


Verbal Cues to Deceit when Lying through Omitting Information: Examining the Effect of a Model Statement Interview Protocol
[Las señales verbales del engaño cuando se miente mediante omisión de información: análisis del efecto de un protocolo de entrevista Model Statement]
Sharon Leal1, Aldert Vrij1, Haneen Deeb1, Jennifer Burkhardt1, Oliwia Dabrowna1, and Ronald P. Fisher2
1University of Portsmouth, UK; 2Florida International University, USA
https://doi.org/10.5093/ejpalc2023a1
Received 14 November 2021, Accepted 22 July 2022
Abstract
Background/objectives: Practitioners frequently inform us that lying through omitting information is relevant to them, yet this topic has been largely ignored by verbal lie detection researchers. Method: In the present experiment participants watched a video recording of a secret meeting between three people. Truth tellers were instructed to recall the meeting truthfully, and lie tellers were instructed to pretend that one person (John) was not there. Participants were or were not exposed to a Model Statement during the interview. The dependent variables were ‘total details’ and ‘complications’. Results: Truth tellers reported more complications than lie tellers but lie tellers reported more details than truth tellers. The Model Statement resulted in more complications and details being reported. The Veracity x Model Statement interaction effect was not significant. In terms of self-reported strategies, the main veracity difference was that truth tellers were more inclined to ‘be detailed” than lie tellers. Discussion: We discuss the atypical finding (most details reported by lie tellers) and ideas for future research.
Resumen
Antecedentes/objetivos: Con frecuencia los profesionales nos informan que la mentira basada en la ocultación de información es relevante para ellos, si bien quienes investigan la detección de mentiras verbales apenas han prestado atención a este tema. Método: Los participantes en este experimento vieron una grabación en vídeo de una reunión secreta entre tres personas. A unos participantes se les instituyó para que recordaran de verdad el vídeo (sujetos sinceros) y a otros que fingiesen que una persona (John) no estaba allí (sujetos mentirosos). Los participantes fueron sometidos, o no, a una entrevista Model Statement. Se tomaron como variables dependientes los “detalles totales” y las “complicaciones”. Resultados: Los sujetos sinceros daban cuenta de más complicaciones que quienes mentían, aunque estos daban más detalles que los primeros. Las declaraciones basadas en una entrevista Model Statement contuvieron más complicaciones y detalles. La interacción entre los factores veracidad (sujetos sinceros vs. mentirosos) x entrevista Model Statement (sí vs. no) no fue significativa. Teniendo en cuenta las estrategias autoinformadas, la principal diferencia en veracidad era que quienes decían la verdad tendían más a “ser detallistas” que los que mentían. Discusión: Se discuten las implicaciones de este resultado atípico (que los que mentían daban más detalles), así como para las nuevas líneas de la futura investigación.
Keywords
Truth teller, Lying through omissions, Complications, Total details, Strategies to appear convincingPalabras clave
Persona que dice la verdad, Mentira mediante omisiones, Complicaciones, Detalles totales, Estrategias para parecer convincenteCite this article as: Leal, S., Vrij, A., Deeb, H., Burkhardt, J., Dabrowna, O., & Fisher, R. P. (2023). Verbal Cues to Deceit when Lying through Omitting Information: Examining the Effect of a Model Statement Interview Protocol. The European Journal of Psychology Applied to Legal Context, 15(1), 1 - 8. https://doi.org/10.5093/ejpalc2023a1
Correspondence: sharon.leal@port.ac.uk (S. Leal).People can lie in several ways. The most frequent type of lie people tell is an outright lie: making a statement the person considers to be untrue (DePaulo et al., 1996). Somebody who denies having visited a particular shop in the afternoon but falsely claims to have been at home at that time is telling an outright lie. Also, most deception research paradigms focus on this type of lie. Examples are to report a fake holiday (Monaro et al., 2021), to lie about their identity in a mock border control interview (Akehurst et al., 2018), or to lie about their activities during the last 30 minutes (Nahari, 2018). Another type of lie is through deliberately omitting relevant information (DePaulo et al., 1996). Someone who truthfully describes details of a meeting she attended but deliberately leaves out the presence of one particular person in that meeting is lying through omitting information. Although such a statement classifies as a lie, all the person says might be entirely truthful. Practitioners attempting to detect lies in investigative interviews frequently inform us that such lies (lying through omitting information) are relevant to them, yet such lies have been largely ignored by verbal lie detection researchers. In the present experiment we aimed to fill this gap. The Strategic Use of Evidence (SUE) tool is a verbal veracity assessment tool suitable to detect lying through omitting information. SUE relates to comparing a statement with evidence (Granhag & Hartwig, 2015). In SUE, interviewers encourage interviewees to discuss their activities during the time of interest without the interviewers revealing to the interviewees the evidence they possess. For example, in response to the question “What did the interviewee at lunch time?” the interviewee may truthfully describe details about having lunch on a bench in a park with another person, whilst deliberately leaving out an encounter with a third person during that lunch. An investigator who has surveillance evidence of that encounter now might suspect that the interviewee is lying through omission. However, SUE can only be used if independent evidence is available, which is not always the case. If independent evidence is unavailable investigators employing verbal lie detection tools have no option other than to focus on the statement, which may be entirely truthful when someone lies through omitting relevant information. Leal et al. (2020) examined whether the truthful information lie tellers report when lying through omitting information contains verbal cues that they are lying. To our knowledge this was the first lying-through-omissions experiment that focused on verbal cues. Recently, Dando and Ormeron (2020) introduced a lying-through-omission paradigm (lying about the presence and involvement of an individual in an incident) but their experiment did not focus on veracity cues (it examined the extent to which interviewees ‘leak’ this information) and their sample did not include truth tellers. Leal et al. examined total details and complications. Total details is the total amount of information someone provides. A complication is an occurrence that affects the story-teller and makes a situation more difficult (“Initially we did not see our friend, as he was waiting at a different entrance”; Vrij et al., 2020). Total details and complications reveal veracity when individuals lie through fabricating information with truth tellers typically reporting more details (Amado et al., 2016; Gancedo et al., 2021) and more complications (Vrij et al., 2021) than lie tellers. These findings can be explained via the strategies truth tellers and lie tellers often employ in interviews: whilst truth tellers are inclined to tell it all, lie tellers are inclined to keep it simple (Colwell et al., 2006; Hartwig et al., 2007; Strömwall, et al., 2004). Although in Leal et al. (2020) truth tellers and lie tellers did not differ in the number of details they reported, a significant effect for complications emerged: truth tellers reported more complications than lie tellers. The information covered in complications is often not about key aspects of the activities that someone describes, and the story can be well understood without reporting the complications (Vrij et al., 2018). If lie tellers want to keep their stories simple, they may be reluctant to report complications. Another reason why lie tellers may be reluctant to report complications is that they believe that adding complications makes a statement sound suspicious (Maier et al., 2018). Lie tellers tend to avoid saying things they believe sound suspicious (Ruby & Brigham, 1998). The absence of a statistically significant effect for total details in Leal et al. (2020) goes against the typical finding obtained in lies based on fabrications research that truth tellers report more details than lie tellers. This suggests that lies through omissions may reveal fewer speech related veracity cues than lies based on fabrications. This would not be surprising because the information lie tellers provide when they lie through omitting information is entirely truthful. The presence of an effect for complications in Leal et al. replicates the findings obtained in lies based on fabrications research that truth tellers report more complications than lie tellers (Vrij et al., 2021). It suggests that veracity cues emerge even when lie tellers lie through deliberately omitting relevant information. Model Statement To encourage interviewees to provide more information in interviews, researchers have developed a Model Statement (Leal et al., 2015). A Model Statement is an example of a detailed account about a topic unrelated to the investigation (Leal et al., 2015). Exposure to a Model Statement raises expectations amongst interviewees about how much information they need to provide (Ewens et al. 2016). It typically leads to more information than an instruction to provide all details someone can remember (Vrij et al., 2018). A Model Statement is an example of how much information someone is expected to provide and Vrij et al. (2018) suggested that examples are easier to follow than instructions. Since a Model Statement raises expectations to provide more information amongst both truth tellers and lie tellers, a Model Statement typically results in a similar amount of additional new details reported by both veracity groups (Vrij et al., 2018). There is evidence that a Model Statement enhances the differences in complications truth tellers and lie tellers report (Vrij, Leal, et al., 2017). Leal et al. (2020) used a standard Model Statement interview protocol in which an initial free recall was followed by a Model Statement, followed by a second free recall. Leal et al. found that the number of complications was a veracity indicator in the second recall after the Model Statement but not in the first recall before the Model Statement. However, since they did not manipulate the Model Statement factor, it is unknown whether the Model Statement caused the effect. The current lying-through-omitting-information experiment extends Leal et al.’s (2020) experiment in two important ways. First, Model Statement was included as a factor in the experimental design. This enables us to examine whether a Model Statement enhances differences in complications between truth tellers and lie tellers. Second, we explored the strategies truth tellers and lie tellers reported to have used. This enables us to examine whether the ‘tell it all’ and ‘keep it simple’ strategies also occur in lying through omitting information scenarios. Hypotheses We tested the following two pre-registered hypotheses: truth tellers will report more complications than lie tellers (Veracity main effect, Hypothesis 1) and the Model Statement present conditions will result in more new details than the Model Statement absent conditions (Hypothesis 2). We will explore whether the Model Statement increases the number of new complications reported, particularly in truth tellers (Veracity x Model Statement interaction effect). This is the link to the pre-registration: https://osf.io/4jz5m Ethics Prior to the research, a favourable ethical review decision was given by the relevant ethics committees of the university and funder (SHFEC 2020-071). Participants The experiment was carried out entirely online. This enabled us to recruit not only a typical student/staff sample but also a sample of non-students/staff. This additional subsample is relevant because practitioners often ask whether results with student samples can be generalised to other populations. A G*Power analysis revealed that we needed to recruit at least 120 participants (n = 30 per cell) to ensure enough power (90%) and a large effect size (d = 0.9), based on previous similar research in the deception detection area (e.g., Leal et al., 2018; Vrij et al., 2019). Seventy-two students and staff from the University and another 79 participants from outside the University were recruited. These two subsamples differed from each other in gender, χ2(1, 150) = 5.21, p = .022, age, F(1, 149) = 33.94, p < .001, ethnic background, χ2(8, 151) = 26.89, p = .001, and education, χ2(10, 151) = 30.68, p = .001. Since we did not predict any participant status (students/staff vs. non-students/staff) related effects we introduced participant status as a covariate rather than a factor in the statistical analyses. See Appendix 1 for the results when participant status was introduced as a factor. In the students/staff sample, 23 were male and 48 were female (one missing value). Their average age was M = 23.90 (SD = 7.61). The mode score of education was A-levels (n = 30) and this was the highest level of education for 43% of the students/staff. Most participants in the students/staff sample (n = 33) reported to be White British; other participants were Black British (n = 11), White European (n = 9), Asian (n = 8), African (n = 2), Black European (n = 1), or mixed (n = 8). In the non-students/staff sample, 13 were male and 66 were female. Their average age was M = 33.62 (SD = 12.14). The mode score of education was BA/BSc (n = 36) and this was the highest level of education for 59% of the non-students/staff. Most participants in the non-students/staff sample (n = 56) reported to be White British; other participants were White European (n = 7), Asian (n = 5), Arab (n = 2), African (n = 2), mixed (n = 3), or other (n = 4). Procedure Students/staff were recruited via online advertisements and the university staff and student portals. Non-students/staff were recruited via social media and word of mouth. The experiment was carried out online and participants were given £15 for taking part. Around 24 hours before taking part in the experiment, participants were emailed the participant information sheet and consent form. During the experiment, which took place online via Zoom, participants were first told that they would act as a special agent for the government. In that role they would witness an undercover body camera footage of a covert meeting from an agent who infiltrated a terrorist cell. They were asked to view this footage carefully and try to remember it because they would be interviewed about it later on by a security official. The camera footage showed a meeting amongst three individuals in which they discussed the logistics of making an explosive device. There were 25 verbal and physical complications present in the footage (for example, disagreements between the three individuals, meeting being interrupted by someone knocking the door). The meeting was secretly taped by a female undercover agent (the fourth person present) with a body camera hidden in her necklace. She was introduced by the group leader as Yulia from the Ukraine group and considered trustworthy by the leader of the group. Yulia did not contribute to the discussion in the meeting and the three other individuals did not spot the hidden camera. Yulia was present during the entire meeting. The video recording was shown via screen share from the experimenter. After watching the video recording participants were randomly allocated to a truth teller (n = 76) or lie teller (n = 75) condition and a Model Statement absent (n = 75) or Model Statement present (n = 76) condition. Truth-tellers were informed that they will be interviewed by a friendly agent about the video recording they had seen and that they should truthfully recall all aspects of that footage when asked. Lie tellers were informed that they recognised another key participant in that meeting (one of the three individuals) as being a fellow undercover agent (named ‘John’). They were told that the person interviewing them could not be trusted to know that this fellow agent was also present. When recalling the meeting, the participant should therefore protect that agent by omitting that he (‘John’) was also present in the meeting. Specifically, they were instructed to say that, rather than three other individuals being present in the meeting, there were only two other individuals present. Lie tellers therefore did not need to invent any details about what they saw in the video recording. All they needed to do is not to mention John. They were thus asked to lie through omitting information. This means that truth tellers were in an advantageous position in terms of recalling details and complications because they could talk about John whereas lie tellers could not. To control for this, all details and complications truth tellers gave related to John were not included in the data analysis when testing the hypotheses. Both truth tellers and lie tellers were given as much time to prepare as they wished. They were informed that it is important to convince the interviewer that they are telling the truth and that if the interviewer believes them they would be entered into a draw to win a cash prize of up to £150. They were warned that if they do not convince the interviewer, they would not be entered into the draw but had to write a statement about their mission. In reality, no one had to write a statement and all participants were entered into the draw. We did not record the preparation time they took, because we would not know what they would do in that time period. However, no participant took more than approximately ten minutes preparation time. Once participants indicated to the experimenter that they were ready, they were given the pre-interview questionnaire to fill in via Qualtrics. Apart from items about background characteristics (gender, age, ethnic background, and highest level of education), participants were asked to rate their thoroughness of preparation via three items: 1 (shallow) to 7 (thorough); 1 (insufficient) to 7 (sufficient); and 1 (poor) to 7 (good). The answers to the three questions were averaged (Cronbach’s alpha = .92) and the variable is called ‘preparation thoroughness’. Participants were also asked whether they thought they were given enough time to prepare themselves with the following question: ‘Do you think the amount of time you were given to prepare was: 1 (insufficient) to 7 (sufficient). Finally, participants were asked how motivated they were to perform well during the interview on a 5-point scale ranging from 1 (not at all motivated) to 5 (very motivated). After completing the pre-interview questionnaire, participants were invited to a separate zoom breakout room. Both the interviewer and the participant had their cameras off to enhance the ecological validity of the experiment. We have been told by several intelligence agencies that in real life, for security reasons, online interviews often happen with the video switched off. Alternatively, interviews take place via the telephone where there is also no video. The interviewer recorded the conversation, using the ‘record’ option in Zoom. The interviewer first said: “I understand that you recently saw undercover body camera footage from an agent who infiltrated a terrorist cell. Please describe in as much detail as possible everything that happened during that footage from the moment it started to the moment it finished.” We label this initial recall Phase 1. The interviewer then excused themselves for a few seconds before returning to the call. The interviewer then said: I am sorry but I’m going to have to ask you to tell me once more about everything that happened. Once again, could you please describe in as much detail as possible, everything that happened during the footage from the moment it started to the moment it finished?” (Model Statement absent condition). In the Model Statement present condition, the interviewer said: I am sorry but I’m going to have to ask you to tell me once more about everything that happened. Once again, could you please describe in as much detail as possible, everything that happened during the footage from the moment it started to the moment it finished? But before doing so I would like to play you an example of how many details I would like you to include in your response. The example I will play is a so called ‘Model Statement’ as it gives you an idea of a detailed response to a question. After listening to the example, I would like you to be that detailed in your response, okay?” The interviewer then played the audiotaped Model Statement used by Leal et al. (2015). It was a 1.30-min long detailed account of someone attending a Formula 2 motor racing event. After the participants completed the second recall (labelled Phase 2) they were invited back into the experimenter’s room (via the Zoom ‘breakout rooms’ option) and sent the link to the post-interview questionnaire (created via Qualtrics). In the post-interview questionnaire, rapport with the interviewer was measured, because rapport is an important motivator for a productive interview (Brimbal et al., 2019). It was measured via the nine-item Interaction Questionnaire (Vallano & Schreiber Compo, 2011). Participants rated the interviewer on nine characteristics, such as smooth, bored, engrossed, and involved, using 7-point scales ranging from 1 (not at all) to 7 (extremely). Cronbach’s alpha = .87. Participants also rated what they thought the likelihood was that they would be winning the prize draw using a 7-point Likert scale from 1 (not at all likely) to 7 (very likely), and the extent to which they told the truth in the interview on an 11-point Likert scale ranging from 0% to 100%. Participants in “the Model Statement present condition rated two more statements: the Model Statement made me realise I had to ‘say more’ than I had planned and The Model Statement made me realise I had to ‘say less’ than I had planned”. Answers were given on 7-point Likert scales ranging from 1 (not at all) to 7 (totally). After completing the post-interview questionnaire, participants were given details on how to obtain payment and were then debriefed. Coding Details and Complications The Zoom recordings were transcribed and the transcripts were used for coding. One coder, blind to the Veracity condition, was taught the coding scheme by the first author who had more than ten years of experience in coding detail. A detail is defined as a non-redundant unit of information. For example, the following statement has nine details: “The body camera was worn by someone called Yulia, who knocked on a blue door. The door had a gold letterbox.” In Phase 2 only new details were coded. A second coder coded a random sample of 50 transcripts. Inter-rater reliability between the two coders, using the two-way random effects model measuring consistency, was very good (single measures ICC = .83). The first coder was then given her codings of the truthful statements and asked to highlight all details mentioned about the physical characteristics and actions of the undercover agent John. These details were then subtracted from the total number of details reported. We did this because lie tellers were instructed not to mention John in their recalls and otherwise would have a disadvantage in terms of reporting details. We did not correct for the things John said. Leaving his verbal contribution out of describing the meeting would result in describing a conversation that made no sense. To recall a conversation that made sense lie tellers thus had to pretend that John’s verbal utterances were made by someone else (something they actually did; see self-reported strategies findings in the Results). One coder, experienced in coding complications, coded the complications in all transcripts. A complication is an occurrence that affects the storyteller and makes a situation more difficult (Vrij et al., 2020). Examples of complications are: (a) “There was a knock at the door from the neighbour that they ignored”; (b) “They were expecting another guy but he could not make it”; and (c) “Yulia knocked on the door, but no one answered so she knocked again”. Again, in Phase 2 only new complications were coded. A second coder coded a random sample of 50 transcripts. Inter-rater reliability between the two coders, using the two-way random effects model measuring consistency, was good (single measures, intraclass correlation coefficient, ICC = .80). Similar as with total details, the first coder was then given her codings of the truthful statements and was asked to highlight all complications referring to the actions of the undercover agent John. There were two such complications present in the video recording, both related to him arriving late for the meeting. These complications were then subtracted from the total number of complications reported. The maximum number of complications participants could report from the video recording was therefore 23. Strategies Coding For strategies coding, a bottom-up form of coding was carried out whereby similar comments made were grouped together by the first coder and categorised accordingly. It resulted in the eight categories included in Table 2. A second coder, blind to veracity status, was given the eight categories and allocated the strategy statements of all participants to these eight categories. The inter-rater reliability between the two coders was very good (kappa = .84.) The discrepancies were resolved in a discussion between the coders. Table 1 Manipulation Checks, Questionnaire Variables, and Details, and Complications as a Function of Veracity  Note. NHST = Null-hypothesis significance testing. All statistical information is provided in Table 1. Apart from reporting the results for null-hypothesis significance testing (NHST) and the effect size (Cohen’s d), we also report the results for equivalence testing to support any null findings demonstrating an absence of differences between truth tellers and lie tellers (see Lakens et al., 2018). We decided that our smallest effect size of interest is 0.5, and thus equivalence bounds ranged between -0.5 and 0.5. Our decision was based on the fact that our research is applied and we were thus interested in observing a medium to large effect size, and on previous lie detection research where medium to large effect sizes were found (see Vrij, Fisher et al., 2017). Manipulation Check A 2 (Veracity: truth vs. lie) x 2 (Model Statement: absent vs. present) ANCOVA was carried out with self-reported percentage of truth telling as dependent variable and Participant Satus as covariate. The analysis revealed a significant Veracity effect, F(1, 146) = 64.64, p < .001, d = 1.32, 95% CI [0.94, 1.65]. All other effects, including the covariate, were not significant, all Fs < 0.64, all ps > .426. The Veracity results are presented in Table 1. Truth tellers reported to have been telling the truth significantly more than lie tellers. Two ANCOVAs were carried out with Veracity as factor and the two impressions about the Model Statement as dependent variables. Participant Status was the covariate. These analyses were carried out for the Model Statement condition only. The Veracity and covariate effects were not significant, all Fs < 2.63, all ps > .108. The participants agreed with the statement that the Model Statement made them realise that they had to say more than originally planned and disagreed with the statement that the Model Statement made them realise that they had to say less than originally planned (Table 1). Participants thus understood that the Model Statement was meant to encourage them to provide more details. Questionnaire Variables A 2 (Veracity) x 2 (Model Statement) MANCOVA was carried out with the five questionnaire variables listed in Table 1 as dependent variables. Participant Status was the covariate. At a multivariate level, none of the effects, including the covariate effect, were significant, all Fs < 1.18, all ps > .324. Table 1 shows that participants reported to have been very motivated. They rated their preparation as good and thought they were given enough time to prepare themselves. They rated their rapport with the interviewer as good and found it somewhat unlikely to win the lottery prize, lie tellers even more so than truth tellers. Hypotheses Testing A 2 (Veracity) x 2 (Model Statement) MANCOVA was carried out with the number of reported details and complications in Phase 1 as dependent variables and Participant Status as covariate. At a multivariate level the analysis revealed a significant Veracity main effect, F(2, 145) = 9.39, p < .001, ηp2 = .12, and a significant covariate effect, F(2, 145) = 5.04, p = .008, ηp2 = .07. The Model Statement main effect, F(2, 145) = 0.26, p = .769, ηp2 = .004, and the Veracity x Model Statement interaction effect, F(2, 145) = 0.67, p = .514, ηp2 = .009, were not significant. The univariate Veracity results are presented in Table 1. Truth tellers reported significantly more complications than lie tellers in Phase 1, and equivalence testing did not support the null hypothesis, thus supporting Hypothesis 1. The effect for total details was not significant and equivalence testing supported the null hypothesis. Another 2 (Veracity) x 2 (Model Statement) MANCOVA was carried out with the number of reported new details and new complications in Phase 2 as dependent variables and Participant Status as the covariate. At a multivariate level, the analysis revealed significant main effects for Veracity, F(2, 145) = 6.76, p = .002, ηp2 = .09, Model Statement, F(2, 142) = 56.14, p < .001, ηp2 = .44, and the covariate, F(2, 145) = 4.80, p = .001, ηp2 = .06. The Veracity x Model Statement interaction effect was not significant, F(2, 145) = 1.93, p = .149, ηp2 = .03. The univariate Veracity effects are presented in Table 1. Lie tellers provided more new details than truth tellers in Phase 2 of the interview; the difference for new complications was not significant. Equivalence testing demonstrated that the null hypothesis was rejected for new details and new complications. Therefore, the results on new complications were inconclusive. The Model Statement univariate effects for new details, F(1, 146) = 104.96, p < . 001, d = 1.60, 95% CI [1.21, 1.95], and new complications, F(1, 146) = 29.28, p < .001, d = 0.87, 95% CI [0.53,1.19], were both significant. Participants in the Model Statement present condition reported more new details (M = 17.28, SD = 9.78, 95% CI [15.53, 18.91]) and more new complications (M = 2.16, SD = 1.60, 95% CI [1.85, 2.47]) than participants in the Model Statement absent condition (new details: M = 4.71, SD = 5.16, 95% CI [3.07, 6.47]; new complications: M = 0.95, SD = 1.13, 95% CI [0.63, 1.26]). Equivalence testing revealed that the null hypothesis was not supported for new details, t(114.08) = 6.82, p = 1.00, and new complications, t(135.02) = 2.30, p = .988, thus supporting the NHST results. This supports Hypothesis 2. Self-reported Strategies A similar number of truth tellers (n = 33) and lie tellers (n = 37) said that they employed a strategy during the interview, χ2(1, 151) = 0.53, p = .466. The strategies are depicted in Table 2. Table 2 Self-Reported Strategies Employed during the Interview as a Function of Veracity 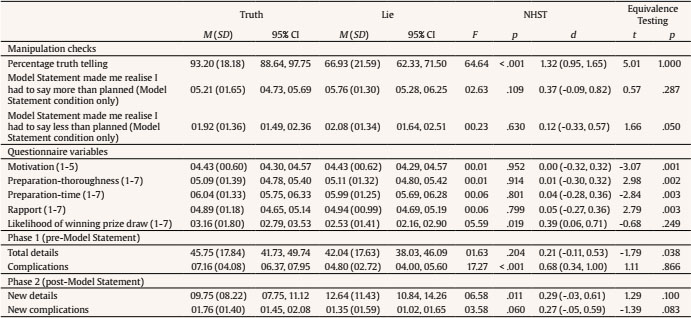 The most frequently reported strategy amongst truth tellers was ‘to be detailed’ followed by ‘paying attention to own demeanour’. Other reported strategies were ‘telling the truth’ and ‘reporting specific details’. Amongst lie tellers the most frequently reported strategy was ‘to omit information’ followed by ‘to substitute John’s details’. Other mentioned strategies were ‘pay attention to own demeanour’, ‘be detailed’, ‘keep it simple’, and ‘mention specific details’. If we compare the strategies amongst truth tellers and lie tellers three main differences emerged: lie tellers, more than truth tellers, reported ‘omitting information’ and ‘to substitute John’s details’, reflecting the instructions lie tellers were given. Truth tellers more than lie tellers reported to ‘have been detailed’ and ‘to mention specific details’. We replicated Leal et al.’s (2020) findings that lie tellers reported fewer complications than truth tellers. This complications veracity effect showed that the truthful information lie tellers recalled provided evidence that they were hiding something. Yet the present findings were not identical to Leal et al. We found that truth tellers reported more complications in the first recall, but not in the second recall. Leal et al. only found a significant difference in the second recall. They suggested that this may have been caused by introducing a Model Statement prior to the second recall but we found no evidence for that in the present experiment, as the Veracity x Model Statement effect was not significant. The number of complications provided in the first and second recalls in both experiments may explain the difference in complications findings between the two experiments. In the present experiment the first recall resulted in an average of 5.99 complications and the second recall in an average of 1.56 new complications (making it 7.55 unique complications in the entire interview). In addition, the first recall resulted on average in 43.91 details and in 11.03 new details in the second recall (making it 54.94 unique details in the entire interview). This means that the vast majority of unique complications (and details) was reported in the first recall. A second recall has less chance to reveal Veracity differences if interviewees report little new information in the second recall. This contradicts Leal et al.’s (2020) findings. In that experiment, on average about 0.45 complications were reported in the first recall followed by 0.9 new complications in the second recall; and on average about 29.5 details were reported in the first recall and 37.5 new details in the second recall. With more new complications and new details being provided in the second recall, Veracity differences have a higher chance to occur in that recall. We do not know why in the present experiment the participants seem to have given a more complete first recall account than in Leal et al. (2020). The deception scenarios were very different making a comparison between the two experiments impossible. In Leal et al., participants carried out a mission and were interviewed about that mission in Interview 1. They were then interviewed in Interview 2 about Interview 1 and the Interview 2 data were analysed. Perhaps the live event in Leal et al. was more arousal provoking than the videotaped event in the present experiment, making an initial first complete recall more difficult to achieve. Alternatively, perhaps the event in Leal et al. was richer in detail than the current event, again making an initial complete recall more difficult to achieve. Also, there were more non-students in the present sample than in Leal et al. and non-students reported more details than students in the present experiment, experiment (see Appendix 1). These are just three out of a large number of possible reasons. The key observation is that cues to deception are more likely to occur in a second recall if interviewees have not yet reported in the first recall almost all they reported in the entire interview. The self-reported strategies employed by truth tellers and lie tellers may give insight into the reason for the complications veracity effect. Truth tellers were more inclined than lie tellers to be detailed and to mention specific details. This could have contributed to the complications veracity effect. Complications are often not part of the key elements in a story and if lie tellers decide to be less detailed, they may well leave out those less important elements of a story. Since we know the number of complications in the video recording (n = 23), the current experiment gives us insight into how many complications truth tellers tend to report. They reported on average 8.92 complications, which is 38.78% of the total number of complications they could have reported. This rather low percentage can easily be explained. The information covered in complications is often not about key aspects of the activities that someone describes, and the story can be well understood without reporting the complications (Vrij et al., 2018). It also suggests that there is potential for complications to become a more diagnostic veracity indicator if investigators can make truth tellers report more complications. Methods to assist interviewees to report more complications should have a larger effect on truth tellers than on lie tellers due to lie tellers’ strategy to keep stories simple and their belief that adding complications sound suspicious (Maier et al., 2018). Previous strategies research when lying through fabrication has shown that truth tellers are inclined to tell it all and lie tellers inclined to keep it simple (Granhag & Hartwig, 2008). The ‘tell it all’ strategy also emerged in the present experiment because ‘to be detailed’ is similar to ‘tell it all’. It makes sense that the same strategy emerged in truth tellers in lying through fabrication settings as in lying through omission settings. The deception scenario is irrelevant to them and in both settings they do the same: telling the truth. For lie tellers’ strategies, two differences emerged in the present experiment compared to previous strategies research based on lying through fabrications. First, in the lying through fabrications research it is typically found that lie tellers are more inclined to employ a strategy than truth tellers (Hartwig et al., 2007). In the present experiment no difference in using a strategy emerged between truth tellers and lie tellers. This suggests that the mind set of lie tellers is different when they lie through omissions than when they lie through fabrication. Second, ‘keeping it simple’, the dominant strategy for lie tellers when they lie through fabrication, was rarely mentioned in the present experiment, providing further evidence that the mind set of lie tellers is different when they lie through omissions than when they lie through fabrication. The main difference between truth tellers and lie tellers in the present experiment was that truth tellers were more inclined to tell it all than lie tellers. This suggests that verbal veracity differences when lying through omissions may emerge as a result of the relative absence of the truth tellers’ ‘telling it all’ strategy amongst lie tellers rather than through the execution of a specific lie tellers’ strategy. Further research should examine this. Lie tellers reported more new details than truth tellers in Phase 2 of the interview. This does not replicate Leal et al. (2020), who found no difference. It is also in contrast to when individuals lie through fabrications because in such settings truth tellers typically provide more details than lie tellers (Amado et al., 2016). We can only speculate why we obtained this finding. Lie tellers could do the same as truth tellers, adding more truthful details, and perhaps lie tellers were more motivated than truth tellers to do so in order to convince the interviewer of their sincerity. Whatever the reason, the current finding combined with the null finding in Leal et al. means that the typical details veracity effect (truth tellers report more detail than lie tellers) has not been obtained yet in lying through omissions research. To examine whether this is a real type of lie difference, an experiment is required in which type of lie (fabrication vs. omission) is manipulated. We are not suggesting that total details will never be a veracity indicator when lying through omissions, but we think it is less likely to occur than when people lie through fabrication. Whether total details becomes a veracity indicator probably depends on how difficult it is to omit information. In the present experiment it was not too difficult. Lie tellers could avoid mentioning the presence of the third person (John) and pretend that someone else said what John said. This is not always a good option in real life. For example, maybe John has a certain expertise and investigators are aware of that. Recalling what John had said (albeit by a different person) could then reveal to investigators John’s presence in the meeting. Lying through omitting information becomes more difficult if lie tellers have to take such aspects into account. Three limitations of the experiment are worth mentioning. First, the strategy of some lie tellers was to attribute John’s details to someone else, for example by attributing John’s speech to someone else present in the meeting. If a lie teller would have mentioned the name of that other person, s/he would have added a fabrication to the statement. However, such fabrications would have been one-word utterances and we still could consider the entire statement lying through omitting information. Second, in the present experiment the reason for lie tellers to omit information was to protect someone else. Practitioners told us that this is a common reason for omitting information, which is why we and perhaps also Dando and Ormerod (2020) chose to examine this type of omission. However, there could be other reasons for omitting information, such as to hide one’s own wrongdoings. Future lying through omitting information research could manipulate the reasons for omitting information and measure its effect on the quality of statements. Third, one of the benefits of carrying out experiments online is that it is relatively easy to recruit participants outside the population typically used in deception research: university students. We did not expect differences between our students and nonstudents subsamples and the obtained differences were indeed minor. However, our nonstudents were recruited via social media and word of mouth, which may be a limitation. It is likely that those recruited were not too far removed from the academic setting. A different way of recruiting nonstudents may have given us different results, although we consider this to be unlikely. It could be that students have better verbal skills than non-students and therefore perhaps say more. However, there is no theoretical reason as to why students and non-students would react to manipulations (such as the Veracity factor in an experiment) in different ways. The Model Statement resulted in more details than the instruction to tell all someone could remember. This is a typical finding in deception research (Vrij et al., 2018) and makes the use of a Model Statement valuable for gathering information. We explored whether a Model Statement would enhance the differences between truth tellers and lie tellers in reporting complications. This did not happen. This could mean that a Model Statement does not enhance such differences in omission scenarios. Alternatively, the little amount of additional information interviewees provided in the second recall in the present experiment may have caused the absence of this effect. Future research is needed to shed light on this. Conflict of Interest The authors of this article declare no conflict of interest. Cite this article as: Leal, S., Vrij, A., Deeb, H., Burkhardt, J., Dabrowna, O., & Fisher, R. P. (2023). Verbal cues to deceit when lying through omitting information: Examining the effect of a model statement interview protocol. European Journal of Psychology Applied to Legal Context, 15(1), 1-8. https://doi.org/10.5093/ejpalc2023a1 Funding: This work was funded by the Centre for Research and Evidence on Security Threats (ESRC Award: ES/N009614/1). References Appendix The Results with Participant Status as a Factor A 2 (Veracity: truth vs. lie) x 2 (Model Statement: absent vs. present) x 2 (Participant Status: students/staff vs. non-students/staff) ANOVA was carried out with self-reported percentage of truth telling as dependent variable. The analysis revealed a significant Veracity effect, F(1, 143) = 65.96, p < .001, d = 1.32, 95% CI [0.94, 1.65]. All other effects were not significant, all Fs < 3.26, all ps > .072. Two ANOVAs were carried out utilising a 2 (Veracity) x 2 (Participant Status) design with the two impressions about the Model Statement as dependent variables. These analyses were carried out for the Model Statement condition only. They revealed no significant effects, all Fs < 1.84, all ps > .166. A 2 (Veracity) x 2 (Model Statement) x 2 (Participant Status) MANOVA was carried out with the five questionnaire variables listed in Table 1 as dependent variables. At a multivariate level, none of the effects were significant, all Fs < 1.15, all ps > .399. A 2 (Veracity) x 2 (Model Statement) x 2 (Participant Status) MANOVA was carried out with the number of reported details and complications in Phase 1 as dependent variables. At a multivariate level the analysis revealed a significant Veracity main effect, F(2, 142) = 9.08, p < .001, ηp2 = .11, and a significant Participant Status main effect, F(2, 142) = 4.94, p = .008, ηp2 = .07. All other effects were not significant, all Fs < .083, all ps > .438. At a univariate level, a significant Participant Status main effect emerged for total details, F(1, 143) = 4.18, p = .043, d = 0.21, 95% CI [-0.11, 0.53]. The non-students/staff (M = 46.73, SD = 18.16, 95% CI [42.67, 50.80]) provided more total details than the students/staff (M = 40.81, SD = 16.93, 95% CI [36.83, 44.78]). Equivalence testing showed that this effect was not statistically equivalent to zero, t(148.92) = -1.00, p = .159, thus confirming the NHST results. Another 2 (Veracity) x 2 (Model Statement) x 2 (Participant Status) MANOVA was carried out with the number of reported new details and new complications in Phase 2 as dependent variables. At a multivariate level, the analysis revealed significant main effects for Veracity, F(2, 142) = 6.80, p = .002, ηp2 = .09, Model Statement, F(2, 142) = 57.49, p < .001, ηp2 = .45, and Participant Status, F(2, 142) = 5.01, p = .008, ηp2 = .07. The Model Statement x Participant Status was also significant, F(2, 142) = 3.20, p = .044, ηp2 = .04, but the other effects were not, all Fs < 1.82, all ps > .165. At a univariate level, one significant Participant Status effect emerged, F(1, 143) = 8.58, p = .004, d = 0.39, 95% CI [0.06, 0.70], with non-students/staff providing more new details (M = 12.86, SD = 10.94, 95% CI [11.01 ,14.24]) than students/staff (M = 9.03, SD = 8.58, 95% CI [7.46,10.85]). Equivalence testing did not support the null hypothesis for new details, t(145.84) = -0.68, p = .248, thus confirming the NHST results. At a univariate level, only the Model Statement x Participant Status interaction effect for new details was significant, F(1, 143) = 6.41, p = .012, ηp2 = .04. Simple contrast effects showed that in the students/staff sample the Model Statement present condition resulted in more new details (M = 13.86, SD = 9.38, 95% CI [11.43, 16.29]) than the Model Statement absent condition (M = 4.46, SD = 4.24, 95% CI [2.10, 6.82]), F(1, 70) = 30.59, p < .001, d = 1.26 (0.71, 1.77). Equivalence testing corroborated these results, t(46.76) = 3.33, p = .999. Also in the non-students/staff sample, the Model Statement present condition resulted in more new details (M = 20.20, SD = 9.26, 95% CI [17.75, 22.64]) than the Model Statement absent condition (M = 4.95, SD = 5.98, 95% CI [2.41, 7.49]), F(1, 77) = 74.26, p < .001, d = 1.94 (1.38, 2.44). Equivalence testing corroborated these results, t(68.99) = 6.52, p = 1.00. The effect was the strongest in the non-students/staff sample. In most psychology experiments, participants consist of university students and staff. In the current experiment we also recruited a subsample of participants outside this specific group which made it possible to compare the results. We found only a few differences between the two subsamples. The non-student/staff sample provided more details in Phase 1 and more new details in Phase 2 than the student/staff sample. Although more new details were elicited in both groups when a Model Statement was present rather than absent, the effect was the strongest in the non-student/staff subsample. The Veracity effect is probably more important and that effect was not significant. This gives, in this experiment at least, an indication that deception research results from a student/staff population can be generalised to a wider population. |
Cite this article as: Leal, S., Vrij, A., Deeb, H., Burkhardt, J., Dabrowna, O., & Fisher, R. P. (2023). Verbal Cues to Deceit when Lying through Omitting Information: Examining the Effect of a Model Statement Interview Protocol. The European Journal of Psychology Applied to Legal Context, 15(1), 1 - 8. https://doi.org/10.5093/ejpalc2023a1
Correspondence: sharon.leal@port.ac.uk (S. Leal).Copyright © 2026. Colegio Oficial de la Psicología de Madrid





 PDF
PDF e-PUB
e-PUB CrossRef
CrossRef JATS
JATS Print
Print Send
SendEMAIL ALERT
The European Journal of Psychology Applied to Legal Context is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License








