


Mapping Details to Elicit Information and Cues to Deceit: The Effects of Map Richness1
[Mapeando los detalles para obtener informaci├│n e indicios de enga├▒o: los efectos de la riqueza del mapa]
Haneen Deeb1, Aldert Vrij1, Sharon Leal1, Mark Fallon2, Samantha Mann1, Kirk Luther3, and Pär A. Granhag4
1University of Portsmouth, United Kingdom; 2ClubFed LLC, United States; 3Carleton University, Canada; 4University of Gothenburg, Sweden
https://doi.org/10.5093/ejpalc2022a2
Received 7 April 2021, Accepted 18 November 2021
Abstract
Investigators often use maps in forensic interviews to verify a route that was taken by a suspect to obtain additional information, and to assess credibility.
We examined the effects of the level of map richness on the elicitation of information and cues to deceit. A total of 112 participants completed a mock secret mission and were asked to tell the truth (to a friendly agent) or to lie (to a hostile agent) about it in an interview. In phase 1 of the interview, all participants provided a verbal free recall of the mission. In phase 2, half of the participants were given a detailed map that included all street names and landmarks of the city where they completed the mission (zoomed in to 80%), and the other half were given a less detailed map that included the names of only major streets and landmarks (zoomed in to 60%). All participants were asked to verbally describe the mission and the route taken while sketching on the map.
Compared to lie tellers, truth tellers provided more location, action, temporal, and object details and complications in phase 1, and new person, location, action, and object details and complications in phase 2. Map richness did not have an effect on the amount of information elicited and had an equal effect on truth tellers and lie tellers.
This initial experiment in this research area suggests that investigators do not have to worry about the exact level of map detailedness when introducing maps in interviews.
Resumen
Los investigadores utilizan a menudo mapas en las entrevistas forenses para verificar el camino seguido por un sospechoso para obtener más información y para valorar la credibilidad.
Analizamos los efectos del nivel de riqueza del mapa en la obtención de información e indicios de engaño. Un total de 112 participantes simularon participar en una misión secreta, pidiéndoseles que, en una entrevista, dijeran la verdad (a un agente amistoso) o mintieran (a un agente hostil) sobre la misión. En la fase 1 de la entrevista se recabó de los participantes un recuerdo libre de la misión y en la fase 2 se facilitó a la mitad un mapa detallado con los nombres de las calles y puntos de referencia de la ciudad en la que habían llevado a cabo la misión (ampliado hasta el 80%) y a la otra mitad se les dio un mapa menos detallado solo con los nombres de las calles y puntos de referencia principales (ampliado hasta el 60%). Se pidió a los participantes que describieran verbalmente la misión y el camino seguido al tiempo que la proyectaban en el mapa.
En comparación con los participantes instruidos para mentir, los instruidos para contar la verdad daban más detalles sobre ubicación, acciones, tiempo y objetos y complicaciones en la fase 1 y detalles nuevos sobre personas, ubicaciones, acciones y objetos y complicaciones en la fase 2. La riqueza del mapa no influía en el volumen de información producida y tenía el mismo efecto, tanto en los instruidos para contar la verdad como una mentira.
Este primer experimento en esta área de investigación sugiere que los investigadores no deben preocuparse por el nivel exacto de detalle del mapa cuando introduzcan estos en las entrevistas.
Keywords
Deception, Maps, Sketch, Visuospatial, RichnessPalabras clave
Enga├▒o, Mapas, Esquema, Visoespacial, RiquezaCite this article as: Deeb, H., Vrij, A., Leal, S., Fallon, M., Mann, S., Luther, K., and Granhag, P. A. (2022). Mapping Details to Elicit Information and Cues to Deceit: The Effects of Map Richness1. The European Journal of Psychology Applied to Legal Context, 14(1), 11 - 19. https://doi.org/10.5093/ejpalc2022a2
haneen.deeb@port.ac.uk Correspondence: haneen.deeb@port.ac.uk (H. Deeb).Investigators are increasingly using sketches when interviewing suspects to elicit information and to detect deception (Dando, Wilcock, & Milne, 2009; Deeb, Vrij, Hope, Mann, Granhag, et al., 2018). Empirical evidence has shown that sketches are indeed effective for eliciting accurate information and cues to deceit, understanding suspects’ verbal reports, formulating interview questions, and reducing memory contamination and suggestive questioning (Dando, 2013; Eastwood et al., 2018; Katz & Hershkowitz, 2010; Mac Giolla et al., 2017). There are different sketch formats that can be used, one of which is map sketching. Maps are often used in forensic and intelligence-gathering interviews (M. Fallon, personal communication, November 9, 2018; S. Kleinman, personal communication, June 27, 2016). The main aims of map sketching are to verify a route that was taken by the suspect, to obtain information experienced by the suspect en route, and to determine the credibility of the suspect (Marlow & Hilbourne, 2011). However, it is not clear if maps with varying detail elicit different amount of information and cues to deceit. In the current experiment, we examined whether a detailed map that includes all street names and landmarks of a city elicit more information and cues to deceit between truth tellers and lie tellers than a non-detailed map that includes the names of only major streets and landmarks. The Use of Sketches to Elicit Information and Cues to Deceit There has been a recent surge of research on sketches, which found that in truth tellers sketching while narrating produces more verbal details than just narrating (Dando, Wilcock, & Milne, et al., 2009; Eastwood et al., 2018; Leins et al., 2014). Sketching mentally reinstates the context of an interviewee’s experience and thus enhances recall (Dando et al., 2011; Mattison et al., 2015). Sketching is also more time consuming than narrating, so by reinstating the context and allowing more time for retrieval the interviewee can further activate their memory of activities relevant to the event and thus recall more information (Butler et al., 1995; Collins & Loftus, 1975; Yantis & Meyer, 1988). Moreover, sketching is a visual output and therefore more compatible with visually experienced events than just narrating, so it improves visual and spatial recall (Schacter & Badgaiyan, 2001). Further, sketching typically leads to the provision of spatial information as the interviewee must situate each person or object in a location on the sketch. In contrast, verbal reports do not require interviewees to spontaneously locate persons and objects (Vrij et al., 2020). Interviewees may be asked to either sketch and then to narrate or to sketch while narrating (Dando, Wilcock, & Milne, 2009; Eastwood et al., 2019; Marlow & Hilbourne, 2011). Findings in the deception literature generally overlap for those two methods of introducing sketches and show that truth tellers provide more verbal details than lie tellers (Izotovas et al., 2020; Vrij et al., 2020). As truth tellers report an experienced event, whereas lie tellers fabricate at least some parts of the reported event, truth tellers’ verbal reports of the event are likely to be richer than lie tellers’ verbal reports (Amado et al., 2015). Also, lie tellers may be less willing to provide information than truth tellers out of fear that the information gives leads to investigators that they can check (Nahari et al., 2014). Accordingly, truth tellers report more verbal details and complications than lie tellers in sketch-based interviews (Mac Giolla et al., 2017; Vrij et al., 2012; Vrij et al., 2020). In the current research, participants were asked to sketch (on a map) while narrating. The type of details examined in their verbal reports were person, location, action, temporal, and object (PLATO) details. We chose to examine these details for several reasons. First, PLATO details are details naturally provided by truth tellers who have experienced an event (e.g., Eastwood et al., 2018; Harvey et al., 2017). Second, PLATO details were not examined extensively in deception research, but the few studies that tested them have shown promising results. Location and temporal details were examined as part of the Reality Monitoring approach (Johnson & Raye, 1981) and the Criteria-Based Content Analysis (Volbert & Steller, 2014), and they were more common in truth tellers’ reports than in lie tellers’ reports (Amado et al., 2015; Gancedo et al., 2021; Oberlader et al., 2016). A few sketch-based studies also showed that truth tellers reported more PLAT (person, location, action, temporal) details than lie tellers, and some of these effects seem to last even after a time delay (Izotovas et al., 2020; Vrij et al., 2010; Vrij et al., 2020). We were interested in understanding if PLATO details would also be elicited in interviews involving maps. Third, sketch-based research in the deception field has not yet examined the four PLAT details in combination and none has examined object details. This is a shortcoming given that all these five types of detail are informative and may provide leads in investigations. Therefore, we decided to add object details to the set of examined details. It is important to understand which of these details are elicited when specific interview techniques are employed, and if these details differ between truth tellers and lie tellers. For example, in real life interviews, investigators may want to elicit specific information (e.g., person details) about the reported event for the purpose of obtaining more information or cues to deceit. Empirical evidence that guides them to the specific interview techniques that elicit person details may aid them with the investigation. Fourth, researchers started calling for the examination of more verbal cues to detect deception (Nahari et al., 2019). Relying on more than one diagnostic cue that has received empirical support to make veracity decisions would help investigators make more informed decisions than relying on only one cue. For example, research has shown that total details and complications are both related to deception (Amado et al., 2015; Vrij, Palena et al., 2021). Looking at them in combination could perhaps result in more accurate decisions concerning an interviewee’s veracity than looking at them individually (Hartwig & Bond, 2014). Based on previous findings in deception research, we predicted that truth tellers would provide more PLATO details in their verbal reports than lie tellers (Warmelink et al., 2013; Vrij, 2008). We based our predictions for object details on the eyewitness literature which has shown that (truthful) eyewitnesses include these details in their reports (Dando et al., 2011; Hope et al., 2014). There is no theoretical reason why truth tellers would not provide object details more than lie tellers as they do for the other details, so our hypotheses were in the same direction for all PLATO details. Examining details is useful for information-gathering purposes (more details indicate more information) but less suitable for lie detection purposes. The problem is that the number of details someone provides cannot be counted in real time in interviews when prompt decisions about credibility must be made. Complications, however, is a verbal cue that can be counted in real time in interviews. A complication is an occurrence that affects the storyteller and makes a situation more complex (e.g., “Initially we did not see our friend, as he was waiting at a different entrance”). Complications can be counted in real time because it is not a type of detail but a cluster of details that become a complication due to their combined meaning. For example, the statement “She could not see the road mentioned in the instructions and so returned back to check” contains seven details, but the combined meaning of these seven details results in one complication. Previous research has shown that truth tellers include more complications in their verbal reports than lie tellers, both with and without sketching (Vrij, Leal, Fisher, et al., 2018; Vrij, Leal, Jupe, et al., 2018). As truth tellers have genuinely experienced the reported event, they are likely to add complications in their report. For lie tellers, adding complications makes the story more complex and goes against their strategy to keep their stories simple (Hartwig et al., 2007), so they often avoid providing complications (Vrij et al., 2017; Vrij et al., 2020). Lie tellers also believe that reporting complications sounds suspicious (Maier et al., 2018), and they tend to avoid saying things they believe sound suspicious (Ruby & Brigham, 1998). As researchers advocate the utilisation of multiple cues to aid veracity judgments (Hartwig & Bond, 2011, 2014; Nahari et al., 2019), we also examined complications in the current experiment. Does the Use of Maps Elicit Information and Cues to Deceit? Maps are similar to sketches as they comprise a visuospatial modality that helps with reinstating the context and that is compatible with how the event was originally encoded. Thus, maps should serve as mnemonics similar to sketches and strengthen truth tellers’ memory. The cues found in maps (e.g., street names) should help truth tellers recall more information about the event. According to the spreading activation theory (Collins & Loftus, 1975), memory is a network that is activated by similar cues. The cues on the map would trigger memory of relevant information which in turn enhances recall. However, this enhanced performance would not apply to lie tellers who provide minimal information in interviews. We therefore expect maps to enhance differences between truth tellers and lie tellers. This is supported by an experiment that found that simply marking on a sketch of a target location enhanced lie detection (Roos af Hjelmsäter et al., 2014). In line with previous findings, we expected that truth tellers would provide more details than lie tellers, and that detailed maps would elicit more details than non-detailed maps. Detailed maps should facilitate truth tellers’ memory more than non-detailed maps as they would serve as a stronger cue for enhancing recall by reinstating the context (Dando, Wilcock, & Milne, et al., 2009). However, the richness of details in the map should not affect lie tellers’ reports. Lie tellers prefer to keep their accounts simple (Strömwall & Willén, 2011), so their responses to the detailed and non-detailed maps should not differ. Even if they attempt to use cues found in detailed maps (e.g., landmarks) to make their stories more plausible, lie tellers would not report stories that are similar in quality to those of truth tellers (Verigin et al., 2020) as they would not want the investigator to verify their accounts which may potentially give their lies away (Nahari et al., 2014). Hypotheses The experiment and hypotheses were pre-registered on https://osf.io/uqjcb/?view_only=2614825f4dbc4d28997116959db39664.2 We predicted that truth tellers will provide more PLATO details and complications than lie tellers (Hypothesis 1; Veracity main effect). We also expected participants presented with a detailed map to provide more PLATO details and complications than those presented with a non-detailed map (Hypothesis 2; Map Richness main effect). Further, we predicted a Veracity × Map Richness interaction effect. Truth tellers provided with a detailed map will provide more PLATO details and complications than truth tellers provided with a non-detailed map, whereas map richness will have no effect on lie tellers (Hypothesis 3; Veracity × Map Richness interaction effect). We also explored truth tellers’ and lie tellers’ self-reported strategies to appear convincing during the interview. Previous research has shown that truth tellers and lie tellers employ different strategies, regardless of whether they provide a verbal report or a sketch (Hartwig et al., 2010; Hines et al., 2010; Vrij et al., 2020). We expected similar differences to emerge between truth tellers and lie tellers when they use maps. Participants and Design The sample size was determined from an a priori power analysis of the multivariate main effects and interactions. The power analysis (conducted via G*Power software) revealed that at least 102 participants are required to obtain an 80% statistical power, an alpha level of .05, and a medium to large effect size (f2 = .09), which is the effect found in previous deception research involving visuospatial tasks (Vrij, Leal, Jupe, et al., 2018). A total of 112 university students and staff members (58% females; Mage = 24.96 years, SDage = 10.41) were recruited at the University of Portsmouth. A total of 68% were Caucasian, 15% Asian, 11% African, 2% Arab, 1% Hispanic, and 3% of mixed ethnicity. Participants received course credits or £10 for taking part in the experiment. The experiment received ethics approval from the institutional ethics committee, and it complied with the ethical standards set by the Declaration of Helsinki. A 2 (Veracity: truth teller, lie teller) × 2 (Map Richness: detailed, non-detailed) between-participant design was used. The dependent variables were PLATO (person, location, action, time, object) details and complications. We also measured Sense of Direction with the intention of including it as a covariate in the analysis as people differ in their spatial abilities. The sample included 56 truth tellers, of which 29 were in the detailed map condition, and 56 lie tellers, of which 27 were in the detailed map condition. Procedure After participants signed the consent form, they were asked to read an instructions sheet informing them about the mission they would carry out in the vicinity of the department of psychology. Each participant had to collect a CD that supposedly included information on acids and chemicals from an Agent 1 (a confederate) and deliver it to an Agent 2 (another confederate) at two different points. Participants took one of two routes, and for each route the locations of Agents 1 and 2 differed. Agent 1 waited inside either a train station (first route) or a bus station (second route) and Agent 2 waited in a café in one of two university buildings.3 We varied the routes to test for any effects of route length on participants’ responses, although we tried to choose the routes to include a similar number of landmarks.4 Participants were randomly and equally distributed in each route. The confederates and routes did not affect participants’ responses. Before they left for their mission, participants were given a directions sheet that described the route they needed to take to meet Agents 1 and 2, as well as the return route to the department. Participants were given an envelope in which they would place the CD before delivering it to Agent 2 so that the CD remains undetected. It was emphasised that the participants should not appear suspicious and should make sure nobody was following them. The experimenter also gave participants a tracking device—which they were instructed to hide—so that the experimenter could check that the participants took the correct route.5 However, participants were informed that the purpose of the device was for the experimenter to make sure the mission was running well. After returning to the department, participants were randomly allocated to the truth teller or lie teller condition and were informed that they would be interviewed by a friendly agent (for truth tellers) or a hostile agent (for lie tellers). Truth tellers were instructed to tell the complete truth about the mission to the friendly agent. Lie tellers needed to lie to the hostile agent about (i) the locations where they collected and delivered the package, (ii) the agent from whom they collected the package, (iii) the agent to whom they delivered the package, and (iv) the content of the package. These instructions reflect those used by Vrij, Mann, et al. (2021). All participants were told that if they were convincing, they would be entered in a draw to win one of three prizes up to £150. In reality, all participants were entered in the draw. Participants were given as long as they needed to prepare for the interview. The interview. One of two research assistants, blind to the experiment hypotheses and veracity conditions, interviewed participants in two phases. All interviews were audiotaped. In Phase 1, participants were asked: Could you please tell me in as much detail as possible everything about the mission including what you did and saw en route from the moment you left this building to the moment you returned back. You may take as long as you need to respond. After participants provided a free recall, the interviewer left the room for five minutes. Participants were then randomly allocated to the detailed or non-detailed map condition. For Phase 2, the interviewer entered the room again and gave the following instructions: I need to get a complete picture of what happened and to ensure you did not miss any details. Before I ask for your account again, please take a few moments to picture in your mind each part of the mission. That is, the route to meet Agent 1, the exchange between you and Agent 1, the route to meet Agent 2, the final exchange between you and Agent 2, and the route back to the department. Think about where you were and what you saw, heard, felt and smelled each time. Take a moment to think about all your senses during the mission and then please let me know when you have done that. Once participants indicated they were ready, the interviewer presented the map and asked the following: Now please tell me in as much detail as possible everything you did and saw en route from the moment you left this building to the moment you returned back, but while doing this, mark and sketch on this map everything you could see en route, including when you met the agents, and everything you did throughout the mission. You may use additional pieces of paper if you like, and you may take as long as you need to respond. Participants sketched on either a detailed map or a non-detailed map of the city while they verbally described the mission. The map used was extracted from maps.google.com website. The difference in the zoom scale between the detailed and the non-detailed map was determined such that more street names would appear in the detailed maps than in the non-detailed maps. This resulted in the detailed map being “zoomed in” to 80% and the non-detailed map being “zoomed in” to 60%. Maps were printed in colour on A3 paper. Only four participants asked for another piece of paper (these were A3 white blank papers). Post-interview questionnaire. After the interview, participants completed a post-interview questionnaire via Qualtrics. They rated on 7-point scales (1 = not at all to 7 = definitely) (a) their motivation to appear convincing; (b) the extent to which they thought they were believed by the interviewer; (c) the extent to which they thought they will be entered in the prize draw; (d) the difficulty of the map task; (e) the richness of the map, the extent to which they thought the map helped them (f) clarify what they needed to communicate and (g) remember information they would not have otherwise remembered, the extent to which the map hindered them from providing a (h) convincing and (i) detailed account; (j) the extent to which they thought the route taken was long and (k) their familiarity with the route taken. On an 11-point percentage scale, participants rated the extent to which they were truthful. They were also asked open questions about (a) the strategies they used to appear convincing during the interview, (b) mobile apps or other strategies they used while navigating their way during the mission, and (c) the number of years they have been living in the city. Lastly, all participants completed a demographics questionnaire about their age, gender, and ethnicity. As participants might differ in their survey spatial abilities which may affect their performance on the map task (Afrooz et al., 2018; Burte & Montello, 2017; König et al., 2019), the Santa Barbara Sense of Direction Scale (Hegarty et al., 2002) was used. It is a 15-item scale (1 = strongly disagree to 7 = strongly agree) with proven reliability between .80 and .89 (Davies et al., 2017; Montello & Xiao, 2011). Examples of the scale items include ‘I am very good at giving directions’, ‘I enjoy reading maps’, ‘I very easily get lost in a new city’, etc. Coding All verbal interviews were transcribed and coded separately for Phase 1 and Phase 2. Details were coded as person, location, action, temporal, or object (PLATO) details. Person details involved the mention and physical descriptions of persons (e.g., ‘The agent had dark hair’ includes three person details). Location details referred to static places such as streets, rooms, and tunnels and their descriptions and to directions (e.g., ‘...inside the university building near the big hall to the right...’ includes seven location details). Action details were verbs such as walked, entered, turned, passed, etc. Temporal details denoted time such as then, afterwards, Wednesday, afternoon, etc. Object details referred to non-static objects such as car, phone, and food and their descriptions (e.g., ...he had a CD with a white envelope’ includes three object details). In Phase 2, new PLATO details (i.e., PLATO details not mentioned during Phase 1) were highlighted. The transcripts were divided into five contexts (route to Agent 1, meeting with Agent 1, route to Agent 2, meeting with Agent 2, return route to the department). These five contexts were selected because they differed on PLATO details, and were based on the interview questions and on the instructions received by lie tellers prior to the interview. Any PLATO details that were repeated in a single context were coded only once. We decided to divide the transcripts into contexts, because repeated details in a single interview do not necessarily reflect the same content when they appear in different contexts (see Leal et al., 2018, for a similar coding scheme). For example, a participant may mention a car en route to Agent 1 (first context) and another car en route to Agent 2 (third context). Although ‘car’ is a repeated detail in this interview, it does not refer to the same car and would thus be coded twice. We did not test differences in PLATO details between contexts as no hypotheses were formulated on the contexts. The first author and a second coder—both blind to participants’ veracity and map conditions—coded the transcripts independently for PLATO details. The second coder was trained and given practice transcripts to code. Feedback was provided for each coded transcript until the coder was able to code independently. The first author coded all the transcripts, and the second coder coded 25% of the transcripts. Inter-rater reliability analyses were computed using the intra-class correlation (ICC) coefficient (single measures scores). Hallgren (2012) reported that inter-rater reliability is poor for ICC values less than .40, fair for values between .40 and .59, good for values between .60 and .74, and excellent for values between .75 and 1. Inter-rater reliability was excellent for PLATO details in Phase 1 (ICC = .87) and for new PLATO details in Phase 2 (ICC = .76). Two other coders—both blind to participants’ veracity and map conditions—coded the transcripts for complications. An example of a complication is ‘I forgot to do up my coat and I felt shivery’ or ‘I looked around and the main hall was empty, so I thought that they must be in the next bit’. One of the coders coded all the transcripts and the other coder coded 20 transcripts. Both coders have extensively coded complications previously. Inter-rater reliability was excellent for complications in Phase 1 (ICC = .90) and for new complications in Phase 2 (ICC = .89). Participants’ strategies as reported in the post-interview questionnaire were coded by the first author. Categories were formulated based on participants’ responses. Similar responses were grouped together in a single category, and each category was labelled to describe one strategy (see Table 2). When the same response could fit in more than one category, it was allocated to those corresponding categories. To assess inter-rater reliability, a second coder coded all participants’ responses based on the corresponding categories generated by the first author. Inter-rater agreement was substantial, Cohen’s κ = .72. Table 1 Descriptive and Inferential Statistics of Items in the Post-Interview Questionnaire  Note. All variables were measured on a 7-point scale, except for truthfulness which was measured on a percentage (0-100%) scale. Table 2 Frequency of Truth tellers and Lie tellers Who Employed a Strategy to Appear Convincing 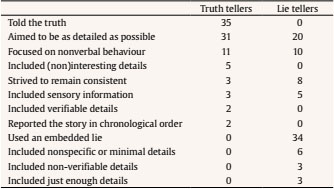 Post-Interview Questionnaire Analyses Motivation, believability, draw entry, map task, route length, familiarity with the route. A MANOVA was conducted with veracity and map richness as factors, and participants’ motivation to be believed and their perceptions on the (a) extent to which the interviewer believed them; (b) entry into the prize draw; (c) difficulty of the map task; (d) richness of the map; extent to which the map helped them to (e) clarify what they wanted to communicate and (f) remember information; extent to which the map hindered them from providing (g) a convincing account and (h) a detailed account; (i) length of the mission route; and (j) familiarity with the route as dependent variables. The analysis revealed significant multivariate effects of veracity, Pillai’s trace = .37, F(11, 98) = 5.22, p < .001, η2 = .37, and map richness, Pillai’s trace = .21, F(11, 98) = 2.42, p = .011, η2 = .21. The veracity × map richness interaction effect was not significant, Pillai’s trace = .09, F(11, 98) = 0.83, p = .610, η2 = .09. We include in Table 1 the dependent variables that showed significant veracity effects at the univariate level. Truth tellers were significantly more motivated than lie tellers and were more likely to think that the interviewer believed them and that they will be entered in the draw. As for the map richness main effect, participants who received a detailed map (M = 4.73, SD = 1.98) perceived greater map richness than those who received a non-detailed map (M = 2.96, SD = 1.60), F(1, 108) = 26.88, p < .001, η2 = .20. Truthfulness and embedded lies. A two-way ANOVA was conducted with veracity and map richness as factors and participants’ truthfulness as the dependent variable. As Table 1 shows, a significant main effect of veracity emerged with truth tellers being significantly more truthful than lie tellers. The other effects were not significant (p ≥ .572). Strategies used. The most frequently reported strategy among truth tellers (see Table 2) was to tell the truth and among lie tellers was to tell an embedded lie (truthful information within an otherwise false account). Both truth tellers and lie tellers aimed to provide a detailed account and to focus on non-verbal behaviour (e.g., eye contact, appearing confident). Lie tellers also strived to remain consistent throughout the interview (e.g., a lie teller mentioned trying to memorise details prior to the interview so as to not provide contradictions) and to include sensory information (e.g., what they saw, heard and smelled). A few lie tellers preferred to keep their stories simple and to include just enough details to appear believable. Length of residence in the city. Participants have on average lived in the city for 4.71 years (SD = 8.58), but no differences in length of residence emerged among the veracity and the map richness conditions (all ps ≥ .272). Only 28% used a map app to navigate their way during the mission. All of them used a Google map except for three who used an Apple map. Santa Barbara Sense of Direction Scale. The ratings on the negative items of the Santa Barbara Sense of Direction Scale (SBSOD) were reversed and the average score was computed for each participant. The scale reliability was .847, which aligns with previous reliability scores for this scale. When testing the assumptions of the multivariate analysis of covariance (MANCOVA), the assumption that the factors and the covariate should be independent (that is, SBSOD scores should be equal across veracity and map richness conditions) was violated. SBSOD scores differed across the map richness conditions, F(1, 108) = 5.07, p = .026, with the detailed map condition (M = 4.50, SD = 0.96) scoring higher on SBSOD than the non-detailed map condition (M = 4.10, SD = 1.01). This means that SBSOD scores were not randomly distributed across the map richness conditions so they shared variance with only one condition and did not remove noise that was unrelated to the conditions (Miller & Chapman, 2001). Therefore, it was not appropriate to run a MANCOVA, and we refrained from using SBSOD as a covariate in the main analyses. Hypotheses Testing Phase 1. We conducted a MANOVA with veracity as the factor and PLATO details and complications in Phase 1 as the dependent variables. We did not include map richness as a factor because the map task was introduced in Phase 2. A significant veracity multivariate effect emerged, Pillai’s trace = .41, F(6, 105) = 12.19, p < .001, η2 = .41. As Table 3 shows, truth tellers provided significantly more PLATO details and complications than lie tellers, except for person details. Table 3 Descriptive and Inferential Statistics for PLATO Details and Complications as a Function of Veracity in Phase 1  To corroborate the frequentist analyses, we also ran Bayesian analyses to test the likelihood of the data under the null hypothesis and the alternative hypothesis. Bayes factors (BF10) between 1 and 3 indicate weak evidence, between 3 and 20 indicate positive evidence, between 20 and 150 indicate strong evidence, and above 150 indicate very strong evidence for the alternative hypothesis, whereas Bayes factors between 1 and 0.33 indicate weak evidence, between 0.33 and 0.05 indicate positive evidence, between 0.05 and 0.0067 indicate strong evidence, and below 0.0067 indicate very strong evidence for the null hypothesis (Jarosz & Wiley, 2014). A Bayes factor close to 1 means no evidence can be derived from the data for either the null or the alternative hypothesis. The prior probability distribution for each model was 0.20, a default uniform prior that is distributed equally across models (Wagenmakers et al., 2018). As Table 3 shows, complications received strong evidence and PLATO details received very strong evidence for the alternative hypothesis, except for person details which received weak evidence for the alternative hypothesis but positive evidence for the null hypothesis. Phase 2. A veracity × map richness MANOVA on new PLATO details and complications in Phase 2 revealed a significant multivariate effect of veracity, Pillai’s trace = .13, F(6, 103) = 2.52, p = .026, η2 = .13. No significant multivariate effects emerged of map richness, Pillai’s trace = .09, F(6, 103) = 1.59, p = .157, η2 = 0.09, or of veracity × map richness, Pillai’s trace = .08, F(6, 103) = 1.54, p = .173, η2 = .08. As Table 4 shows, truth tellers provided more new PLATO details and complications than lie tellers. The Bayes factors indicated positive evidence for the differences between truth tellers and lie tellers on new PLATO details and complications except for new temporal details for which evidence could not be concluded for either the alternative or the null hypothesis (BF10 was close to 1). Table 4 Descriptive and Inferential Statistics for New PLATO Details and Complications as a Function of Veracity and Map Richness in Phase 2  Regarding the models that included only the map richness effect or the veracity × map richness interaction effect, positive evidence emerged for the null hypothesis over the alternative hypothesis for new temporal details and new complications (0.22 ≤ BF10 ≤ 0.28). For the map richness effect, there were also stronger effects for the null hypothesis for new person details (BF10 = 0.29) and new object details (BF10 = 0.20). For all other details in the two models, the data could not support the alternative or the null hypothesis. Overall, Hypothesis 1 that predicted a veracity main effect for PLATO details and complications was partially supported in each interview phase, but Hypotheses 2 and 3 that predicted a map richness main effect and a veracity × map richness interaction effect respectively were not supported. We found that maps elicited more new information among truth tellers than lie tellers, but that map richness did not have an effect on eliciting information and cues to deceit. It seems that truth tellers reinstated the context to the same extent when both map layouts were used, and they were able to report more information than lie tellers. The results imply that non-detailed maps are as effective as detailed maps for eliciting information and cues to deceit. We can only speculate why the detailed and non-detailed maps elicited null effects in terms of eliciting information and cues to deceit. We used two levels of detail, 60% zoomed in and 80% zoomed in. Perhaps the difference between the two layouts was too small to elicit any effects. In addition, large veracity effects already emerged in Phase 1, so maps had little room to improve upon in Phase 2. Finally, participants were already acquainted with the map of the navigated area so even a non-detailed map may have triggered recall for truth tellers and lie tellers (who used embedded lies). An unfamiliar route may thus elicit more differences between map formats, a question for future research to answer. We found differences between truth tellers and lie tellers in PLATO details and complications. The findings on complications replicate previous findings in verbal and sketch-based interviews (Vrij et al., 2017; Vrij et al., 2020; Vrij, Palena, et al., 2021). Truth tellers provided more location, action, and object details than lie tellers in both interview phases. Differences in temporal details emerged only in Phase 1 of the interview when participants provided a free recall, whereas differences in person details emerged only in Phase 2 of the interview after a map was presented. The findings on person, location, and action details are consistent with sketch-based research showing that truth tellers provided more of these details in their verbal reports than lie tellers (Izotovas et al., 2020; Vrij et al., 2012; Vrij et al., 2020). This may be explained by lie tellers’ unwillingness to provide precise descriptions, particularly of persons, because they fear that this may implicate them. That is, they may fear that investigators could ask them who these other people are so that they could interview them. This is not a concern for truth tellers. Truth tellers reported more person details than lie tellers only after a map was employed. Although we cannot conclude that the map resulted in this effect as we did not have a control condition where only a free recall was obtained, it was previously demonstrated that in a follow up interview truth tellers reported more person details than lie tellers when a sketch—but not when a free recall—was requested (Vrij et al., 2020). This suggests that should an investigator want information about people involved in the reported event, the use of visuospatial modalities may elicit such information and differentiate truth tellers from lie tellers. The pattern of results for temporal details did not support our hypothesis. The order with which the free recall and the map were presented may have affected the elicitation of temporal details among truth tellers. Perhaps providing a map before—rather than after—a free recall may be more beneficial for truth tellers to report temporal (and possibly other PLATO) details. The map may trigger memory traces of the reported event which would activate other memory traces (Collins & Loftus, 1975) and thus allow truth tellers to add more information in the subsequent free recall. Future research may examine how the order of instructions may affect differences between truth tellers and lie tellers. That location, action, and object details and complications occurred more frequently among truth tellers than lie tellers in both interview phases suggests that these details are prevalent among truth tellers, regardless of the interview technique used or the interview phase. This finding sheds new insight on object details which were not examined previously. Hence, PLATO details, particularly location, action, and object details, seem promising in differentiating truth tellers and lie tellers. The finding also adds to our confidence in the utilisation of these cues (as well as complications) across contexts for lie detection purposes. Whereas these cues were elicited in diverse interviews that involved sketches (e.g., Vrij et al., 2020), interpreters (e.g., Vrij et al., 2017), and borders (Vrij et al., 2019), among others, these findings seem to also generalise to map interviews. The examination of different and new types of details is advocated by deception researchers to enhance lie detection opportunities (Nahari et al., 2019; Vrij, 2019). Therefore, PLATO details may be added to the cues currently tested in the deception field (e.g., complications, total details). As the effect sizes were medium to large in the current experiment (see Tables 3 and 4), PLATO details seem to enhance the detectability of differences between truth tellers and lie tellers. Future research may examine other interview techniques that enhance the elicitation of these specific details. The finding that maps elicited new information, particularly amongst truth tellers, aligns with research showing that varying questions in a follow-up interview elicits new details among truth tellers (Fisher et al., 2013; Kontogianni et al., 2020). It is worthwhile to examine whether other map modalities would elicit similar findings. Research underway in our lab is currently examining the effects of printed maps (as used in the current experiment) and self-generated maps (sketched by participants) on truthful and false reports. We did not find support for our veracity × map richness interaction effect hypothesis. Perhaps the non-detailed map, which used a 60% zoom in, was too detailed to function as a non-detailed map and perhaps more so because the participants were familiar with the area denoted on the map. Therefore, different maps than the ones used in this experiment may have resulted in differences between a detailed and a non-detailed map. In the current experiment, we used Google maps because they are widely used in the West. Almost all participants who mentioned using a map app during the mission reported using a Google map and were thus familiar with this map layout. This implies that in real interviews in the West, interviewees would be acquainted with Google maps and are thus able to read them when introduced in the interview. Future research may examine different map layouts. For example, some tourist maps include pinned photos of landmarks in a city. These photos may serve as memory cues (Katz et al., 2006; Lee, 2019) and assist participants, particularly truth tellers, in providing more new information compared to a map that does not include such photos. Truth tellers’ and lie tellers’ verbal strategies differed in the current experiment which reiterates previous findings (Hartwig et al., 2010; Hines et al., 2010; Verschuere et al., 2020). Although both groups reported that they provided detailed accounts, this strategy was mainly used by truth tellers (aside from the ‘told the truth’ strategy). Lie tellers employed a variety of strategies, including providing consistent and simple reports and using embedded lies. Lie tellers usually provide consistent reports to appear more believable, and they keep their reports simple so that they do not give leads to the investigator (Deeb, Vrij, Hope, Mann, Leal, et al., 2018; Granhag & Strömwall, 1999; Hartwig et al., 2007). Lie tellers also use embedded lies to keep their story close to the truth and thus avoid providing new fabrications that they may later forget (Leins et al., 2014). Our results imply that even when using embedded lies, lie tellers were still not able to provide a similar quantity and quality of details as truth tellers in their reports. This corroborates previous findings showing that embedded lies are of poorer quality than completely truthful reports (Verigin et al., 2020). The post-interview questionnaire showed that participants were generally familiar with the area they navigated as they had been living there for a few years; however, familiarity did not differ between truth tellers and lie tellers. Familiarity with a setting has been shown to eliminate verbal differences between truth tellers and lie tellers and those who are generally familiar with a setting (truth tellers and lie tellers alike) are more likely to provide details about it (Deeb, Granhag, et al., 2018; Prestopnik & Roskos-Ewoldsen, 2000). In the current experiment, although truth tellers and lie tellers were familiar with the navigated area, they still differed on the examined verbal cues, which provides further support for the efficiency of PLATO details and complications for the purpose of detecting deception. Future research may manipulate the effects of familiarity on PLATO details and complications in map interviews. We expect the differences between truth tellers and lie tellers to become more pronounced the more unfamiliar they are with the navigated area. The current research examined one interview technique to elicit information and cues to deceit. Recently, deception researchers have started recommending the use of a combination of interview techniques in practice which seems effective for eliciting information and cues to deceit (Vrij, Mann, et al., 2021). The use of a combination of a detailed map and other mnemonics, such as context reinstatement, the timeline technique (Hope et al., 2013), reverse order recall (Fisher & Geiselman, 1992), or a Model Statement (Vrij et al., 2017), may further enhance differences between truth tellers and lie tellers. A combination of mnemonics may be particularly useful in map interviews when focusing on specific activities such as precise locations on the map where significant activities may have happened. Future research may address these questions. In sum, we demonstrated that accounts that are rich in PLATO details and complications are likely to be truthful (even when not all of these cues are found in a single statement). We also showed that detailed and non-detailed maps were equally effective for eliciting information and cues to deceit. This implies that different map layouts will help investigators understand suspects’ accounts and make decisions concerning the investigation. This is handy, because investigators may in real time use any map available in the interview setting which in turn saves them time, a major resource in real life forensic interviews (Horgan, 2014). Investigators would not have to worry about the richness of an available map or about printing a richer map in order to make better veracity decisions. Given the widespread use of maps by investigators, deception researchers are encouraged to further examine their efficacy. Conflict of Interest The authors of this article declare no conflict of interest. Notes 1 The data for this study will be made available on the public repository of the University of Portsmouth (https://researchportal.port.ac.uk/portal/en/datasets/search.html) following acceptance for publication. 2 The hypothesis pre-registered on Open Science Framework as Hypothesis 2 should have been the Veracity main effect and should have read as: “Truth tellers will provide more details than lie tellers.” 3 Five confederates acted as Agent 1 or Agent 2. The location of the confederates (in each of the four locations) was manipulated. Each confederate interacted on average with 37 participants. Two MANOVAs with the confederates posing as Agent 1 and the confederates posing as Agent 2 as factors revealed no significant effects of confederates on PLATO details and complications provided in Phase 1 or Phase 2, all Pillai’s trace ≤ .35, all ps ≥ .160, all η2 ≤ .08. 4 One of the routes was 0.6 miles long and the other was 1.1 miles long. Participants’ self-reports in the post-interview questionnaire confirmed that they found the longer route to be actually longer, F(1, 110) = 21.76, p < .001, η2 = .17. However, two MANOVAs with Route as factor revealed no significant differences between routes on the number of PLATO details and complications provided at Phase 1, Pillai’s trace = .06, F(6, 105) = 1.05, p = .399, η2 = .06, or Phase 2, Pillai’s trace = .05, F(6, 105) = 0.92, p = .487, η2 = .05. 5 Ten participants did not follow the exact routes as instructed, because they either got lost or preferred to take a shortcut. However, the number was equal for lie tellers and truth tellers (n = 5 in each group), so that should not have affected the results. Removing these cases from the main analyses did not change the results, so we kept them in the analyses. Cite this article as: Deeb, H., Vrij, A., Leal, S., Fallon, M., Mann, S., Luther, K., & Granhagd, P. A. (2022). Mapping details to elicit information and cues to deceit: The effects of map richness. The European Journal of Psychology Applied to Legal Context, 14(1), 11-19. https://doi.org/10.5093/ejpalc2022a2 References |
Cite this article as: Deeb, H., Vrij, A., Leal, S., Fallon, M., Mann, S., Luther, K., and Granhag, P. A. (2022). Mapping Details to Elicit Information and Cues to Deceit: The Effects of Map Richness1. The European Journal of Psychology Applied to Legal Context, 14(1), 11 - 19. https://doi.org/10.5093/ejpalc2022a2
haneen.deeb@port.ac.uk Correspondence: haneen.deeb@port.ac.uk (H. Deeb).Copyright © 2026. Colegio Oficial de la Psicología de Madrid





 PDF
PDF e-PUB
e-PUB CrossRef
CrossRef JATS
JATS Print
Print Send
SendEMAIL ALERT
The European Journal of Psychology Applied to Legal Context is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License








