneous across studies. Yet, this should be taken with some caution because of the (i) low number of studies and (ii) unbalanced groups (Borenstein et al, 2011). The absence of a moderator effect cannot be interpreted as evidence that interview techniques have no effect on the dependent variables (Moderator 4), because moderator analyses often have low power (Borenstein et al., 2011). To examine whether an interview technique has an effect on dependent variables someone should either analyse more studies or compare “within each experiment” an experimental (‘technique present’) condition with a control (‘technique absent’) condition. The latter is different from what happened in moderator analyses in the present meta-analysis. Here, across all samples included in the meta-analysis, ‘technique absent’ conditions were compared with ‘technique present’ conditions, but these absent and present conditions did not always belong to the same experiment. We note four limitations. First, all the available research comes from Vrij’s lab. This is not uncommon in deception research. For example, in a meta-analysis of Strategic Use of Evidence (SUE) research, Granhag was an author on every publication (Hartwig et al., 2014). It is even not uncommon in interviewing research. For example, also in a meta-analysis of the Scharff technique, Granhag was an author on every publication (Luke, 2021). Despite this, research carried out by other researchers seems essential. At present we cannot rule out that the way Vrij and colleagues operationalise and code the three variables is idiosyncratic and that this is driving the effects. The general lack of heterogeneity in the effects presented in this meta-analysis is unusual for deception research (DePaulo et al., 2003) and psychology research in general (Stanley et al., 2018). This could be due to small sample sizes (Borenstein et al., 2011, 2016). Another factor could be a lack of variance in deception scenarios in which cues have been examined. A wider spread of deception scenarios is thus welcome and the contribution of other researchers to this domain would facilitate this. A second limitation is that all studies are lab-based studies but field studies testing hypotheses seem relevant. This could be a challenge due to the difficulty in obtaining ground truth in field studies. Third, the number of studies on which this meta-analysis was based was limited. Although this is not uncommon in this field (Hartwig et al., 2014; Luke, 2021) more research is required, particularly regarding common knowledge details and self-handicapping strategies for second and total recalls as the number of included studies is insufficient. Fourth, we stated that examining complications, common knowledge details, and self-handicapping details is advantageous compared to coding total details because the former three variables can be coded in real time whereas the latter variable cannot. Note that there is yet no empirical evidence that the former three variables can be coded in real time. Several issues merit further research, such as in which types of setting complications, common knowledge details and self-handicapping strategies (1) can be examined and (2) yield the strongest effects. We already know that common knowledge details and self-handicapping strategies cannot be examined in certain situations and the search for alternative cues to deceit that occur in such settings seems urgent (Nahari et al., 2019). Another area of research is whether the three variables become more diagnostic if they are considered in relation to the type of detail they refer to. For example, truth tellers compared to lie tellers tend to include (1) more verifiable details in their statements (Palena et al., 2020) and (2) focus more on core aspects of an event (Sakrisvold et al., 2017). Are therefore complications reported in verifiable details and core events more diagnostic than complications reported in unverifiable details and peripheral events? In addition, as we already suggested above, it is worthwhile to compare how diagnostic these three variables are as veracity indicators compared to the total details variable. Researchers should examine whether complications, common knowledge details, and self-handicapping strategies indeed can be counted in real time. In our training of practitioners, we focus on complications and self-handicapping strategies and our experience is that they can be counted in real time. However, we have never formally examined this. In addition, we have never examined whether practitioners can also count common knowledge details in real time. Finally, it seems likely that new verbal veracity indicators other than complications, common knowledge details, and self-handicapping strategies do exist. The field is in particular need of cues that lie tellers report more frequently than truth tellers (cues to deceit). In that respect, although it does not constitute a new cue to deceit, separating self-handicapping strategies into two types, one that does include admitting lack of memory and another type that includes admitting lack of perceptual experiences, may be a first step. We hope this meta-analysis stimulates researchers to address these and other issues. Conflict of Interest The authors of this article declare no conflict of interest Cite this article as: Vrij, A., Palena, N., Leal, S., & Caso, L. (2021). The relationship between complications, common knowledge details and self-handicapping strategies and veracity: A meta-analysis. The European Journal of Psychology Applied to Legal Context, 13(2), 55-77. https://doi.org/10.5093/ejpalc2021a7 Funding: The time the first author spent working on this article was funded by the Centre for Research and Evidence on Security Threats (ESRC Award: ES/N009614/1). References References Appendix A Prisma Flowchart  Article Notes and Reasons for Excluded Sources 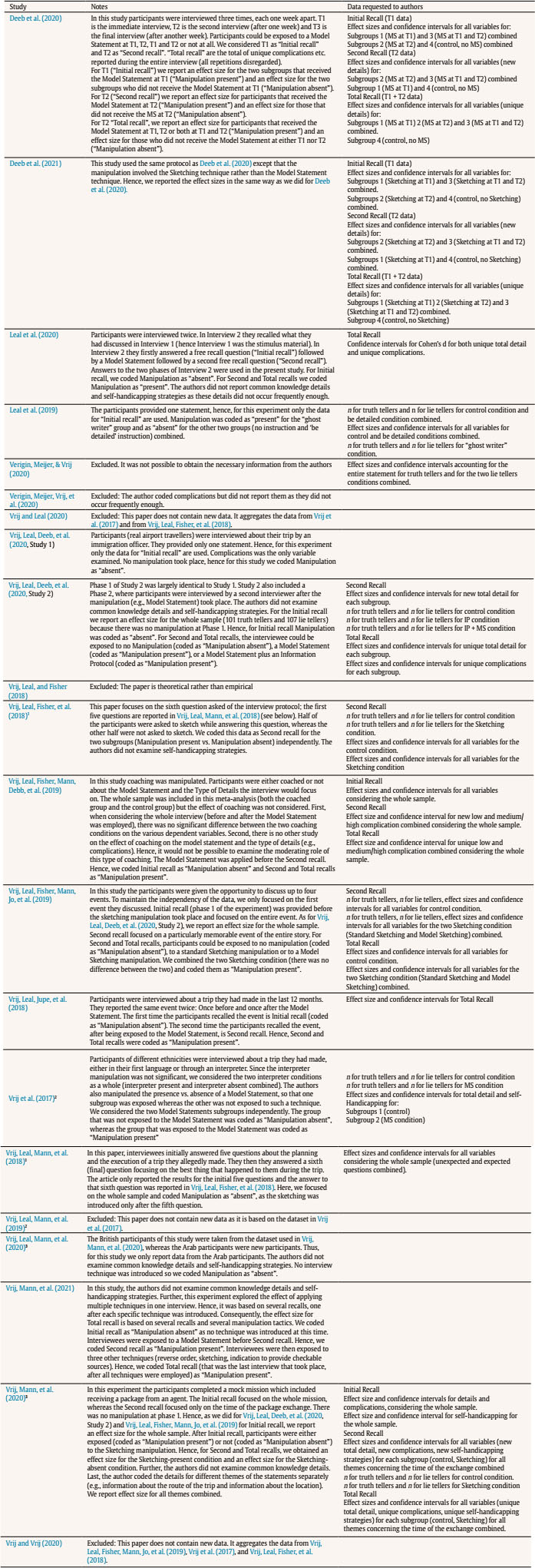 Note. Superscripts indicate that the papers were based on the same dataset (1, 2), or on a partial overlap of the datasets (3). Study Characteristics – Initial Recall 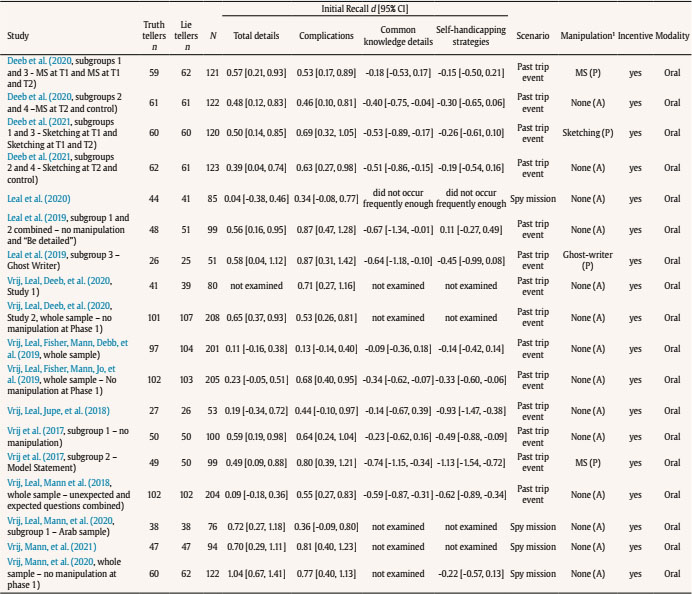 Note. 1(P) indicates that manipulation was coded as “present”, (A) indicates that manipulation was coded as absent. Study Characteristics – Second Recall 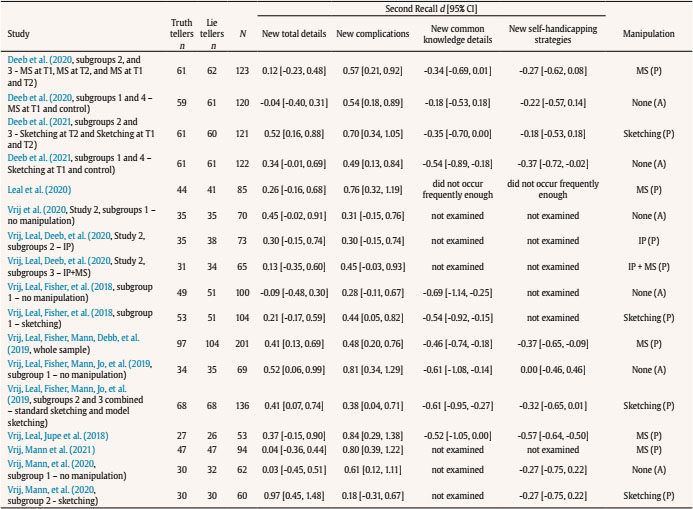 Note. 1(P) indicates that manipulation was coded as “present”, (A) indicates that manipulation was coded as absent. Study Characteristics – Total Recall 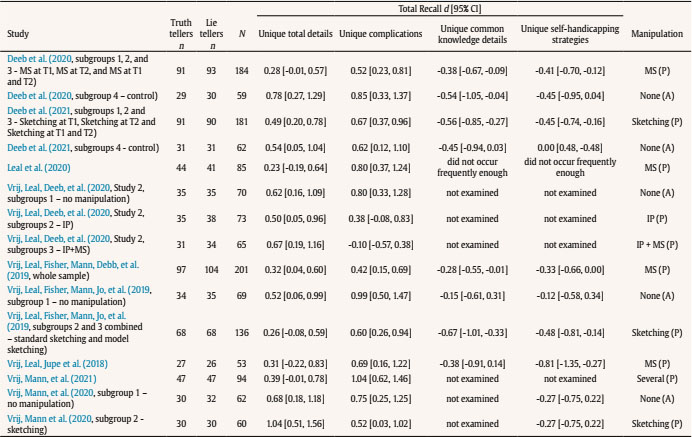 Study Characteristics – Total Recall Funnel Plots for Initial Recall Data Second Recall Data - Forest Plots Funnel Plots for Second Recall Data Total Recall Data - Forest Plots Funnel Plots for Total Recall Data There is some debate about whether the frequentist and the Bayesian approaches should be employed together. On the one hand, it has been suggested that the two frameworks might be epistemologically incompatible (Mayo, 1996, 2018). Indeed, whilst the frequentist approach makes use of conditional distributions of the data given the hypothesis, the Bayesian makes use of probability for the data as well as for the hypotheses. On the other hand, it is believed that it might be fruitful to employ both, and there are indeed examples where this has been done (Hong et al., 2013; Wu et al., 2020). Indeed, a comparison of the two frameworks can shed light on the consistency of the results when applying different methods. The merits here are that it is possible to explore two different answers to a same question, each with its own peculiarities. We carried out a Bayesian meta-analysis for the following reasons. First, with the Bayesian approach there is no need to select either a fixed-effect or a random-effects model as it accounts for model uncertainty. Hence, the Bayesian approach can be applied when there is no certainty about heterogeneity (in contrast to a random-effects model which presumes that it is non-zero), which can be particularly the case when there is no solid background to assume the presence (vs. absence) of heterogeneity. Second, it permits to explore the plausibility of our a priori choices concerning the application of either the fixed effect (for common knowledge details and self-handicapping strategies relative to second and total recalls) or random-effects (all remaining analyses) standard meta-analyses as outlined in the main text of this article after taking into account the observed data. Third, in addition to the significance testing of the global effect size obtained via the standard meta-analytic approach, a Bayesian meta-analysis returns a Bayes factor, which provides the amount of evidence in support of the alternative hypothesis (the presence of an effect) against the null hypothesis (the absence of an effect). We interpreted Bayes factors cut-offs as outlined by Jeffreys (1961): values between 1 and 3 indicate weak evidence for H1, values between 3 and 10 indicate substantial evidence for H1, values between 10 and 20 indicate strong evidence for H1, and values beyond 20 indicate very strong evidence for H1. Vice versa, values between 1/3 and 1 indicate weak evidence for H0, scores between 1/3 and 1/10 indicate substantial evidence for H0 etc. Fourth, a Bayesian approach provides a posterior distribution of the global effect size, whose utility is twofold: i) the probability of each value of the global effect size can be calculated and is shown graphically and ii) future research on the topic can use the resulting posterior distribution of both the effect size and of τ as an informative prior distribution. Therefore, any new experiment can build on previous evidence in a cumulative manner. Last, with the Bayesian approach it is possible to obtain the probability of the presence of an effect (in our case, a difference between truth tellers and lie tellers in the examined variables), rather than a dichotomic answer “significant/not significant”. We conducted a Bayesian model averaging meta-analysis (Gronau et al., 2020) and used default priors as recommended by Gronau et al. (2017): A Cauchy prior with scale 1/√2 centred at zero for the effect size µ, and an inverse-gamma (1, 0.15) prior for between studies standard deviation τ. With this procedure, four Bayesian meta-analysis models are considered: (a) a fixed-effect null-hypothesis, (b) a fixed-effect alternative hypothesis, (c) a random-effects null hypothesis, and (d) a random-effects alternative hypothesis. The four models above are obtained by fixing at zero both µ and τ (model a), only τ (model b), only µ (model c), or neither (model d). Then, an inclusion Bayes factor for the presence of an effect is obtained by contrasting the two models that predict an effect (µ ≠ 0, models b and d, H1) at the numerator of the formula to the two models that predict a null effect (µ = 0, models a and c, H0) at the denominator, with the left-hand side of the formula relating to posterior inclusion odds and the right-hand side of the formula relating to the prior inclusion odds. In essence, a Bayesian model averaged meta-analysis: i) can quantify the evidence in support for the presence of an effect while accounting for uncertainty relative to choosing a fixed effect or a random-effects meta-analysis, ii) can provide evidence for the presence/absence of between-studies heterogeneity, and iii) returns posterior odds for each of the four models once the observer data are taken into account. The higher a posterior odd, the more plausible a specific model. We had 12 meta-analyses, the result of three interviews (first recall, second recall and total recall), and four dependent variables (total details, complications, common knowledge details, and self-handicapping strategies). When conducting the standard meta-analyses, we opted (a priori) for a fixed-effect model when analysing common knowledge details and self-handicapping strategies concerning “second recall” and “total recall” (four analyses), and a random-effects model for the remaining eight analyses. However, especially when research on a specific topic is still in its development, it is not always possible to rule out uncertainty concerning the correct model selection (fixed-effect vs. random-effects). A series of Bayesian model averaging meta-analyses was conducted to explore such uncertainty and to evaluate our choices. The results showed that we chose, a priori, the model with higher posterior probabilities in five out of 12 cases. The seven cases where the analyses showed that the model we chose was less probable than its alternative (Table J1, superscript 1) concerned: i) complications in initial and second and total recall, ii) total details in second and total recall, iii) common knowledge details in initial recall, and iv) self-handicapping strategies in second recall. For i), ii), and iii) the fixed-effect model obtained higher posterior probability than the random-effects model we chose. However, Table J2 shows that the Bayes factor for the presence of heterogeneity ranged from BF10 τ = 0.25 to BF10 τ = 0.79, indicating only weak to moderate evidence for the absence of heterogeneity. Due to this uncertainty, a model averaging analysis is particularly appropriate. For iv) the random-effects model was more plausible (≈96.7 probability) after observing the data than the fixed-effect model (≈1.6% probability) we chose. In this case, there was strong evidence for the presence of heterogeneity (BF10 τ = 61.26). Table J1 Posterior Model Probabilities for the Outcome Variables  Note. 1Indicates that the posterior probability of the model we selected (fixed-effect vs. random-effects) was lower than that of the model we did not select. For example, for the meta-analysis concerning new total details (second recall) we ran a random-effects standard meta-analysis, but the posterior model probabilities indicate that a fixed-effect model was the most plausible (≈61% probability) after having taken into account the observed data than the random-effects model (≈38% probability). IR = Initial recall, SR = Second recall, TR = Total recall. Table J2 Effect Size Estimates, Standard Deviations, 95% Credible Intervals, and Bayes Factors 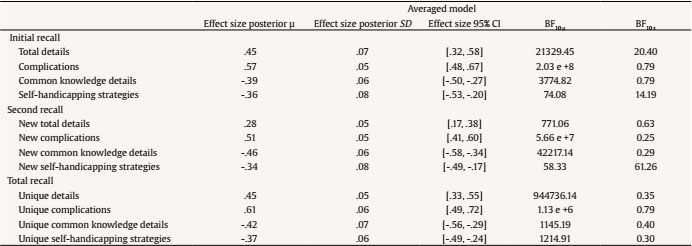 Concerning the presence of an effect, Table J2 shows very strong to extreme support for H1 for the four outcome variables (total details, complications, common knowledge details, and self-handicapping strategies), indicating that there is evidence for the hypothesis that such variables can discriminate truth tellers from lie tellers (H1). Put differently, the data were more likely under the alternative hypothesis than under the null hypothesis to a large extent, supporting Hypotheses 1 to 3. Table J2 also shows that complications obtained the highest Bayes factors. On the one hand, the results of this Bayesian meta-analysis reflect the conclusions obtained via the frequentist framework (Table J2). First, complications, common knowledge details, and self-handicapping strategies can discriminate truth tellers from lie tellers, as the presence of an effect was always more likely than the lack of it. Second, via the Bayesian meta-analysis, complications emerged as a stronger veracity indicator than the other two variables, as the Bayes factor analyses show (Table J2). On the other hand, results concerning heterogeneity were less clear-cut. The Bayesian framework found the posterior probabilities of the examined models generally supporting the lack of between-study variance. Indeed, after observing the data, model b (τ fixed at 0) received higher posterior probability than model d (τ ≠ 0) in most cases- except for self-handicapping strategies in initial and second recall. Yet, as Table J2 shows, the Bayes factors of τ were mostly inconclusive, indicating that at this stage it is difficult to draw any conclusion concerning the degree of between-study variance. In this regard, the Bayesian analysis reported here further strengthens the idea that future studies are needed to explore more in depth why the analysed studies seemed to show low heterogeneity, and whether this is actually the case. For example, futures studies could compare the results of different meta-analysis models obtained by varying the prior distribution of τ. Notwithstanding this, it is possible that the results obtained here are due to method invariance across experiments, as all studies come from Vrij’s lab and imply a consistent coding system and a shared research design. In conclusion, it is essential to understand why the selected studies showed no heterogeneity, as well as to explore the external validity of the obtained results, by answering questions as: Do complications, common knowledge details and self-handicapping strategies still work in scenarios that are different from those included in this meta-analysis? Is the lack of heterogeneity due to method invariance and to the fact that all studies come from the same lab or to other reasons? And, lastly, do the conclusions obtained here apply to real-life material? We hope that future studies will shed light on the potential of the complications approach. |
Cite this article as: Vrij, A., Palena, N., Leal, S., and Caso, L. (2021). The Relationship between Complications, Common Knowledge Details and Self-handicapping Strategies and Veracity: A Meta-analysis. The European Journal of Psychology Applied to Legal Context, 13(2), 55 - 77. https://doi.org/10.5093/ejpalc2021a7
aldert.vrij@port.ac.ukT Correspondence: aldert.vrij@port.ac.ukT (A. Vrij).Copyright © 2026. Colegio Oficial de la Psicología de Madrid





 PDF
PDF e-PUB
e-PUB CrossRef
CrossRef JATS
JATS Print
Print Send
SendEMAIL ALERT
The European Journal of Psychology Applied to Legal Context is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License








