


A Systematic Review of Machine Learning for Assessment and Feedback of Treatment Fidelity
[Revisión sistemática del aprendizaje automático para la evaluación y feedback de la fidelidad al tratamiento]
Asghar Ahmadi1, Michael Noetel1, 2, Melissa Schellekens1, Philip Parker1, Devan Antczak1, Mark Beauchamp3, Theresa Dicke1, Carmel Diezmann4, Anthony Maeder5, Nikos Ntoumanis6, 7, 8, Alexander Yeung1, and Chris Lonsdale1
1Unstitute for Positive Psychology and Education, Australian Catholic University, Australia; 2School of Health and Behavioural Sciences, Australian Catholic University, Australia; 3School of Kinesiology, University of British Columbia, Canada; 4Faculty of Education, Queensland University of Technology, Australia; 5College of Nursing and Health Sciences, Flinders University, Australia; 6Department of Sports Science and Clinical Biomechanics, University of Southern Denmark, Denmark; 7School of Psychology, Curtin University, Australia; 8Halmstad University, Sweden
https://doi.org/10.5093/pi2021a4
Received 6 December 2020, Accepted 13 May 2021
Abstract
Many psychological treatments have been shown to be cost-effective and efficacious, as long as they are implemented faithfully. Assessing fidelity and providing feedback is expensive and time-consuming. Machine learning has been used to assess treatment fidelity, but the reliability and generalisability is unclear. We collated and critiqued all implementations of machine learning to assess the verbal behaviour of all helping professionals, with particular emphasis on treatment fidelity for therapists. We conducted searches using nine electronic databases for automated approaches of coding verbal behaviour in therapy and similar contexts. We completed screening, extraction, and quality assessment in duplicate. Fifty-two studies met our inclusion criteria (65.3% in psychotherapy). Automated coding methods performed better than chance, and some methods showed near human-level performance; performance tended to be better with larger data sets, a smaller number of codes, conceptually simple codes, and when predicting session-level ratings than utterance-level ones. Few studies adhered to best-practice machine learning guidelines. Machine learning demonstrated promising results, particularly where there are large, annotated datasets and a modest number of concrete features to code. These methods are novel, cost-effective, scalable ways of assessing fidelity and providing therapists with individualised, prompt, and objective feedback.
Resumen
Se ha puesto de manifiesto que muchos tratamientos psicológicos tienen un coste efectivo y son eficaces siempre que se apliquen con fidelidad. La evaluación de esta y el feedback son caros y exigen mucho tiempo. El aprendizaje automático se ha utilizado para evaluar la fidelidad al tratamiento, aunque su fiabilidad y capacidad de generalización no estén claras. Recopilamos y analizamos todas las aplicaciones de aprendizaje automático con el fin de evaluar el comportamiento verbal de todos los profesionales de ayuda, con el acento particular en la fidelidad al tratamiento de los terapeutas. Llevamos a cabo búsquedas en nueve bases de datos electrónicas para enfoques automáticos de codificación de comportamiento verbal en terapia y contextos semejantes. Llevamos a cabo el cribado, la extracción y la evaluación de la calidad por duplicado. Cincuenta y dos estudios cumplían nuestros criterios de inclusión (el 65.3% en psicoterapia). Los métodos de codificación automática resultaban mejor que el azar y algunos de ellos mostraban un desempeño casi al nivel humano, que tendía a ser mejor con conjuntos más grandes de datos, un número de códigos menor, códigos conceptualmente simples y cuando predecían índices al nivel de sesión que los de tipo declaración. Escasos estudios cumplían las directrices de buena praxis en aprendizaje automático. Este presentó unos resultados alentadores, sobre todo donde había conjuntos de datos grandes y anotados y un escaso número de características concretas que codificar, modos expansibles de evaluar la fidelidad y facilitar a los terapeutas un feedback individualizado, rápido y objetivo.
Keywords
Machine learning, Treatment fidelity, Treatment integrity, Clinical supervision, FeedbackPalabras clave
Aprendizaje automático, Fidelidad al tratamiento, Integridad del tratamiento, SupervisiĂłn clĂnica, FeedbackCite this article as: Ahmadi, A., Noetel, M., Schellekens, M., Parker, P., Antczak, D., Beauchamp, M., Dicke, T., Diezmann, C., Maeder, A., Ntoumanis, N., Yeung, A., & Lonsdale, C. (2021). A Systematic Review of Machine Learning for Assessment and Feedback of Treatment Fidelity. Psychosocial Intervention, 30(3), 139 - 153. https://doi.org/10.5093/pi2021a4
michael.noetel@acu.edu.au Corresponding author: michael.noetel@acu.edu.au (M. Noetel)When implemented faithfully, psychological treatments are powerful (Barth et al., 2013; Blanck et al., 2018; Kazdin, 2017; Öst & Ollendick, 2017). But, a major problem with both researching and implementing psychological treatments is fidelity (Bellg et al., 2004; Perepletchikova & Kazdin, 2005). Ensuring that treatments are implemented faithfully is important for a few reasons. First, when training practitioners on evidence-based interventions, prompt clinician feedback can facilitate skill acquisition and faithful implementation (Prowse & Nagel, 2015; Prowse et al., 2015). Second, without assessing fidelity we cannot determine whether effects from intervention studies are due to a homogenous treatment (Prowse & Nagel, 2015; Prowse et al., 2015). However, treatment fidelity is rarely well assessed—fewer than 10% of studies adequately assess fidelity (Perepletchikova & Kazdin, 2005; Perepletchikova et al., 2007). Cost and time are significant barriers (Borrelli, 2011). In psychotherapy, technology has become a well-established method of reducing costs of treatment by creating, for example, online interventions (Fairburn & Patel, 2017; Kazdin, 2017). But, the use of technologies for assessment and training is comparatively nascent (Fairburn & Cooper, 2011; Fairburn & Patel, 2017). This paper presents a systematic review of machine learning strategies to assess the fidelity of psychological treatments. Fidelity encompasses three core components: adherence, differentiation, and competence (Rodriguez-Quintana & Lewis, 2018). Adherence describes a therapist’s use of methods proposed by the guiding framework (e.g., using cognitive defusion while delivering Acceptance and Commitment Therapy). Differentiation is the avoidance of methods not proposed by that theory (e.g., using thought stopping while delivering Acceptance and Commitment Therapy). Competence is the skill with which the therapist implements the intervention (e.g., demonstrating a strong therapeutic alliance; Kazantzis, 2003). As a result, treatment fidelity is important both in the content and the process of therapy. Many interventions, like Motivational Interviewing and Cognitive Behaviour Therapy, both prescribe the content of therapy (e.g., change-talk and cognitive challenging, respectively) and the process of therapy (e.g., both emphasise the importance of an empathic therapeutic alliance; Kazantzis, 2003; Madson et al., 2009). From a content perspective, it is common for therapists to drift away from the core, evidence-based foci of therapy (Bellg et al., 2004; Waller, 2009; Waller & Turner, 2016). They may fail to use interventions that faithfully incorporate the therapy (low adherence) or ‘dabble’ in interventions from other therapies (low differentiation). But fidelity can also refer to the non-judgemental, compassionate, empathic process that is central to many therapies. As such, quality interpersonal interactions are critical for competent treatment (Kornhaber et al., 2016). Psychologists that competently demonstrate evidence-based interpersonal skills are more effective at reducing maladaptive behaviours such as substance abuse and risky behaviours than clinicians with poorer skills (e.g., Parsons et al., 2005). Their clients are more likely to complete treatment and change behaviour too (Golin et al., 2002; Moyers, Miller, et al., 2005; Street et al., 2009). As a result, researchers have developed a range of treatment integrity measures (Rodriguez-Quintana & Lewis, 2018), including many that assess the content of therapy (McGlinchey & Dobson, 2003) and the process of therapy (e.g., Motivational Interviewing Skill Code: Miller et al., 2003; Motivational Interviewing Treatment Integrity: Moyers, Martin, et al., 2005). There are even measures for assessing how well treatment fidelity is assessed (Perepletchikova et al., 2009). These measures improve the quality of research and the translation of evidence-based therapies into practice (Prowse & Nagel, 2015; Prowse et al., 2015). The most objective of these measures involve an observer rating the behaviours of the therapist at regular intervals or after having watched an entire session with a client. As a result, assessing fidelity requires significant resources (Fairburn & Cooper, 2011). Recently, researchers have begun applying machine learning models to automate this task. These models will not be useful if they fail to accurately assess fidelity, or if the methods used to create the models do not generalise to other samples. So, in this paper, we aimed to identify, synthesise, and critique the automated coding methods that have been applied to treatment fidelity. What is Machine Learning? Machine learning refers to any algorithm that learns patterns from data. A linear regression model, familiar to most readers, is a form of machine learning, where an algorithm discerns the strength of the linear relationship between variables. However, machine learning also includes a broad range of other, often more complex, algorithms. These algorithms can either learn the patterns automatically by themselves (i.e., unsupervised machine learning) by, for example, identifying how data points cluster together. Alternatively, they can be trained using labelled data (i.e., supervised machine learning), where, for example, thousands of sentences are labelled by humans as ‘empathic’ and the model identifies the words that might indicate empathy. The line between ‘statistics’ and ‘machine learning’ is imprecise. In common usage, ‘statistics’ refers to more interpretable models that allow for inferences that explain a phenomenon (Hastie et al., 2009; Shmueli, 2010). ‘Machine learning’ is a more encompassing, umbrella term that also includes less interpretable models that may predict but not explain (Hastie et al., 2009; Shmueli, 2010). So while traditional statistics aim to explain relationships between variables, machine learning also includes methods that focus on predictive accuracy over hypothesis-driven inference (Breiman 2001). With new computational capabilities, machine learning can use large, multidimensional data to construct complex, non-linear models (Breiman, 2001). Traditional statistical methods are more interpretable but those constraints mean they perform less well in these more complex problems (Bi et al., 2019). This is an important feature because predicting interpersonal interactions requires multidimensional models that account for the complexity of human language. Concept of Accuracy in Machine Learning In machine learning, accuracy evaluates how well the model identifies relationships and patterns between variables in a dataset. Several evaluation metrics and validation methods have been used to evaluate the prediction performance and generalization of machine learning methods. The commonly used metrics include accuracy, precision, F1, sensitivity, specificity, and area under the receiver operating characteristic (AUC ROC) curve (for a description of the performance metrics, see Supplementary file 1). There has been extensive debate on what metric is best for which task (Handelman et al., 2019). However, one way to choose the most appropriate metric is to consider the distribution of classes and the potential cost of misclassification (Hernandez-Orallo, 2012). For example, in psychotherapy, accuracy might be a good indication of a model’s performance which shows the correct prediction of true positives out of all the observations. However, in detecting suicidality, the recall (or sensitivity) metric may be important as the correct identification of all high-risk cases may be crucial. So, considering the intended purpose of using machine learning models can be helpful to determine the most appropriate performance metric and threshold. One of the important goals of developing machine learning models is to predict the outputs in the future unseen data. Validation techniques evaluate the generalizability of models to ‘out of sample’ data (i.e., data not used to train the model). After training a model, validation usually involves testing the model on new data that was not used in training. This is different from the common practice of looking at, for example, R-squared from the output of a regression model. Here the prediction metric—R-squared—comes from the same data used to build the model. From the perspective of machine learning, only predictive accuracy from new data—that is data not used in building the model—is of interest. In machine learning, new data is referred to as unseen data because the model has not seen the data and thus does not have the option to update the model or its parameters in response to it. Several methods have been used to validate models such as cross validation and hold-out ‘train and test’. Cross-validation (which is also called internal validation) is a commonly used method where a dataset is separated into a training subset and a testing subset. Then, the prediction metrics are calculated to assess the prediction accuracy on the testing subset. Some of the cross-validation methods include split-half (50% training, 50% test samples), imbalanced-split (i.e., 70:30), k-fold (split into k subsets, usually 5 or 10), leave-one-out (a single test case is held-out of the training sample), or bootstrapping methods (Delgadillo, 2021; Rodriguez et al. 2010). Another validation method, named hold-out ‘train and test’, better estimates the generalisability of models to future datasets. This process is called external validation, where the model is trained on some data (training dataset) and is tested on data from a different sample, study, or setting. This method is stronger than cross-validation because the validation set is more likely to be representative of future data and less likely to overlap with the training set. Machine Learning May Improve Feedback for Therapists Therapists vary greatly in their effectiveness, and with more experience they actually decrease their effectiveness (Goldberg et al., 2016). This decline in effectiveness may be partially explained by lapses in fidelity. For example, without feedback or coaching, fidelity to motivational interviewing substantially decreases within six months of training (Schwalbe et al., 2014). This is often described as ‘therapist drift’, where well-meaning therapists fail to adhere to the prescribed practice guidelines (Waller, 2009; Waller & Turner, 2016). Therapists are bad at identifying these problems themselves because they rely on unreliable signals of their own effectiveness (Tracey et al., 2014). However, it is possible to mitigate these problems through quality feedback, auditing, and supervision (Barwick et al., 2012; Ivers et al., 2012; Madson et al., 2009). Indeed, one of the core goals of training and clinical supervision is increasing treatment fidelity (Bellg et al., 2004; Reiser & Milne, 2014). Accurate and individualised feedback enables therapists to adopt effective strategies to enhance client outcomes (Ivers et al., 2012; Tracey et al., 2014). Research shows that feedback is most effective when it is distributed over a period of time on multiple occasions (Ivers et al., 2012). For example, three to four post-workshop feedback sessions prevent skill erosion among Motivational Interviewing trainees (Schwalbe et al., 2014). However, providing feedback using traditional methods is an expensive process for agencies and a time consuming job for supervisors. It can be even a more resource-intensive process when there are many therapists in a large scale training. New techniques, such as machine learning, are capable of quickly and cheaply analysing large-scale data, providing accurate individualised feedback. Automated coding methods have been applied to large psychotherapy datasets up to 1,553 sessions (Xiao et al., 2016). Once these models are trained, they can be repeatedly applied at very low cost (Xiao et al., 2016). They can reduce the likelihood of implicit bias of human decision-making (Lum, 2017), where the look or the sound of the therapist may contribute to errors in judgments. While some may doubt whether therapists would accept the feedback from machine learning models, preliminary feedback has been promising. Hirsch et al. (2018) provided machine learning based-feedback for 21 counsellors and trainees. The results of their qualitative study showed that counsellors were receptive to a computerised assessment, and were less defensive toward critical feedback from a machine than a human. It has also been documented that therapists are quite open to receiving machine learning feedback (Imel et al. 2019). In sum, machine learning models can cheaply provide objective feedback to therapists in a way that they are likely to find valuable. Verbal Behaviour May Be a Good Candidate for Machine Learning Interpersonal interactions in a therapy process involves a range of behaviours such as verbal behaviours (i.e., what is said) and non-verbal behaviours (such as prosody, body movements, biological changes). However, verbal behaviours are the primary channel of transferring information in dyadic interactions (Miller et al., 2003). Systematic reviews have shown that therapists’ verbal behaviours are associated with various client outcomes, such as patient satisfaction and adherence to treatment (Golin et al., 2002; Howard et al., 2009). Most existing measures for assessing treatment fidelity focus on the words used by the therapist, rather than their tone or non-verbal behaviour (McGlinchey & Dobson, 2003; Miller et al., 2003; Moyers, Martin, et al., 2005). Verbal behaviour is also easy to code automatically, where even simple ‘word-counting’ methods can reliably and validly predict many psychological constructs (Pennebaker et al., 2003). Further, methods for automatic assessment of verbal behaviour are different from those for non-verbal or para-verbal (e.g., signal-processing features like tone, pitch, and pacing) behaviours. Many such tools have allowed for automated assessment of patient characteristics, such as diagnoses (Low et al., 2020). Emerging technologies may be able to code some non-verbal behaviour like sign language, but those technologies are not sufficiently advanced that they can code the nuanced non-verbal cues involved in psychosocial interventions. So, while non-verbal and para-verbal modalities are critical components of therapy, we focused on verbal interactions as an important and tractable machine learning task. To analyse verbal behaviour, human coders are trained to identify specific therapy behaviours. The reliability of human-to-human codes are evaluated via a process called interrater reliability. Just as therapists drift, coders do too, where interrater reliability can decrease with fatigue or without frequent re-calibration (Atkins et al., 2012; Haerens et al., 2013). Often when two humans code for fidelity using words therapists use, they are not perfectly aligned. Coders may overcome the ‘coding drift’ by meeting regularly to discuss their codes and instances of coder disagreement. However, human coding also faces other challenges such as being tedious, expensive, and time consuming (Moyers et al., 2005). This means that human coding is an imperfect reference point, but a useful one to compare machine learning models against. Proof-of-concept comes from many other fields in which machine learning has been found to reliably automate laborious tasks (Russell & Norvig, 2002). Ryan et al. (2019) have argued that machine learning is already good enough to assess the content and delivery of healthcare by doctors. They have been applied to predict language disorders (Can et al., 2012), and addiction and suicide behaviour (Adamou et al., 2018). In psychotherapy, they have been used to predict counselling fidelity (Atkins et al., 2014), empathy (Xiao et al., 2015), and counsellor reflections (Can et al., 2016). A recent systematic review showed that 190 studies used machine learning methods to detect and diagnose mental disorders, indicating the applicability of machine learning in mental health research (Shatte et al., 2019). Similarly, Aafjes-van Doorn et al. (2021) did a scoping review of machine learning in the psychotherapy domain and showed that 51 studies applied machine learning models to classify or predict labelled treatment process or outcome data, or to identify clusters in the unlabelled patient or treatment data (Aafjes-van Doorn et al., 2021). Machine learning methods have also been used in psychiatry to parse disease models in complex, multifactorial disease states (e.g., mental disorders; Tai et al., 2019). When taken together, there are a number of domains in which machine learning models have been helpful in coding verbal behaviours, indicating they may be a powerful tool for psychotherapists and other helping professions. Review Aims The primary goal of this review is to assess how well machine learning performs as a method for assessing treatment fidelity using verbal aspects of therapist language. By conducting a systematic review, we were able to assess how well those models applied across studies and contexts. Models may only work well under a narrow set of conditions, and systematic reviews are able to assess those conditions more robustly than a narrative review. There are also some well-established best-practices that influence whether a machine learning model will generalise to new data (Luo et al., 2016). By assessing adherence to these guidelines, our review was able to indicate how well these models may generalise. Finally, we included all interpersonal interactions from helping professionals, even those outside psychotherapy (e.g., medicine, education), in order to assess whether machine learning models to assess communication and fidelity have been successfully implemented in nearby fields. In doing so, we could see whether models applied to medicine or education might be useful to consider in future psychological research. In sum, we sought to answer the following research questions:
We report this systematic review in accordance with the Preferred Reporting Items for Systematic Reviews and Meta-Analysis (PRISMA) statement (Moher et al., 2009). Protocol and Registration We prospectively registered the protocol in the Prospective Register of Systematic Reviews (PROSPERO registration number: CRD42019119883). Eligibility Criteria In this review, we included studies meeting the following criteria:
Exclusion Criteria We excluded studies if:
Search Strategy and Information Sources To develop the search strategy, we created an initial pool of target papers that met the inclusion criteria. We conducted forward and backward citation searching on this initial pool (Hinde & Spackman, 2015) to identify six more papers meeting the eligibility criteria. We extracted potential search terms from these 11 papers by identifying key words from the title and abstract (Hausner et al., 2016). The final search strategy involved keywords and their MeSH terms or synonyms from four main groups including ‘participants’ (e.g., teacher or doctor), ‘measurement’ (such as assessment or coding), ‘automated coding method’ (e.g., Natural Language Processing or text mining), and ‘type of behaviour’ (e.g., fidelity or interaction). The search did not have any exclusion terms (see Supplementary file 2 for full search details and included papers). We performed the search within PubMed, Scopus, PsycINFO, Education Source, ERIC, CINAHL Complete, Embase, SPORTDiscus, and Computers and Applied Sciences Complete databases. We performed the last search on the 21st of February 2021. To test the sensitivity of our strategy, we first confirmed that the identified records included 11 target papers described earlier. We then searched the first 200 results on Google Scholar to identify potentially relevant studies not indexed in electronic databases. We conducted forward and backward citation searching on studies that passed full-text to identify related papers which did not appear in the systematic search (Greenhalgh & Peacock, 2005; Hinde & Spackman, 2015). We also emailed the first author of included papers and known experts in the automated coding of verbal behaviour to identify any unpublished manuscripts. Study Selection We imported search results into Covidence software (Babineau, 2014). We dealt with studies in two steps. First, we screened the titles and abstracts of the studies according to the pre-defined inclusion criteria. If the title or abstract did not provide enough information to decide, we moved the record to full-text screening. Second, we reviewed full texts of articles for final inclusion. At each stage, two reviewers (AA and MS, or AA and DA) independently made recommendations for inclusion or exclusion. We resolved any discrepancies in study selection at a meeting. Then, we resolved any conflicts by consulting with a third reviewer (MN). The PRISMA flow diagram (Figure 1) provides detailed information regarding the selection process. Table 1 Quality Assessment 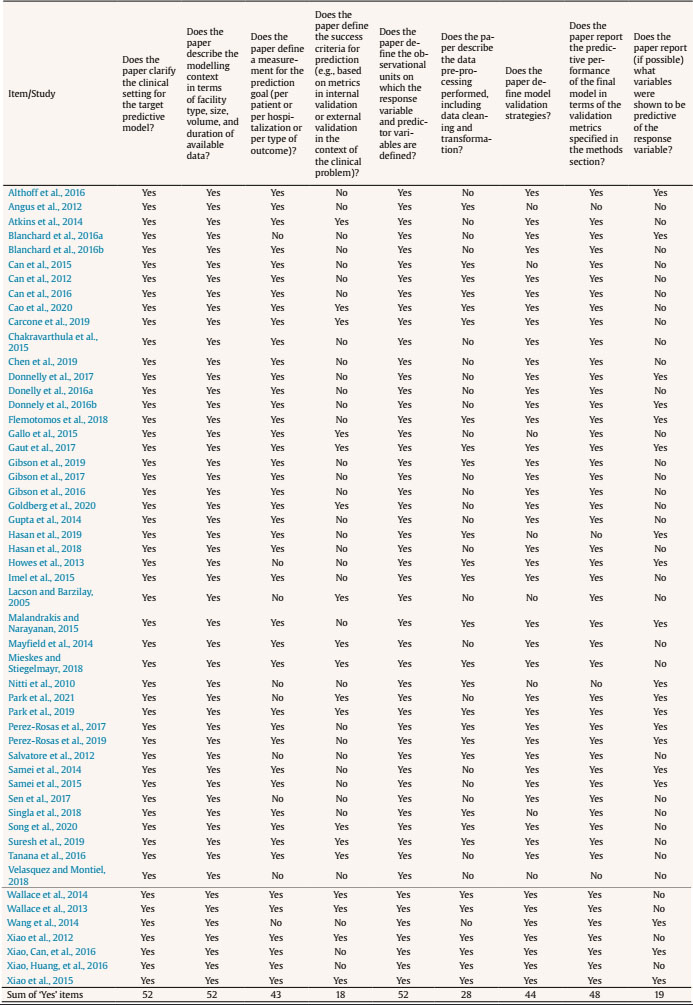 Figure 1 PRISMA Flow Diagram of the Study Selection Process. 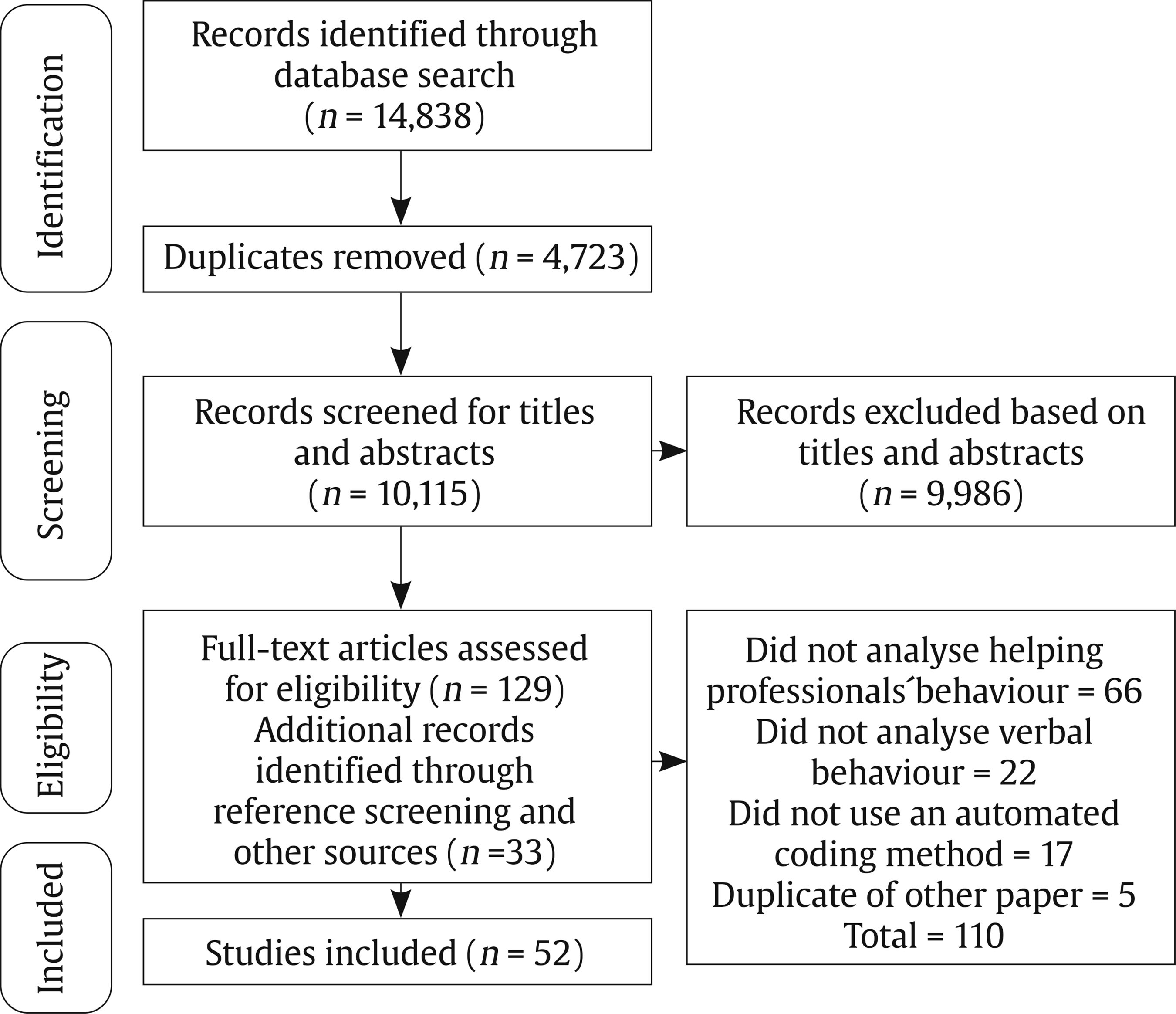 Data Collection Process We developed a data extraction form for this review to focus on the applied automated coding methods and their performance. We first tested the form by extracting data from four randomly selected papers. Two researchers (AA and MS or AA and DA) then independently extracted data from each study and organised it into tables to display themes within and across the included studies. Any discrepancies from the data extraction were discussed between the reviewers. In the case of unresolved disagreements, a third reviewer (MN) was consulted. Adherence to Best-Practices in Machine Learning We assessed study quality using a tool based on the “Guidelines for Developing and Reporting Machine Learning Predictive Models in Biomedical Research: A Multidisciplinary View” (Luo et al., 2016). This tool was used to judge the extent to which studies adhered to best-practice guidelines. The original checklist contained 51 items and investigated the quality of papers based on the information in each section of a paper. The checklist was used in two ways. One researcher (AA) assessed all 51 items. We refined this checklist by identifying the core items related to performance of automated coding methods. Of the 51 items, nine were related to the performance (see identified items in Table 1, and the complete checklist in Supplementary file 3); the others related to the reporting in the manuscript (e.g., three items are whether the abstract contains background, objectives, or data sources sections). The other researcher (MS/DA) assessed the core checklist. Specifically, the two researchers independently assigned the label “Yes” if the requisite information was described explicitly and “No” if the information was not adequately described. Rather than reporting a summary score (e.g., “high” or “low quality”), we followed Cochrane guidelines that recommend reporting quality scores for each item of the quality assessment checklist (Macaskill et al., 2010). Study Selection and Results of Individual Studies Our systematic search resulted in 14,838 records. We removed 4,723 duplicates, with 9,986 papers remaining for title and abstract screening. Thirty-three further records were added by other methods (e.g., forward and backward searching). Fifty-two papers met the inclusion criteria and were included in this review (see Figure 1). All the included papers were written in English. Supplementary file 4 summarises the information from individual studies. Table 2 Context of Study 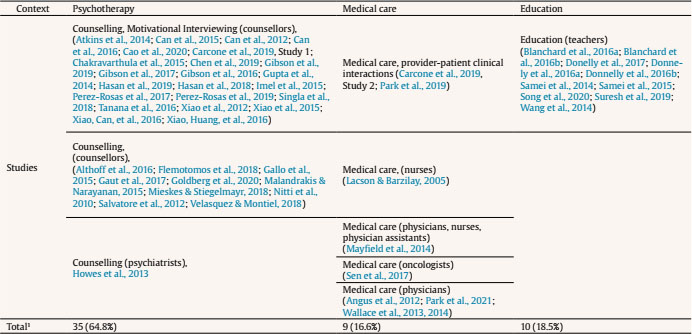 Note. 1One study was performed in two different contexts. Table 3 Frequency of Behavioural Coding Measures Used in Included Studies  Note. Some studies used more than one behavioural coding measure. Synthesis of Results Most of the studies were conducted in psychotherapy settings (k = 34, 65.3%) and involved counsellors, psychologists, or psychiatrists. Nine studies were conducted in a medical care setting (16.6%) and included physicians or nurses. Ten studies (18.5%) were conducted in education contexts and involved school teachers. Of the 53 studies, 23 (41.5%) examined Motivational Interviewing (Miller & Rollnick, 1991) with the rest of the studies scattered across different modalities (one paper included two studies, for details see Table 2). Predicted outcomes. Studies in the psychotherapy context aimed to predict the fidelity to a prescribed therapeutic process (k = 28, 82.3% of psychotherapeutic studies). In medical care settings, the aim was to identify clients’ symptoms (k = 1), topics discussed in conversations (k = 5), or conversational patterns (k = 5). In educational contexts, studies aimed to predict the number of teacher questions (k = 5) and the type of classroom activities (e.g., discussion, lecture, or group work, k = 5). Behavioural coding measures and automated coding methods. Many studies used automated coding to implement pre-existing behavioural coding measures. Behavioural coding measures were usually designed to measure adherence to the practice guidelines or instructions. The majority of studies used a behavioural coding measure (for details, see Table 3). The most frequently applied coding measure was Motivational Interviewing Skills Code (k = 14; Miller et al., 2003), followed by the Motivational Interviewing Treatment Integrity measure (k = 7; Moyers, Martin, et al., 2005). Seven studies used a coding system to code whether teachers asked questions, provided instructions, or facilitated small-group activities (Nystrand et al., 2003). In this context, the machine learning methods were designed to automatically assign codes from the behavioural coding measures to overt interactions recorded in the dataset (e.g., words/utterances). Most studies assessed more than one machine learning method; the most frequently applied were Support Vector Machine (k = 8), Random Forests (k = 7), Logistic Regression (k = 7), J48 classifiers (a type of decision tree, k = 6), Maximum Entropy Markov models (k = 5), and Naive Bayes (k = 5; for details, see Table 4). Table 4 Automated Coding Methods 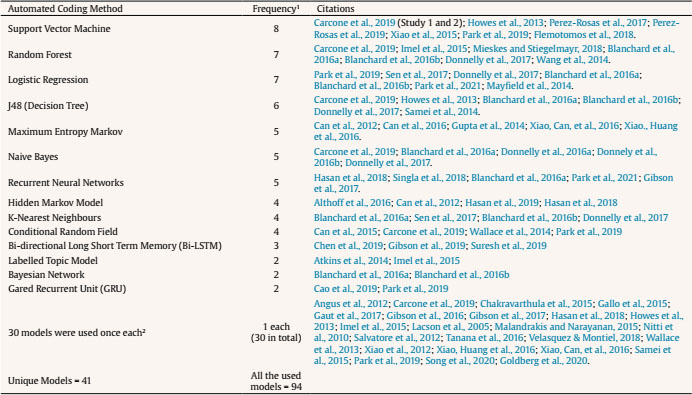 Note. 1Some studies applied more than one coding method. We reported all the specific models that were applied in the studies. Some models might be variations of another model. 2The models were: Activation-based Dynamic Behaviour Model (ADBM) using Hidden Markov Model, AdaBoost, Automated Co-occurrence Analysis for Semantic Mapping (ACASM), Boostexter tool, Deep Neural Networks, DiscLDA, Discourse Flow Analysis (DFA), Discrete Sentence Features using Multinomial Logistic Regression, Discursis software, Fidelity Automatic RatEr (FARE system), Joint Additive Sequential (JAS) model using Log-linear classifier, Labeled Latent Dirichlet Allocation, Lasso Logistic Regression (LLR), Latent Dirichlet Allocation, Likelihood-based Dynamic Behaviour Model (LDBM) using Hidden Markov Model, Linear Regression, Markov Chain, Markov-Multinomial, Maximum Likelihood Classifier with Universal Background Model (UBM) and Kneser-Ney algorithm, Maximum Likelihood Model with Kneser-Ney algorithm, Naive Bayes-Multinomial, RapidMiner, Recurrent Neural Networks with Gated Recurrent Unit (GRU), Recursive Neural Network (RNN), Ridge Regression model, Static Behaviour Model (SBM) using Universal Background Model, Hidden Markov Model Logistic Regression (HMM-LR), Hidden Markov Model-Support Vector Machine (HMM-SVM), Hidden Markov Model-Gated Recurrent Unit (HMM-GRU), Convolutional Neural Network - Bidirectional Long Short Term Memory (CNN-BiLSTM) model. Which methods performed best? In Supplementary file 5, we report the predictive performance of each method (e.g., F1-score measure for the Support Vector Machine in Xiao et al., 2015 is .89). We also reported a brief description of each coding method and accuracy measures in the Supplementary file 1. Methods generally performed well in terms of their agreement with human coders. Overall, kappa ranged from .24 to .66, with all but one study (Samei et al., 2014) falling between .38 and .66. These results suggested fair to excellent levels of agreement, compared with established thresholds for kappa used for human-to-human agreement (Landis & Koch, 1977). Accuracy—meaning the ratio of correctly predicted codes to the total number of predictions—was greater than 50% in all studies and sometimes higher than 80% (e.g., Chakravarthula et al., 2015; Wang et al., 2014; Xiao et al., 2016). Support Vector Machine methods generally performed well. For example, Xiao et al. (2015) found that the Support Vector Machines methods performed almost as well as trained coders. Similar results were reported in other studies (e.g., Flemotomos et al., 2018; Pérez-Rosas et al., 2019; Pérez-Rosas et al., 2017). Most studies only examined one type of method’s performance. In one study that directly compared different methods on the same dataset, Support Vector Machines outperformed seven alternative method strategies in terms of agreement with human coders and accuracy (Carcone et al., 2019). Because few studies examined the performance of methods when transferred to other similar settings—for example, with similar predictors and outcomes but different participants—we are unable to ascertain whether any particular method predicted new data better than others. There were three studies that compared the performance of methods but did not report the predictive performance of all the tested methods and only chose the best performing method (Blanchard et al., 2016a, 2016b; Donnelly et al., 2017). Only one study developed a Support Vector Machine method in psychotherapy and applied it on new data from another context (i.e., medicine; Carcone et al., 2019). The method performed well, achieving a substantial level of agreement with human coding. Larger datasets lead to more accurate performance. Dataset sizes ranged from 13 sessions (Wang et al., 2014) to 1,235 sessions (Goldberg et al., 2020). When the dataset size was larger, methods performed more accurately. For example, Imel et al. (2015) analysed more than 9 million words and the method achieved an accuracy of 87% (using a Random Forest). Similar results were reported in other studies with large datasets (e.g., Gaut et al., 2017; Xiao et al., 2016; Xiao et al., 2015). Pérez-Rosas et al., 2019 showed that as they increased the amount of data in their training set they observed significant improvement in prediction accuracy. Aligned with this finding, frequently observed codes (i.e., categories) in a dataset were predicted more accurately, while low base rate codes were predicted less accurately (e.g., Can et al., 2015; Cao et al., 2019; Carcone et al., 2019; Gibson et al., 2017; Tanana et al., 2016; Wallace et al., 2014). An example of frequently observed code is ‘open questions’ and an example for low base rate codes is ‘confrontational statements’. The fewer the codes the more accurate the performance. Methods classified data into codes, with the number of codes ranging from two (Blanchard et al., 2016a; Xiao et al., 2015) to 89 (Gaut et al., 2017). When the number of codes decreased, performance of the method increased, and vice versa. Carcone et al. (2019) showed that the methods performed better in 17-code prediction than 20-code prediction, and 20-code prediction was superior to 41-code prediction. Similar results were reported in other studies that directly compared coding frameworks of differing complexity (e.g., Gallo et al., 2015; Gibson et al., 2016). When methods were simpler (i.e., two codes), accuracy was greater than 80% (e.g., Blanchard et al., 2016a; Chakravarthula et al., 2015; Gallo et al., 2015; Pérez-Rosas et al., 2019; Xiao et al., 2016). When the number of codes was higher, prediction was less accurate (i.e., accuracy = 54% with 41 codes in Carcone et al., 2019; accuracy = 66% with 20 codes in Howes et al., 2013). More concrete and less abstract codes lead to better performance. The conceptual meaning of the codes affects the predictive performance of methods. Methods accurately predicted some types of codes. For example, questions (e.g., a counsellor or teacher asking questions to gather information, such as “How do you feel about that?”) and facilitation (i.e., simple utterances that function as acknowledgements and a cue to continue speaking, such as “hmm-mm”) seem to be conceptually concrete. These codes were predicted more accurately than conceptual abstract codes, such as empathy (Atkins et al., 2014), confrontation, and advising (Imel et al., 2015; Tanana et al., 2016). Session-level prediction is more accurate than utterance-level prediction. Utterance-level prediction refers to the prediction of a small unit of spoken words that have a specific meaning (i.e., complete thoughts). For instance, “You feel overwhelmed” is an utterance that may signal reflective listening. Session-level prediction refers to the prediction of a behaviour or skill over a session. For example, in Motivational Interviewing Treatment Integrity coding measure, the empathic quality of the provider is rated on a 1-5 Likert scale, taking the entire session or segment of the session into account (Moyers et al., 2016). Session-level prediction may also code whether the therapist implemented a specific behaviour (e.g., reflective listening) frequently (e.g., 10/10) or rarely (0/10). Compared with utterance-level prediction, Tanana et al. (2016) showed that the session-level prediction results had stronger concordance with human-based coding. Atkins et al. (2014), and Park et al. (2019) reported similar results, where the session-level prediction was generally closer to human coding rather than utterance-level prediction. Quality of Reporting Within Studies Results of our study quality assessment can be found in Table 1. Inter-rater reliability analysis of the quality assessment among this systematic review team showed agreement on 89% of the instances assessed by two independent reviewers. We resolved discrepancies by discussion between the two researchers (AA and MS or AA and DA) and consultation with a third reviewer (MN). We report quality assessment results for each item of the core checklist (nine items). All the papers reported the clinical setting, dataset details, and observational units. Forty-five papers (86.5% of studies) coded behaviours using a behavioural coding measure. These types of concrete guidelines facilitate utterance level comparison. Twenty-eight papers reported data pre-processing (53.8% of the studies), which improves performance of a method by removing outliers or poor quality data (e.g., removing very low quality voice recordings; García et al., 2014). Thirty-four papers (64.1% of studies) validated the methods using some form of cross-validation (where a method is trained on a dataset and tested on a unseen set of observations; Browne, 2000). Yet, only eleven papers (21.1% of studies) applied a hold-out ‘train and test’ method. Studies that do not test the accuracy on unseen data can overfit the data to the training set, and give misleading estimates of how accurately the method can predict new data (Yarkoni & Westfall, 2017). Eighteen papers (34.6% of studies) reported success criteria (e.g., mean-squared error), which help to interpret performance of a method. Relative importance of predictor variables (e.g., which feature is most important in predicting the outcome variable) were reported in 19 papers (36.5% of studies). For full details about each quality indicator, see Supplementary file 3. Our systematic review found that several automated coding methods have been applied to assess fidelity in psychological interventions. We also identified many methods used to analyse verbal interactions of other helping professionals, not just therapists. These methods generally demonstrated promising results with accuracy comparable to human coding. Methods performed better on large datasets, coding frameworks with fewer behaviours, and verbal behaviours that represent concrete (rather than abstract) codes. However, studies rarely reported adherence to best-practice machine learning guidelines, meaning that the machine learning models may not generalise well to new interactions with new clients, reflecting a deficit in the field. Methods showed promising performance in automatic annotation of therapists’ verbal behaviour, including treatment fidelity to a number of models (most frequently Motivational Interviewing). This result suggests machine learning could reduce financial costs of traditional methods. Doing so would improve the scalability and efficiency of behavioural coding for assessment and feedback on treatment fidelity. When directly compared with other methods, the Support Vector Machines method showed superior performance and appeared to be an appropriate method for generalisability purposes (Carcone et al., 2019). The higher performance of the Support Vector Machines method was also reported in other studies in the similar applications (Hasan et al., 2016; Kotov et al., 2014). This method might have potential in less-explored contexts such as fidelity for cognitive behaviour therapy or acceptance and commitment therapy, because the machine learning models efficiently process sparse, high-dimensional data and non-linearities with few interactions. Having said that, the field of machine learning is advancing quickly and the methods reported here may not reflect the current state-of-the-art. For example, Kaggle’s machine learning competitions have recently been dominated by Extreme Gradient Boosting or Neural Network methods (Abou Omar, 2018). New, powerful, natural language models contain up to 175 billion parameters and require only a few pieces of training data (Brown et al., 2020). We expect that automated coding methods will become even more powerful, and better-able to manage ambiguity, once researchers start implementing these cutting-edge methods. Our findings were restricted by the small number of studies that directly compared different machine learning methods; therefore, caution should be taken when generalising the predictive performance of these methods to other cases. Researchers in this area could help accelerate the field by transparently reporting which models were tested and discarded, and why. It is common practice in machine learning to test a number of models using cross-validation on the training set (Cawley & Talbot, 2010); we were therefore surprised to see so few head-to-head comparisons reported. It is possible that researchers only reported the performance of a model that performed best with their data. This is concerning because few studies reported how well the models predicted unseen data on a hold-out, ‘test set’ and thus the risk of over-fitting was potentially high. There were rare cases where automated coding methods did not perform well (Gallo et al., 2015; Samei et al., 2014). While the method itself can be an important factor in prediction accuracy, there are important conditional factors, such as dataset size, that affect a method’s accuracy (Yarkoni & Westfall, 2017). Considering these conditions, it was not easy to provide a fair comparison between statistical models because the choice of model was often confounded by differences in samples and prediction objectives. In the following section, we present a cautious overview of the factors that influence the methods’ predictive performance and provide suggestions for future research and practice. While determining the appropriate size of a dataset remains a matter of debate, large datasets support training, testing, and generalization of predictions in new datasets (Yarkoni & Westfall, 2017). Future studies could identify whether or not more data are needed by looking at the learning curves, which show whether the method can be adequately fit with the data available (Perlich, 2009). In general, our results showed that larger datasets lead to better performance. This finding is in line with previous studies where machine learning algorithms generally performed better on larger datasets (Domingos, 2012). It is important to note, however, that additional data have diminishing returns. As such, it is important for analysts to monitor method performance as sample sizes increase in order to maintain reasonable cost-benefit ratios (Ng, 2019). Another factor influencing methods’ performance is the number of codes a method is built to predict. Methods generally performed worse when the number of codes increased (e.g., Gallo et al., 2015; Hasan et al., 2016). As such, we recommend analysts carefully consider which codes are most critical as a means of increasing method performance. When learning curves indicate that data is under-fit, then authors could consider using fewer codes (e.g., by collapsing conceptually similar codes) to allow for more reliable methods. Codes with simple conceptual meaning were predicted more accurately (e.g., open-ended questions), while complicated codes were predicted weakly (e.g., informing with permission from the client vs. informing without permission). Researchers might consider the trade-off between the lower prediction accuracy for complicated codes and the higher costs of coding them using alternative methods (e.g., manual coding). Similarly, codes that can be objectively identified in a transcript (e.g., questions, affirmations, and facilitations) are likely to be more easily coded than those that require inference and subject-matter expertise. Many accurate methods in this review were applied in the Motivational Interviewing context. The behavioural coding systems for Motivational Interviewing are well defined and more reliably coded than many other therapeutic approaches (Miller & Rollnick, 1991). This may be because Motivational Interviewing explicitly prescribes a number of conversational devices (e.g., reflections, affirmations, open questions) to be used in session, where other practices are less prescriptive regarding the conversation process and more focused on the content of discussion (e.g., a client’s idiosyncratic negative automatic thoughts). Similarly, the techniques prescribed by motivational interviewing may occur hundreds of times a session (e.g., reflective listening). Core techniques from other treatment approaches may only happen once per session (e.g., checking homework). As a result, machine learning methods may be less reliable where behavioural codes are less clear, like in other psychological treatment approaches (e.g., cognitive-behaviour therapy). Finally, methods tend to perform poorly when codes are constructed at the utterance-level; the overall prediction of a code was more reliable over a session. Part of the reason for this arises from the difficulty of utterance-level coding tasks—even for human coders—if they do not rely on the prior or subsequent utterances (Tanana et al., 2016). Without context, it is difficult to know whether “your drinking is a problem” is an empathic response to a client’s self-awareness or a controlling, unsolicited prescription. As a result, it is more reasonable to rely on the overall prediction results over a session rather than each individual utterance. Recently, Cao et al. (2019) investigated the prediction of therapist utterance labels by taking the context of the utterance into consideration. They found that by increasing the history window size (i.e., by accounting for the last 8 utterances), categorization accuracy improved (Cao et al., 2019). This indicates that providing machine learning with more context may improve the accuracy of models. The other reason for poor performance at utterance-level prediction compared to session-level prediction may be that, across a session, the machine-learning task is closer to a regression problem than a classification problem. That is, it may be hard to classify a moment as ‘empathic’ from a set of words, but it may be easier to correlate ratings of empathy with the frequency of specific words across an entire session (e.g., “you feel…”, “it sounds like…”). Atkins et al. (2014) presented the potential factors impacting the accuracy of Topic Models in predicting client and therapist codes in the Motivational Interviewing Skill Code. Like our review, they argued that models worked less accurately at utterance (i.e., talk-turn) level than at session level. They also stated that more abstract codes were weakly predicted than more concrete ones. However, their findings only focused on one of the many psychosocial interventions (motivational interviewing), and our systematic review identified other factors which are likely to influence the performance of machine learning methods. Particularly, this systematic review showed that larger datasets and more frequently observed codes lead to better prediction accuracy. Also, fewer target behaviours leads to higher accuracy. Further, other factors impact the predictive power of a model, such as the machine learning model selection process, pre-processing, and validation method. Potential Applications Specific and immediate feedback is essential to the development of skills across domains (Kahneman & Klein, 2009). Feedback works best when it is provided several times, spaced over a period of time (Ivers et al., 2012). However, providing individualised, distributed, and prompt feedback multiple times for a big group of therapists can be prohibitively expensive. Automated coding methods showed promising results in analysing helping professionals’ language, so they can be used to provide feedback and improve practitioners’ skills. Our systematic review shows that automated coding methods provided accurate estimation of treatment fidelity, including all three components (adherence, differentiation, and competence; Rodriguez-Quintana & Lewis, 2018). In motivational interviewing, for example, automated methods were able to code adherence to therapeutic strategies (e.g., affirming change), differentiation of proscribed strategies (e.g., use of closed questions; Tanana et al., 2016), and competence in delivery (e.g., session-level empathy ratings; Gibson et al., 2016). Specific, prompt feedback on all three of these may be useful for therapists. In the medical care setting, automated coding methods identified conversation patterns and discussed symptoms. In the education context, automated coding methods successfully predicted the number of questions teachers asked and the types of class activity they set. These automated methods are well tolerated (Skipp & Tanner, 2015). Imel et al. (2019) used automated coding methods to provide prompt feedback on therapists’ performance in a laboratory setting. Therapists found the provided feedback representative of their performance and easy to be understood. Psychologists were shown to be more receptive to computerised feedback than from a supervisor (Hirsch et al., 2018; Imel et al., 2019). We are aware of only a few commercially available tools for assessing the fidelity of psychosocial interventions. For example, Atkins and colleagues deployed models (Imel et al., 2015; Tanana et al., 2016; Xiao et al., 2015) for automatic coding of therapy sessions including CBT and motivational interviewing (Tanana, 2021). However, the dearth of publicly available tools reveals an opportunity for better collaboration between research and industry and improved knowledge translation. From a research perspective, machine learning may allow for more affordable, reliable, scalable assessments of treatment fidelity. There is a substantial outlay in the initial annotation of therapy transcripts, but once this annotation is complete for a large trial, the data can be easily used to assess fidelity in other trials. The heterogeneity in fidelity assessment tools does add another level of difficulty for many modalities, like cognitive behavioural therapy, acceptance and commitment therapy, or interpersonal psychotherapy. If studies continue to use different assessments of treatment fidelity, then the generalisability of the machine learning models will be small. If the research community for each of these therapies agreed upon a set of core principles of change that were observable in therapy, then more annotated data would be available to train automated fidelity assessments for these therapies. In health, a number of Delphi studies have been conducted that allowed experts to reach consensus on both a-theoretical and theory-driven strategies (Michie et al., 2013; Teixeira et al., 2020). Using these taxonomies, or more consistent use of a smaller number of fidelity assessment (e.g., Motivational Interviewing Skill Code; Miller et al., 2003; Motivational Interviewing Treatment Integrity; Moyers, Martin, et al., 2005), does lay the platform for machine learning methods of automated coding. This research, however, needs to be careful to build models that perform well on future data, not just the data included in the original study. Assessing model fit on new data is a primary difference between predictive methods (i.e., machine learning) and more traditional explanatory modelling in research contexts (Breiman, 2001). Decision-rules that work in one dataset may not work with future data. For example, Google Flu Trends was able to predict historial flu rates from their search data, but it failed to accurately predict future data because methods became too sensitive to noise in the historical data (Lazer et al., 2014). To avoid these traps, machine learning experts identified a set of best-practice guidelines (Luo et al., 2016), which we used to evaluate studies. Our review found that few studies met these criteria. For example, guidelines recommend using a section of available data to refine the method (e.g., 70% of participants), but new data (e.g., 30% of participants), not used to refine the method, should be used for testing the final method (Luo et al., 2016; Yarkoni & Westfall, 2017). Only 21.1% of studies tested their methods on hold-out data. This is despite testing methods on novel data being an essential measure of method performance in machine learning. Six studies (11.1%) did not report how they refined their method at all (i.e., the validation process). Without transparently reporting these processes, readers cannot assume that machine learning methods will work on future data. Similarly, 46.2% of studies did not report if or how they undertook pre-processing of data. Pre-processing involves the cleaning and rescaling of data which usually occurs before training the method (García et al., 2014). Without these details, methods are not reproducible. While the general conditions of the studies were reported (e.g., where authors got the data and how much data they had), future predictive methods will be more useful, accurate, and generalisable if studies adhere to best-practice guidelines. Limitations The studies in this review used a wide variety of accuracy measures, behavioural coding measures, and outcomes which made it difficult to compare the methods. We could have calculated a common metric with a confusion matrix. Confusion matrices represent the predictive results of each code in utterance level (i.e., how many utterances predicted correctly or incorrectly), but only nine studies (three studies in psychotherapy and six studies in education) reported such a matrix. Another limitation was that treatment is a collaborative dialogue, but we only analysed the helping professionals’ language. Some studies analysed both helping professionals’ and clients’ language, and methods that predicted both may be useful for clinicians and researchers to assess fidelity (e.g., did the technique produce the desired outcome). Also, predictive performance of a method might be different when analysing the clients’ language, so future reviews could assess the methods used to automatically annotate client/patient language. Similarly, we excluded studies that only focused on signal-processing models of para-verbal behaviour, or object-classification models of non-verbal behaviour from video. Both non-verbal and para-verbal behaviour are important components of therapy, particularly with respect to common factors like therapeutic alliance. Future reviews may want to assess whether models involving those features perform well in therapeutic environments. We also excluded studies that exclusively coded patient behaviour, though many patient behaviours (e.g., change-talk in motivational interviewing; Tanana et al., 2016) are indicators of therapist fidelity. Reviews that focus on patient indicators of quality therapy may be helpful complements to our review here. We included a broad range of helping professions to try and promote knowledge crossover between related fields; however, doing so may mean approaches described here do not generalise. The models that have been used in education or medicine might not perform equally well in other settings and vice versa. Even within the field of psychotherapy, models that work well on one therapeutic intervention (e.g., motivational interviewing) may not perform well for other interventions (e.g., cognitive-behaviour therapy). Finally, our search may have missed some grey literature or publications in other languages. While we searched our chosen databases for grey literature, we did not systematically search other websites for potential papers to include. Similarly, while we did not exclude any full-texts on the basis of language, our search terms were in English, meaning we may have missed important contributions that were indexed in other languages. The authorship team of this systematic review are fluent in the other languages (e.g., German, Mandarin) and when automated translation tools (e.g., Google Translate) did not suffice, those authors helped with full-text screening. In the cases where our authorship team was not able to read the full-text, we got help from other members of our institute who were fluent in that language. However, we used comprehensive search terms and MeSH headings, ran the search in the major databases, did forward and backward searching, and sent enquiry emails to related researchers. Still, the techniques encompassing ‘machine learning’ with researchers around the world are often shared without peer review, so it is possible we missed some papers that may have been eligible. Conclusions The results of this systematic review have implications for both research and practice. While more work is needed to reveal what methods work best in which circumstances, our systematic review showed that machine learning is a promising tool for assessing treatment fidelity, promoting best-practice in psychological interventions (Bellg et al., 2004). Therefore, organisations and agencies may be able to use these methods to provide prompt feedback, conduct research, and scale up training to improve therapists’ work. We have also shown that automated methods are most likely to be accurate on session level prediction with larger datasets, fewer number of codes and conceptually concrete codes. Finally, we provided recommendations for a minimal list of considerations when developing generalisable machine learning models for treatment fidelity. In sum, machine learning shows promise as a way of decreasing barriers to assessment and feedback for treatment fidelity. Doing so can improve scientific progress by improving the consistency of interventions being studied, but also improve service delivery, ensuring clients receive effective treatments that have been validated through rigorous research. Conflict of Interest The authors of this article declare no conflict of interest. Supplementary data Supplementary data are available at https://doi.org/10.5093/pi2021a4 Cite this article as: Ahmadi, A., Noetel, M., Schellekens, M., Parker, P., Antczak, D., Beauchamp, M., Dicke, T., Diezmann, C., Maeder, A., Ntoumanis, N., Yeung, A., & Lonsdale, C. (2021). A systematic review of machine learning for assessment and feedback of treatment fidelity. Psychosocial Intervention, 30(3), 139-153. https://doi.org/10.5093/pi2021a4 |
Cite this article as: Ahmadi, A., Noetel, M., Schellekens, M., Parker, P., Antczak, D., Beauchamp, M., Dicke, T., Diezmann, C., Maeder, A., Ntoumanis, N., Yeung, A., & Lonsdale, C. (2021). A Systematic Review of Machine Learning for Assessment and Feedback of Treatment Fidelity. Psychosocial Intervention, 30(3), 139 - 153. https://doi.org/10.5093/pi2021a4
michael.noetel@acu.edu.au Corresponding author: michael.noetel@acu.edu.au (M. Noetel)Copyright © 2026. Colegio Oficial de la Psicología de Madrid






 PDF
PDF e-PUB
e-PUB Supplementary files
Supplementary files CrossRef
CrossRef JATS
JATS Print
Print Send
SendEMAIL ALERT
Psychosocial Intervention is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License







