


The Efficacy of Using Countermeasures in a Model Statement Interview
[La eficacia del uso de contramedidas en una entrevista de declaraciĂłn modelo]
Aldert Vrij1,a, Sharon Leal1,a, Ronald P. Fisher2,a, Samantha Mann1,a, Haneen Deeb1,a, Eunkyung Jo3,a, Claudia Castro Campos4,a, and Samer Hamzeh5,a
1University of Portsmouth, UK; 2Florida International University, Miami, USA; 3Dongguk University, Seoul, South Korea; 4Universidad Autonoma de Nuevo Leon,Monterrey, Mexico; 5Modern University for Business & Science, Beirut, Lebanon
https://doi.org/10.5093/ejpalc2020a3
Received 5 September 2019, Accepted 5 November 2019
Abstract
In a countermeasures experiment, we examined to what extent liars who learn about the Model Statement tool and about the proportion of complications (complications/complications + common knowledge details + self-handicapping strategies) can successfully adjust their responses so that they sound like truth tellers. Truth tellers discussed a trip they had made; liars fabricated a story. Participants were of Lebanese, Mexican, and South-Korean origin. Prior to the interview they did or did not receive information about (i) the working of the Model statement and (ii) three types of verbal detail: complications, common knowledge details and self-handicapping strategies. We found no evidence that liars sounded like truth tellers after being informed about the Model Statement and/or types of detail we examined. Actually, veracity differences were similar across experimental conditions, with truth tellers reporting more detail and more complications and obtaining a higher proportion of complications score than liars.
Resumen
En un experimento de contramedidas examinamos hasta qué punto los mentirosos que reciben información sobre la Declaración modelo y la proporción de complicaciones que presenta (complicaciones / complicaciones + detalles de conocimiento general + estrategias de autoobstaculización) pueden ajustar sus respuestas con éxito para que parezca que dicen la verdad. Los que dicen la verdad declararon sobre un viaje que habían hecho; los mentirosos inventaron una historia. Los participantes eran de origen libanés, mexicano y surcoreano. Antes de la entrevista habían recibido o no información sobre (i) el funcionamiento de la Declaración modelo y (ii) tres tipos de detalles verbales: complicaciones, detalles de conocimiento general y estrategias de autoobstaculización. No encontramos evidencia de que los mentirosos se parecieran a los que dicen la verdad después de ser informados sobre la Declaración modelo y los tipos de detalle que examinamos. En realidad, las diferencias de veracidad fueron semejantes en todas las condiciones experimentales: los que decían la verdad informaron con mayor detalle y de más complicaciones y obtuvieron una mayor puntuación en la proporción de complicaciones que los mentirosos.
Keywords
Countermeasures, Information gathering, Deception, Model statement, Proportion of complicationsPalabras clave
Medidas correctivas, Recopilación de información, Engaño, Declaración modelo, Proporción de complicacionesCite this article as: Vrij, A., Leal, S., Fisher, R. P., Mann, S., Deeb, H., Jo, E., Campos, C. C., & Hamzeh, S. (2019). The Efficacy of Using Countermeasures in a Model Statement Interview. The European Journal of Psychology Applied to Legal Context, 12(1), 23 - 34. https://doi.org/10.5093/ejpalc2020a3
aldert.vrij@port.ac.uk Correspondence: aldert.vrij@port.ac.uk (A. Vrij)The Efficacy of Using Countermeasures in a Model Statement Interview Deception research has shown that cues to deceit are typically faint and unreliable (DePaulo et al., 2003). In response to this, researchers have started to examine whether cues to deceit could be enhanced or elicited through specific interview protocols (Vrij & Granhag, 2012). They also have started to examine verbal cues to deception not previously examined before (Nahari, 2018; Vrij, Leal, Jupe, & Harvey, 2018). This resulted in interview protocols such as the Model Statement tool (Leal, Vrij, Warmelink, Vernham, & Fisher, 2015; Vrij, Leal, & Fisher, 2018) and in new verbal cues, such as the proportion of complications (Vrij, Leal, Jupe et al., 2018). In the current experiment, we addressed the extent to which the Model Statement tool and the proportion of complications are vulnerable to countermeasures. That is, to what extent can a liar who learns about the Model Statement tool and about the proportion of complications successfully adjust her/his responses so that s/he sounds like a truth teller? Research examining the Model Statement tool and the proportion of complications has been published and is accessible to everyone through the internet. In addition, practitioners have started to use the Model Statement tool and examine the proportion of complications in investigative interviews (Vrij, Leal, & Fisher, 2018). The Model Statement tool is part of Cognitive Credibility Assessment (Vrij, Fisher, & Blank, 2017). A Model Statement is an example of a detailed account unrelated to the topic of the interview (Leal et al., 2015). A Model Statement raises the expectations amongst both truth tellers and liars about how much information they should provide (Ewens et al., 2016). As a result, both truth tellers and liars provide more details after listening to a Model Statement and do this to a similar extent (Vrij, Leal, & Fisher, 2018). However, the type of detail provided by truth tellers and liars seems to differ. After being exposed to a Model Statement, truth tellers reported more complications (an occurrence that makes a situation more difficult) than liars (Vrij, Leal et al., 2017; Vrij, Leal, Jupe, & Harvey, 2018). Many deception studies focus on the total amount of information provided by the interviewee. This variable often discriminates truth tellers from liars, with truth tellers typically reporting more details than liars (Amado, Arce, Fariña, & Vilarino, 2016). However, total amount of information is a generic measure that does not take well enough into account the different verbal strategies truth tellers and liars employ. Vrij and colleagues (Vrij, Leal et al., 2017; Vrij, Leal, Fisher, Mann et al., 2018; Vrij, Leal, Jupe et al., 2018; Vrij, Leal, Mann et al., 2018; Vrij et al., 2019) started to break down this generic measure (total amount of information) into components that they believed to be more sensitive to the different verbal strategies used by truth tellers and liars: complications (e.g., “The air conditioning was not working properly in the hotel”), common knowledge details (strongly invoked stereotypical knowledge about events, e.g., “We visited the Louvre museum where we saw the Mona Lisa”), and self-handicapping strategies (justifications as to why someone is not able to provide information, e.g., “Nothing unexpected happened; I am a very organised person”). Across experiments, truth tellers reported more complications than liars, whereas liars reported more common knowledge details and self-handicapping strategies than truth tellers. The proportion of complications, complications / (complications + common knowledge details + self-handicapping strategies), was also higher for truth tellers than liars and was a more diagnostic tool to distinguish truth tellers from liars than ‘total amount of information’ (Vrij, Leal et al., 2017; Vrij, Leal, Fisher, Mann et al., 2018; Vrij, Leal, Jupe et al., 2018; Vrij, Leal, Mann et al., 2018; Vrij et al., 2019). Several studies in the verbal lie detection domain have examined the extent to which verbal lie detection techniques are vulnerable to countermeasures. This seems to depend on the technique examined. First, the Verifiability Approach (Nahari, 2018; Nahari & Vrij, 2019; Vrij & Nahari, 2019). The core of this approach is that truth tellers are more likely than liars to report details that someone can check (e.g., “When I entered the cinema, I walked into my friend Fred’). The Verifiability Approach was resistant to countermeasures (Nahari, Vrij, & Fisher, 2014). In fact, informing truth tellers and liars about the working of the Verifiability Approach (i.e., informing interviewees that the investigator would like to hear details s/he can check) actually increased the difference between truth tellers and liars in reporting verifiable details, because this information enticed truth tellers to report more additional verifiable details than liars (Vrij & Nahari, 2019). Second, the Strategic Use of Evidence (SUE) technique. The core of the SUE technique is that during interviews truth tellers are generally forthcoming, whereas liars are inclined to be avoidant or to use denials (e.g., denying having been at a certain place at a specific time when asked directly; Granhag & Hartwig, 2008). When investigators ask questions related to the evidence without making the interviewee aware that they possess this evidence, these different strategies used by truth tellers and liars result in truth tellers’ accounts being more forthcoming and therefore more consistent with the available evidence than liars’ accounts (Hartwig, Granhag, & Luke, 2014). The SUE technique was to some extent resistant to countermeasures (Luke, Hartwig, Shamash, & Granhag, 2016). Liars who were informed about the SUE technique were more verbally forthcoming (i.e., admitting to more critical details about their activities) than uninformed liars, but they were still less forthcoming than truth tellers. Third, Criteria-Based Content Analysis (CBCA) (Amado, Arce, & Fariña, 2015; Köhnken & Steller, 1988; Volbert & Steller, 2014). CBCA comprises 19 criteria which are thought to be more often present in truthful than in deceptive accounts for cognitive and motivational reasons (Köhnken, 1996, 2004). Several criteria are more likely to occur in truthful statements than in fabricated statements because it is thought to be cognitively too difficult for liars to fabricate them. Others are more likely to occur for motivational reasons. Liars will be keener than truth tellers to try to construct a report that they believe will make a credible impression on others, and will leave out information that, in their view, will damage their image of being a sincere person. CBCA was vulnerable to the use of countermeasures. Liars who were informed about several CBCA criteria did provide verbal responses that sounded similar to those of truth tellers (Vrij, Kneller, & Mann, 2000). The difference between VA and SUE, on the one hand, and CBCA, on the other hand, is that VA and SUE focus on case evidence whereas CBCA does not. That is, VA examines which information provided by an interviewee can be verified and SUE compares the provided information with the available evidence. In contrast, CBCA examines the quality of a statement and assumes that some details are unlikely to be reported by liars. It is more difficult for liars to fabricate a statement that is congruent with the available evidence than it is to fabricate a statement that includes types of detail assumed to be reported by truth tellers. Similar to CBCA criteria, complications, common knowledge details, and self-handicapping strategies are types of detail that reflect the quality of the answers provided. Since CBCA details are vulnerable to countermeasures, it could be that complications, common knowledge details, and self-handicapping strategies are also vulnerable to countermeasures, and perhaps even more so when interviewees are informed about the Model Statement tool as that relates to the amount of information interviewees are expected to provide. We thus predict that if liars will be able to use countermeasures effectively in a Model Statement interview (i.e., produce verbal responses that sound similar to truth tellers’ responses), this is most likely to happen when they are informed about (i) the types of detail examined and (ii) the amount of information they are supposed to give. This study, including this hypothesis, is pre-registered at https://osf.io/s68vx/.1 Deception research has typically been conducted in the United States and Western Europe (Vrij, 2008). However, practitioners frequently ask us whether the research findings apply in different cultures. To answer this question, research outside the US and Western Europe is required (Leal et al., 2018). In the present experiment, we recruited participants in Lebanon, Mexico, and South-Korea. Design In the present article, we analysed the data in two different ways. First, we carried out analyses of variance using a 2 (veracity) x 2 (Model Statement pre-informed) x 2 (types of detail pre-informed) between-subjects design focusing on the unique details provided in the entire interview (i.e., details provided in the initial recall plus new details provided in the second recall). The dependent variables were the total number of details, complications, common knowledge details, and self-handicapping details provided as well as the proportion of complications. Recently, Vrij and colleagues proposed to use the Model Statement tool as a within-subjects tool, that is, to make comparisons within a single interviewee by comparing different parts of his/her statement (Vrij, Leal, & Fisher, 2018; Vrij, Leal, Jupe et al., 2018). Within-subjects tools are thought to be more applicable than between-subjects tool because they control for individual differences, such as differences in being talkative or eloquent (Vrij, 2016). Vrij and colleagues suggested to start the interview by eliciting an initial free recall, then to play a Model Statement followed by a second free recall. They further recommended to focus on the second free recall and examine the amount of new details and types of new detail elicited in the second free recall (details not provided in the initial recall). Reflecting this suggested method we also carried out a 2 (veracity) x 2 (Model Statement pre-informed) x 2 (types of detail pre-informed) analysis of variance, focusing on the new details provided in the second recall only. A consistent finding in the deception literature is that liars prepare themselves more for interviews than truth tellers (Colwell, Hiscock-Anisman, Memon, Woods, & Michlik, 2006; Hartwig, Granhag, & Strömwall, 2007; Vrij, Mann, Leal, & Granhag, 2010). This could also apply to reading about interview protocols and types of detail that practitioners examine. In an additional set of analyses, we took this difference between truth tellers and liars into account and compared the responses of uninformed truth tellers with those of informed liars. To do this, an analysis of variance was conducted with veracity as the only factor and this veracity factor had four levels: (i) uninformed truth tellers, (ii) liars informed about the Model Statement, (iii) liars informed about the types of detail, and (iv) liars informed about the Model Statement and the types of detail. Participants A total of 201 University students (80 males and 111 females, 10 unknown) took part in the study. Their age ranged from 17 to 43 years with an average age of M = 21.57 years (SD = 2.99). The experiment took place in three different universities in Lebanon, Mexico, and South Korea and the participants were of Lebanese (n = 56), Mexican (n = 65), and Korean (n = 80) origin. A post hoc power analysis was conducted via GPower software. The analysis showed that for a small to medium effect size of f2 = 0.14 (based on the effect sizes in Table 1; Cohen’s d was converted to f) and six dependent variables (details, complications low, complications medium/high, common knowledge details, self-handicapping strategies, and proportion of complications), the study had good power (1.00). Table 1 Statistical Results as a Function of Veracity 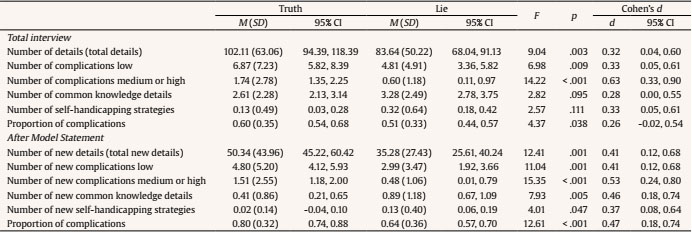 Procedure Recruitment, pre-condition selection form, preparation, and pre-interview questionnaire. We used the same procedure as Vrij, Leal et al. (2017), Vrij, Leal, Fisher, Mann et al. (2018), Vrij, Leal, Mann et al. (2018), and Vrij et al. (2019). Some parts of the description of the Procedure were taken from Vrij et al. (2019) word by word. All materials in the study (recruitment material, selection form, (de)briefing forms, questionnaires, countermeasures material, the audiotaped model statement) were provided in the participants’ native language. Translations were carried out by native speakers familiar with the relevant deception literature. Participants were recruited via an advert on the university intranets and advertisement leaflets distributed in university buildings. The advert explained that the experiment would require participants to tell the truth or lie about a trip away that they may (or may not) have taken within the last year. We decided upon “within the last year” so that truth tellers would still remember many details about their trip and liars could not easily feign memory loss when answering the questions. After reading a participant’s information sheet and signing an informed consent form, participants completed a selection form that contained six cities that the researchers thought the participants may have visited during the past year. (Different cities were used for the three different countries.) The six cities were included on the selection form so that we would obtain some kind of standardization of the cities discussed in the study. The participants were also asked to write down the names of two other cities they had visited during the past year. We did so because if truth tellers had not been to any of the six cities mentioned on the selection form in the past twelve months, they could discuss one of these two additional cities in the interview. For each city the participants indicated (a) whether they had been there during the last twelve months, (b) when they had been there during the last twelve months, (c) for how long they stayed there, and (d) whether they have lived there. For truth tellers, the experimenter selected one of the six cities where the participant had stayed during the last twelve months for at least two nights but had never lived there. If truth teller had stayed in only one of those six cities, that particularly city was chosen. If a truth teller had stayed in more than one of these six cities the experimenter chose a city, ideally one that had not been discussed by (too) many truth tellers before so that we would obtain a variety of cities being discussed. If a truth teller had not been to any of the six cities, the experimenter selected one of the additional cities that the truth teller had listed on the selection form. Truth tellers were informed that they would be interviewed about this selected city (city X) and asked to answer the questions truthfully. For liars, the experimenter selected either one of the six cities on the selection form where the liar had never been in his/her life before, or selected a city not on the list but which was discussed by a truth teller during an interview (after checking that the liar had never been to this city before). Therefore, the truth tellers’ and liars’ cities were matched. Liars were informed that they would be interviewed about city X and that they had to pretend to have stayed there for at least two nights during a trip made during the last twelve months. Across all 97 truth tellers, 31 cities were used. Each truth teller reported a trip to a single city (rather than to multiple cities). The cities liars discussed were taken from this sample of 31 cities. Participants were then given a computer with internet access and told they had twenty minutes to prepare themselves for their interview, or to inform the experimenter if they were ready before that time. The participants were told that they were allowed to make notes while doing their research. They were also told that it was important to be convincing because, if they did not appear convincing, they would be asked to write a statement about what they told the interviewer in the interview. After preparing for their interview, participants were allocated to the Model Statement Information and Types of Detail Pre-Informed conditions. Those allocated to the Model Statement Pre-Informed Absent condition were not informed about the Model Statement, whereas those allocated to the Model Statement Pre-Informed Present condition were given an information sheet about the Model Statement. The information was taken from the article in which the Model Statement was introduced (Leal et al., 2015) and from an article in which the technique was summarised (Vrij, Fisher et al., 2017). In sum, the provided information informed readers what the Model Statement is (an audiotaped account of a detailed report) and its aim (to encourage interviewees to say more). It did not contain information about complications, common knowledge details, and self-handicapping strategies or about using the Model Statement as a within-subjects lie detection tool (Leal et al., 2015 and Vrij, Fisher et al., 2017 do not discuss these two issues either). The full information sheet is provided in the Appendix. Participants allocated to the Types of Detail Pre-Informed Absent condition were not given information to read about complications, common knowledge details, and self-handicapping strategies, whereas participants allocated to the Types of Detail Pre-Informed Present condition were. They read parts of Vrij, Leal, Jupe et al. (2018), an article that focused entirely on these three variables. In sum, the provided information and gave definitions and examples of these three variables and how they are related to deception. The Model Statement tool was not mentioned in the information sheet. In their article, Vrij, Leal, Jupe et al. (2018) discuss the Model Statement as a within-subjects lie detection tool but this information was not given to participants. The full information sheet is provided in the Appendix. In a pre-interview questionnaire, written in a participant’s native language, participants rated their thoroughness of preparation via three items: (1) shallow to (7) thorough; (1) insufficient to (7) sufficient; and (1) poor to (7) good. The answers to the three questions were averaged (Cronbach’s alpha = .90) and the variable is called ‘preparation thoroughness’. Participants were also asked whether they thought they were given enough time to prepare themselves with the following question: “Do you think the amount of time you were given to prepare was (1) insufficient to (7) sufficient?”. Finally, participants were asked how motivated they were to perform well during the interview: (1) not at all motivated to (5) very motivated. Experimental conditions. Participants were allocated randomly to one of the eight experimental cells. A total of 97 participants were allocated to the truth condition and 104 to the lie condition; 100 to the Model Statement Pre-Informed Absent condition and 101 to the Model Statement Ore-Informed Present condition; 100 to the Types of Detail Pre-Informed Absent condition; and 101 to the Types of Detail Pre-Informed Present condition. Individual cell sizes varied from 24 to 25. In total ten interviewers were used. The interviewers were native to Lebanon, Mexico, and South-Korea and the interviews took place in their native countries in the native languages. Nationality is therefore confounded with the specific interviewer. To control for the possible effects of this confound, we included “site” as a covariate in the hypotheses-testing analyses. The interview. Prior to the interview, the experimenter told the interviewer about which city to interview the participant. To make the interviewee feel comfortable and to avoid floor effects in establishing rapport interviewees were offered a glass of water from the interviewer, as offering something helps rapport building (reciprocation principle; Cialdini, 2007). The interviewer started by saying “I will interview you about your trip to ________. Depending on your answers, we may decide to interview you a second time.” This was followed by the following two questions: “Please tell me in as much detail as possible everything you did to plan this trip, e.g., organising transportation, accommodation, what to visit and so on” and “Please tell me in as much detail as possible everything you did when you were at _________ from the moment you arrived to the moment you left.” The two questions were always asked in this order. After finishing the second answer the interviewer said: “Thank you, I would like to ask you the questions once more, but this time, before doing so, I am going to play you a model statement to give you an example of how much detail I would like you to include in your responses.” The interviewer then played the audiotaped Model Statement used by Leal et al. (2015). It was a 1.30 minute long, detailed account of someone attending a Formula 2 motor racing event. The account was a spontaneous, unscripted, recall of an event truly experienced by the person. This Model Statement was followed by the same two questions as asked before the Model Statement, again always in the same order (the question about planning of the trip first). The interviews were audio recorded. The Arabic, Spanish, and Korean text was transcribed and then translated into English. Post-interview questionnaire. After the interview, participants completed a post-interview questionnaire, which was again written in a participant’s native language. Participants were asked to indicate the extent to which they told the truth during the interview on an 11-point Likert scale ranging from 0% to 100%. Rapport was measured via the nine-item Interaction Questionnaire (Vallano & Schreiber Compo, 2011). Participants rated the interviewer on 7-point scales ranging from 1 = not at all to 7 = extremely on nine characteristics such as smooth, bored, engrossed, and involved (Cronbach’s alpha = .65). Participants were subsequently asked the following four questions about the aim of the Model Statement: (i) the model statement made me realise that my initial answers were not detailed enough; (ii) the model statement made me realise that my initial answers were too detailed; (iii) I think the aim of the model statement is to encourage me to say more; and (iv) I think the aim of the model statement is to encourage me to say less. Answers were given on 7-point Likert scales ranging from 1 = not to all to 7 = very much so. Participants were also asked how they thought complications, common knowledge details, and self-handicapping strategies were associated with deception by answering multiple-choice questions. For complications, the participants were asked: “Truth tellers typically report more complications than liars.” The possible answers were: (i) true, (ii) false, and (iii) I don’t know. Similar questions were asked for common knowledge details and self-handicapping strategies. No definitions of complications, common knowledge details, and self-handicapping strategies were given. Participants in the Model Statement Information present condition were asked the extent to which they had read the information about the Model Statement by answering the following question: “How thoroughly did you read the information about the model statement?. Participants in the Types of Detail Information present condition were asked: “How thoroughly did you read the information about complications, common knowledge details, and self-handicapping strategies?”. Answers were given on 7-point Likert scales ranging from 1 = not at all to 7 = thoroughly. Participants in the Model Statement Information present condition were also asked the extent to which they had understood the information about the Model Statement by answering the following question: “Do you think you fully understood the information you read about the model statement?”. Participants in the Types of Detail Information present condition were asked: “Do you think you fully understood the information you read about complications, common knowledge details and self-handicapping strategies?”. Answers were given on 7-point Likert scales ranging from 1 = not at all to 7 = definitely. Coding Detail. The coders, blind to the Veracity and Countermeasures conditions, were taught the coding scheme by the first author who had more than twenty years of experience in coding detail. Coding occurred on the English transcripts. A coder first read the transcripts and coded each detail in the interview. A detail is defined as a non-redundant unit of information about the trip the interviewee allegedly had made. For example, the following answer has six details: ‘I didn’t bring my slippers, so my feet were so hot that I walked faster’. Each detail in the interview was coded only once; thus repetitions were not coded. A second coder coded a random sample of 40 transcripts. Inter-rater reliability between the two coders, using the two-way random effects model measuring consistency, was good (single measures ICC = .72). One coder coded the following measures in all transcripts: complications, common knowledge details, and self-handicapping strategies. Repetitions were not coded. A complication is an occurrence that affects the story-teller and makes a situation more difficult. It differs from the CBCA criterion 7 ‘unexpected complications’ because in our definition something does not have to be unexpected to be a complication. Thus, if someone says that s/he flew from London to Ottawa via Toronto, the person describes a complication in our definition but not in the CBCA’s definition. Although complications can range in the degree of complexity, this distinction has never been made in research to date. We decided to make a distinction between complications low in complexity versus other complications (medium/high) to explore whether liars are inclined to report complications low in complexity. Example of complications-low are: (a) “There weren’t many buses running so we took a taxi”; (b) “At breakfast there weren’t enough seats, which really annoyed me”; and (c) “My friend was worried because the plane was shaking quite hard”. Examples of complications-medium/high are (d) “The bus went up a very steep slope until it couldn’t go further; we got off from the bus and walked over the hill”; (e) “On the bus an old man said ‘don’t hold hands’ and hit our hands with an umbrella, ‘don’t you have any public manners?’, so, we got off the bus and took the next one”; and (f) “I said to my mum ‘if you forced me to go to Gyeongju, I’d go back to Seoul’; then mum got really angry and screamed ‘are you joking on me?’, I cried and said that I was really stressed out; I told her that I came to Pohang to release stress not to get more stress”. Common knowledge details refer to strongly invoked stereotypical knowledge about events (Vrij, Leal, Jupe et al., 2018). Examples of common knowledge details are: (g) “So we dropped by shops for clothes, cosmetics and such things”; (h) “I went to Santa Monica Beach; I looked around the beach and it was better than I had expected;” and (i) “I went to Universal Studio; I think I stayed there all day long”. Self-handicapping strategies refer to justifications as to why someone is not able to provide information (Vrij, Leal, Jupe et al., 2018). Examples of self-handicapping strategies are: (j) “I am not a type of a person who plans a lot”; (k) “We skipped some plans and came back to the guest house early”; and (l) “The trip was almost one year ago, I really do not remember many details”. A second coder coded a random sample of 40 transcripts. Inter-rater reliability between the two coders, using the two-way random effects model measuring consistency, was good for all measures: complications low (single measures, intraclass correlation coefficient, ICC = .88), complications medium/high (single measures ICC = .72), common knowledge details (single measures ICC = .81), and self-handicapping strategies (single measures ICC = .70). Preparation Thoroughness, Preparation Time and Motivation Three 2 (Veracity) x 2 (Model Statement Pre-Informed) x 2 (Types of Detail Pre-Informed) ANOVAs were carried out with preparation thoroughness, preparation time, and motivation as dependent variables. For preparation thoroughness, a significant main effect for Veracity emerged, F(1, 193) = 24.00, p < .001, d = 0.69 (0.40, 0.97). Truth tellers (M = 5.29, SD = 1.21, 95% CI [5.03, 5.54]) rated their preparation as more thorough than liars (M = 4.41, SD = 1.33, 95% CI [4.17, 4.66]). All other effects were not significant, all Fs < 3.80, all ps > .055. For preparation time, also as significant main Veracity effect emerged: F(1, 193) = 38.22, p < .001, d = 0.87 (0.56, 1.14). Truth tellers (M = 6.24, SD = 1.14, 95% CI [5.96, 6.52]) believed more than liars (M = 5.04, SD = 1.59, 95% CI [4.77, 5.31]) that they were given sufficient time to prepare themselves for the interview. All other effects were not significant, all F’s < 3.28, all ps > .071. For motivation, a significant main effect for Model Statement Pre-Informed emerged, F(1, 193) = 7.22, p = .008, d = 0.39 (0.10, 0.66). Participants were more motivated in the Pre-Informed Present (M = 4.19, SD = 0.77, 95% CI [4.02, 4.35]) than in the Pre-Informed Absent (M = 3.86, SD = 0.92, 95% CI [3.70, 4.03]) condition. All other effects were not significant, all Fs < 2.64, all ps > .105. Since preparation thoroughness, preparation time, and motivation may affect participants’ verbal output, we introduced these variables as covariates in the analyses where we examined verbal output. Note that preparation thoroughness and preparation time were measured on 7-point Likert scales but motivation on a 5-point Likert scale. The grand mean scores for preparation thoroughness (M = 4.83, SD = 1.34) and preparation time (M = 5.62, SD = 1.51) indicated that participants thought that their preparation time was moderate but their preparation time sufficient. The grand mean for motivation (M = 4.02, SD = 0.86) shows that participants were very motivated. Rapport and Percentage of Truth Telling Two ANOVAs utilizing a 2 (Veracity) x 2 (Model Statement Pre-Informed) x 2 (Types of Detail Pre-Informed) between-subjects design were carried out with (1) rapport, and (2) percentage of truth telling as dependent variables. The analysis with Rapport did not result in a significant effect, all Fs < 3.80, all ps > .053. For percentage of truth telling, a main effect for Veracity occurred, F(1, 193) = 547.07, p < .001, d = 3.32 (1.84, 3.69). Truth tellers (M = 93.81, SD = 11.12, 95% CI [89.40, 98.20]) reported to have been more truthful than liars (M = 21.18, SD = 28.90, 95% CI [16.92, 25.43]). All other effects were not significant, all Fs < 2.93, all ps > .088. Reading and Understanding the Provided Material Participants in the Model Statement Pre-Informed Present condition indicated that they had read (M = 5.38, SD = 1.51) and understood (M = 5.16, SD = 1.53) the information about the Model Statement. Four ANOVAs utilizing a one-factorial (Model Statement Pre-Informed) between-subjects design were carried with the participants’ impressions of the aim of the Model Statement as dependent variables. None of the effects were significant, both Fs < 2.77, all ps > .097. The participants correctly indicated that the aim of the Model Statement was to encourage them to say more (M = 6.01, SD = 1.50) rather than less (M = 1.61, SD = 1.12). They also reported that the Model Statement made them realise that their initial answers were not detailed enough (M = 5.26, SD = 1.98) rather than too detailed (M = 2.83, SD = 1.89). Participants in the Types of Detail Pre-Informed Present condition indicated that they had moderately read (M = 4.58, SD = 1.92) and understood (M = 4.09, SD = 1.80) the information about the dependent variables. Chi-square analyses revealed that reading about the dependent variables was positively associated with knowing the relationship between deception and complications, χ2(1, n = 200) = 7.65, p = .006. More participants (66.3%) who had read information about dependent variables were correct in reporting the relationship between complications and deception than those who had not read such information (47.0%). The associations for common knowledge details χ2(1, n = 200) = 1.25, p = .264 and self-handicapping strategies χ2(1, n = 200) = 3.23, p = .073, were not significant. Time since the Trip Was Made Truth tellers were asked on the pre-condition selection form to indicate when they made the trip they discussed. On average this trip was made M = 5. 60 months prior to the interview (SD = 3.16). This variable was positively correlated with self-handicapping strategies, r(97) = .30, p = .003, but not with any of the other main dependent variables in the study (detail, complications low, complications medium/high, common knowledge details, or ratio of complications), all rs < .17, all ps > .115). Hypothesis Testing Total interview. A MANCOVA utilizing a 2 (Veracity) x 2 (Model Statement Pre-Informed) x 2 (Types of Detail Pre-Informed) between-subjects design was carried out with total details, complications low, complications medium/high, common knowledge details, self-handicapping strategies as the dependent variables (unique details, complications etc. reported during the entire interview). Preparation thoroughness, preparation time, motivation, and site were covariates. At a multivariate level, the analysis revealed a main effect for Veracity, F(5, 185) = 3.44, p = .005, ηp2 = .09. The univariate main effects for Veracity are presented in Table 1. Truth tellers provided more details and more complications (both low and medium/high) than liars. The effect sizes (d) ranged from small to medium. All other effects were not significant, all Fs < 1.14, all ps > .340. An ANCOVA utilizing a 2 (Veracity) x 2 (Model Statement Pre-Informed) x 2 (Types of Detail Pre-Informed) between-subjects design was carried out with proportion of complications as the dependent variable. Since the patterns of findings for complications low and complications medium/high were similar (both more reported by truth tellers than by liars) we calculated the proportion score based on the total amount of complications (low plus medium/high). Preparation thoroughness, preparation time, motivation, and site were covariates. The analysis revealed a main effect for Veracity, F(1, 189) = 4.37, p = .038, d = 0.26 (-0.02, 0.54) with truth tellers (M = 0.60, SD = 0.36, 95% CI [0.54, 0.68]) obtaining a higher proportion of complication score than liars (M = 0.51, SD = 0.33, 95% CI [0.44, 0.57]). However, the effect size (d) was small. The two other main effects and all interaction effects were not significant, all Fs < 1.55, all ps > .214. The absence of any significant interaction effects involving the Veracity factor means that the Hypothesis was rejected. New information after the model statement. A second MANCOVA utilizing a 2 (Veracity) x 2 (Model Statement Pre-Informed) x 2 (Types of Detail Pre-Informed) between-subjects design was carried out with new details, new complications low, new complications medium/high, new common knowledge details, and new self-handicapping strategies as the dependent variables (details, complications etc. reported after the Model Statement that were not reported before the Model Statement). Preparation thoroughness, preparation time, motivation, and site were covariates. At a multivariate level, the analysis revealed main effects for Veracity, F(5, 185) = 4.78, p < .001, ηp2 = .11 and Types of Detail Pre-Informed, F(5, 185) = 2.53, p = .030, ηp2 = .06. The univariate main effects for Veracity are presented in Table 1. Truth tellers provided more new details and more new complications (both low and medium/high) than liars, whereas liars provided more new common knowledge details and more new self-handicapping strategies than truth tellers. The effect sizes (d) ranged from somewhat small (d = 0.37) to medium (d = 0.53). Regarding the Types of Detail Pre-Informed main effect, one significant univariate effect occurred, F(1, 189) = 8.88, p = .003, d = 0.45 (0.16, 0.73), with participants in the Types of Detail Pre-Informed Present condition reporting fewer common knowledge details (M = 0.43, SD = 0.79, 95% CI [0.24, 0.64]) than those in the Absent condition (M = 0.90, SD = 1.24, 95% CI [0.67, 1.08]). All other effects were not significant, all Fs < 1.37, all ps > .238. An ANCOVA utilizing a 2 (Veracity) x 2 (Model Statement Pre-Informed) x 2 (Types of Detail Pre-Informed) between-subjects design was carried out with proportion of complications (based on the new information provided after listening to the Model Statement) as the dependent variable. Again, we calculated the proportion score based on the total number of complications (summation of low and medium/high). Preparation thoroughness, preparation time, motivation, and site were covariates. The analysis revealed a main effect for Veracity, F(1, 189) = 12.61, p < .001, d = 0.47 (0.18, 0.74) with truth tellers (M = 0.80, SD = 0.32, 95% CI [0.74, 0.88]) obtaining a higher proportion of complication score than liars (M = 0.64, SD = 0.36, 95% CI [0.57, 0.70]). The effect size (d) was medium. The two other main effects and all interaction effects were not significant, all Fs < 2.47, all ps > .117. Again, the absence of any interaction effect involving the Veracity factor means that the Hypothesis was rejected. Total interview: uninformed truth tellers – informed liars comparisons. A MANCOVA was carried out with Veracity as the only factor. The Veracity factor had four levels: (i) uninformed truth tellers, (ii) liars informed about the Model Statement, (iii) liars informed about the types of detail, and (iv) liars informed about the Model Statement and the types of detail. The dependent were the total unique: details, complications low, complications medium/high, common knowledge details, self-handicapping strategies, as well as the proportion of complications based on the total number of unique complications (low and medium/high combined), common knowledge details and self-handicapping strategies. Preparation thoroughness, preparation time, motivation, and site were covariates. The analysis revealed a non-significant multivariate effect for Veracity, F(18, 266) = 1.06, p = .339, ηp2 = .07. The Hypothesis was therefore rejected. New information after the model statement: Uninformed truth tellers – informed liars comparisons. Another MANCOVA was carried out with the four level Veracity factor as the only factor, but with dependent variables, the new total details, new complications low, new complications medium/high, new common knowledge details, new self-handicapping strategies, and new proportion of complications (based on the total number of new complications (low and medium/high combined), common knowledge detail, and self-handicapping strategies. Preparation thoroughness, preparation time, motivation, and site were covariates. Table 2 Statistical Results as a Function of Veracity: Comparisons between Uninformed Truth Tellers and Different Categories of Liars 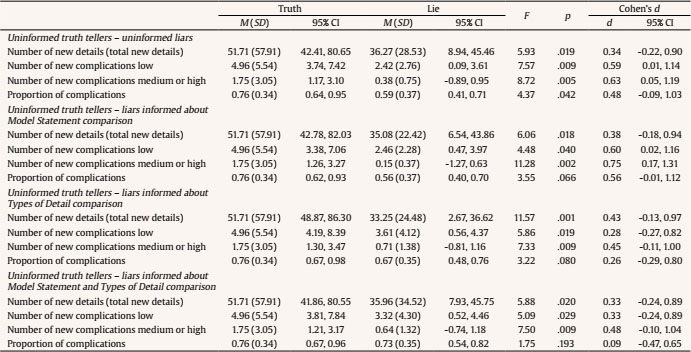 The analysis revealed a significant multivariate effect for Veracity, F(18, 266) = 1.69, p = .041, ηp2 = .10. At a univariate level four significant effects of Veracity emerged. For new details F(3, 95) = 3.73, p = .014, ηp2 = .11, new complications low, F(3, 95) = 2.99, p = .035, ηp2 = .09, new complications medium/high, F(3, 95) = 5.19, p = .002, ηp2 = .14, and proportion of complications, F(3, 95) = 2.73, p = .048, ηp2 = .08. The effects of Veracity for common knowledge details and self-handicapping strategies were not significant, both Fs < 2.46, both ps > 0.067. Of particular interest are the comparisons between the uninformed truth tellers with the three groups of liars. The results are presented in Table 2. As a baseline comparison, we also included the uninformed truth tellers – uninformed liars comparisons; these comparisons are presented at the top of Table 2. For the uninformed truth tellers – uninformed liars comparisons – all four effects were significant. The effect sizes ranged from small (d = 0.34) to medium (d = 0.63). Similar patterns of findings emerged in the three remaining analyses. That is, most effects were significant and d-scores generally ranged from small to medium. In other words, these analyses also showed no effect for the hypothesis. In the present experiment, we found no evidence that liars sounded like truth tellers after being informed about the Model Statement and/or Types of Detail we examined. This lack of evidence cannot correspond to a lack of power as study power was good. The lack of evidence already became apparent in the absence of any interaction effects involving the Veracity factor in the analyses of variance utilising full factorial designs. It became further apparent in the specific comparisons we made between uninformed truth tellers and informed liars. The absence of a countermeasures effect was not expected as we predicted that liars would be able to sound like truth tellers when they were informed about both the Model Statement and the Types of Detail we examined. The self-reports in the post-interview questionnaire provides some insight into what happened. First, participants indicated to have read and understood the working of the Model Statement. However, the results also revealed that after listening to the Model Statement all participants, including those in the Model Statement Information absence condition, understood the aim of the Model Statement (encouraging then to report more information). In other words, reading about the Model Statement did not help the participants because the aim of the Model Statement was clear to all participants. Although we informed participants in the Model Statement Pre-Informed condition what a Model Statement is and what it is meant to do, we did not inform them how we use the Model Statement in a within-subjects design (i.e., initial free recall followed by exposure to a Model Statement followed by a second free recall, and paying attention to the new details in the second recall). Perhaps liars in the experiment expected a Model Statement at the beginning of the interview and became confused when this did not happen. Perhaps providing liars with this specific within-subjects information will help them to effectively use countermeasures, an issue worth examining in future research. If the efficacy of countermeasures depends on providing information about how the Model Statement is used in an interview, practitioners can exploit this because they can introduce the Model Statement in different ways. The self-report results for the Types of Detail Pre-Informed condition showed that participants in the Types of Detail Pre-Informed present condition moderately read and understood the provided information. The Types of Detail information sheet contained fewer words (N = 749) than the Model Statement information sheet (N = 1,064); thus the length of the information sheet cannot explain why it was read less carefully than the Model Statement information sheet. We think that participants found the text about types of detail difficult to understand. Participants in the Types of Detail Pre-Informed Present condition were more accurate than the participants in the Absent condition about the relationship between the types of detail and deception. However, this only applied to complications and even for this variable many participants gave the incorrect answer regarding its relationship with deception. Some reasons can be given for why participants may have found the types of detail information sheet difficult to understand. First, it could have been a translation issue and perhaps the translated texts are difficult to understand. To avoid this issue, we used translators who were familiar with the deception literature, but inaccuracies may still have emerged in the translated texts. Second, only a few examples of complications, common knowledge details, and self-handicapping strategies were provided in the information sheet and this reflected the information given in the articles on which the information sheet was based. Perhaps the use of countermeasures becomes more effective when more examples are given. In a similar vein, the Types of Detail information sheet only mentioned what differences in detail between truth tellers and liars typically emerge and did not mention what liars should say or avoid saying to sound convincing. Perhaps the use of countermeasures becomes more effective when it is explicitly mentioned in information sheets what liars should say and should avoid saying. However, providing additional information, such as more examples and instructions what to say or avoid saying, goes beyond the scope of our countermeasures research. We examined whether liars who are informed about the Model Statement and types of detail through reading articles can successfully employ countermeasures. Regarding the Veracity effects, stronger results appeared when examining the new details after the Model Statement than when examining the total of unique details reported in the entire interview. In other words, examining details in the manner recently suggested appeared to be most effective (see Vrij, Leal, & Fisher, 2018; Vrij, Leal, Jupe et al., 2018). Truth tellers provided more new details and more new complications (both low and medium/high) than liars, whereas liars provided more new common knowledge details and more new self-handicapping strategies than truth tellers. That truth tellers report more new details and new complications is compatible with the idea that giving truth tellers an additional opportunity to recall invariably leads to new information (reminiscence: e.g., Gilbert & Fisher, 2006), which is the essence of the “multiple retrieval” principle of the Cognitive Interview (Fisher & Geisleman, 1992). That liars do not report as many new details and complications is compatible with liars’ lack of episodic memory about the event and also with their strategy to “keep it simple” and not to reveal unnecessary details (Hartwig et al., 2007). That liars do provide additional common knowledge details and self-handicapping strategies is compatible with the belief that liars feel compelled to say something after being exposed to a Model Statement –but not to provide the kind of details that might implicate that they are lying. Complications and the proportion of complications yielded stronger results than common knowledge details and self-handicapping strategies, which replicated the previous findings when these three variables were observed (Leal, Vrij, Deeb, & Kamermans, 2019; Vrij, Leal et al., 2017; Vrij, Leal, Fisher, Mann et al., 2018; Vrij, Leal, Jupe et al., 2018; Vrij et al., 2019). Unlike previous research, the proportion of complications did not yield a stronger effect than the total details variable (Leal et al., 2019; Vrij, Leal et al., 2017; Vrij, Leal, Fisher, Mann et al., 2018; Vrij, Leal, Jupe et al., 2018; Vrij et al., 2019). Our data cannot explain this finding, but we speculate that this may have been caused by the Types of Detail information provision. That is, information resulted in both participants –truth tellers and liars alike – providing fewer common knowledge details. The fewer common knowledge details are reported, the higher the proportion of complications score will become. In the present experiment, we recruited participants in Lebanon, Mexico, and South-Korea. In that respect the study deviated from the typical deception research conducted in the United States and Western Europe and widens our knowledge about cues to deception. A next step would be to compare the results between the three different countries. We could not do this with the present data set. First, this would result in a 24 cells between-subjects design for which we lacked the statistical power. Second, since we used native interviewers in each country, nationality was confounded with the specific interviewer. In conclusion, we found no evidence that liars sounded like truth tellers after being informed about the Model Statement and/or Types of Detail we examined. This does not rule out that countermeasures may become more effective if specific information about the use of the Model Statement is given or if participants are explicitly instructed which types of detail they should report and which ones they should avoid reporting. aConflict of Interest aThe authors of this article declare no conflict of interest. Appendix The Model Statement Information Sheet Specific interview techniques have been developed that make lie detection easier because truth tellers and liars respond differently when exposed to these techniques. To what extent can a liar who learns about the techniques successfully adjust her/his responses so that s/he sounds like a truth teller? In this document you will find information about one such technique, the model statement technique. Please read this information carefully because in the interview you will be exposed to the model statement technique. This document consists of three parts: The first part Interviewing to detect deception contains some general information about lie detection techniques that successfully discriminate truth tellers from liars. The second part Encouraging interviewees to provide more information gives a little bit more information about the general approach we will use in the interview you will have after reading this document. The third part A model answer (model statement) outlines the specific approach we will use in the interview: the model statement technique. It contains:
You can take as long as you wish to read this document and to think how to apply your knowledge about it in the interview. Good luck! Interviewing to Detect Deception (from Vrij, Fisher, & Blank, 2017) The core of the cognitive lie detection approach is that investigators can magnify the differences in (non-)verbal cues displayed by truth tellers and liars. If successful, those interventions should facilitate lie detection. The cognitive lie detection approach consists of three techniques that can differentiate truth tellers from liars: (1) imposing cognitive load, (2) encouraging interviewees to provide more information, and (3) asking unexpected questions. Encouraging Interviewees to Provide More Information The core of the encouraging interviewees to provide more information technique is as follows. If truth tellers provide more information, they are more likely to be believed, because the richer an account is perceived to be in detail, the more likely it is to be believed. Moreover, the additional information truth tellers provide could provide leads to investigators to check. Liars may find it cognitively too difficult to add as many details as truth tellers do, or, if liars do add a sufficient amount of detail, the additional information may be of lesser quality or may sound less plausible. Also, liars may be reluctant to add more information out of fear that it will provide leads to investigators and, consequently, give their lies away. In other words, techniques that facilitate interviewees to say more may result in truth tellers in particular saying more. Research has supported this premise. Experimental research to date has revealed four ways to facilitate truth tellers to say more: (i) by using a supportive interviewer (nodding head and smiling during an interview, (ii) by giving an example of a model answer (a very detailed answer), (iii) by using drawings, and (iv) by using the cognitive interview technique. A model Answer (Model Statement) (from Leal et al., 2015) The Rationale Differences between truth tellers and liars may emerge if truth tellers provide longer statements. Talkative truth tellers raise the standard for liars, who also need to become more talkative to match truth tellers. In becoming more talkative, liars potentially increase exposing their deception. A possible way to make truth tellers more talkative is to provide participants with a detailed, model statement – albeit about an unrelated topic. The underlying assumption is that if truth tellers hear a detailed model statement, their views on what is expected from them may change and, as a result, they may provide a more detailed answer themselves. Truth tellers’ inclination to provide more detail after being exposed to a detailed model statement may not be replicated by liars. First, liars face the problem that they should not say too much, as the information they give may indicate that they are lying. For example, they may say something that the interviewer knows to be false or easily can find out to be false. Second, liars typically prepare themselves for interviews. However, it is unlikely that they have prepared as much detail as the detailed model statement implies they should provide. A model statement therefore puts pressure on liars to include more detail than they have initially prepared. Perhaps liars lack the imagination and skills to generate the same amount of extra detail as truth tellers do. If so, then truth tellers will give longer answers that contain more detail than liars, particularly after being exposed to a detailed model statement. An alternative outcome is possible. After listening to a detailed, model statement liars may manage to lengthen their answers and provide additional detail. However, this additional information may not sound as plausible as the additional information truth tellers provide. If this is the case, then number of words and amount of detail will not differ between truth tellers and liars, but plausibility would, with truth tellers’ answers sounding more plausible, particularly after being exposed to a detailed model statement. How to Apply a Model Statement in an Interview In the interview, prior to answering the open-ended question to discuss their experiences in detail, participants were asked to listen to an audiotape in which a person gives a detailed account of attending a motor racing event. We did not want to give participants an idea what to say during the interview (hence, the unrelated event of motor racing), but wanted to give them an idea about what a detailed account entails. The model statement audiotape was a recall of a witness describing his experiences when attending motor racing for 1 day. This was a spontaneous, unscripted, recall of the event, and the only instruction the witness received was to be as detailed as possible. The witness was aware that this recall would be used as an example for others. We did not give any guidance The Results Being exposed to a model statement resulted in truth tellers and liars adding a similar number of words to their stories which contained similar detail. However, these additional details sounded more plausible in truth tellers. Apparently, adding words and details to a story is one thing; doing that in a plausible way is another issue. The Types of Detail Information Sheet Research has shown that truth tellers and liars often differ in speech content when recalling a story. In this document we briefly describe the main differences. “You can take as long as you wish to read this document and to think how to apply your knowledge about it in the interview. Good luck!”. Speech Content and Deception (from Vrij, Leal, Jupe, & Harvey, 2018) Total amount of information. Truth tellers typically provide more details than liars, because (i) liars lack the imagination to fabricate details that sound plausible or (ii) they are unwilling to provide many details out of fear that those details give leads to investigators that they are lying. Complications, common knowledge details and self-handicapping strategies. Total amount of information is a generic measure that does not take into account the different types of detail truth tellers and liars report. In brief, truth tellers provide stories that include non-essential details that make the story more complex (complications). By comparison, liars provide details that are based on common knowledge, or justify why they cannot provide certain types of information (self-handicapping strategies). A complication is “an occurrence that makes a situation more difficult than necessary” (“The air conditioning was not working properly in the hotel”). Complications are more likely to occur in truthful statements than in deceptive statements. Making up complications requires imagination, but liars may not have adequate imagination to do so. In addition, research examining liars’ interview strategies showed that liars prefer to keep their stories simple, but adding complications makes the story more complex. More examples of complications are: i) ...”she was meant to get a sirloin and I was meant to get a rump but she wanted hers medium rare and they did it the wrong way round and when we tried to complain they didn’t like it” ii)... “when we got on to the M23 there was a lot of traffic there, I’m not sure what was causing the hold-up but yeah took a bit longer than expected to get there”, and iii)... “I remember my en-suite the toilet wouldn’t flush properly, so we had to call maintenance for them to try to sort it out”. Common knowledge details refer to strongly invoked stereotypical information about events (“We visited the Louvre museum where was saw the Mona Lisa”). Liars are more likely to include common knowledge details in their statements than truth tellers. Truth tellers have personal experiences of an event and are likely to report such unique experiences. When they do so the statement is no longer scripted. If liars do not have personal experiences of the event they report, they then will draw upon general knowledge to construe the event (Sporer, 2016). In case liars do have personal experiences of the event, they may not report them due to their desire to keep their stories simple. More examples of common knowledge details are: i)... “we visited the haunted house and we went to London Eye” ii)... “we just went sightseeing to Bath Abbey and then just looked around there” and iii)... “yeah it was wonderful sightseeing. We went to the Colosseum”. Self-handicapping strategies refer to explicit or implicit justifications as to why someone is not able to provide information (“I can’t remember; it was a while ago when this happened”; “Nothing unexpected happened; I am a very organised person”; “I fell asleep in the bus”). Liars are more likely to include self-handicapping strategies in their statements than truth tellers. For liars, who are inclined to keep stories simple, not having to provide information is an attractive strategy. However, liars are also concerned about their credibility and believe that admitting lack of knowledge and/or memory appears suspicious. A potential solution is to provide a justification for the inability to provide information. Note that the justification does not have to be made explicit. The example “I fell asleep in the bus” is an implicit justification for not being able to provide information. More examples of self-handicapping strategies are: i) “I’m not sure exactly what shops we went in because it was quite a while ago”, ii) “And then we just all sort of fell asleep in the car on the way back home”, and iii) “We got there around the afternoon-ish and we looked around. And we went home after that because we were really tired because it’s quite tiring looking around and stuff”. (Examples 1 and 3 are explicit justifications and example 2 is an implicit justification.) Coding One coder, blind to the veracity and countermeasures conditions, coded plausibility on 7-point Likert scales ranging from (1) not plausible to (7) very plausible after each of the four questions, taking into account the plausibility of the previous answers (thus, in fact, measuring plausibility of the story as it develops). The story of a Korean participant who said he travelled from Seoul to Barcelona just for the weekend was considered not plausible because someone typically does not travel from Seoul to Barcelona just for the weekend. In addition, the story of the participant who said he visited Windsor Castle, Buckingham Palace, and Tate Modern in one day was also considered implausible because that is a lot to visit in one day. A second coder coded a random sample of 40 transcripts. Inter-rater reliability between the two coders, using the two-way random effects model measuring consistency, was good, ICC = .75). For the Total Interview analysis we used the plausibility score after the final question. For the After Model Statement analysis we averaged the plausibility scores of the two questions before the Model Statement and also for the two questions after the Model Statement. We then detracted the before the Model Statement score from the after the Model Statement score, a score that could range from -6 to +6. A positive score means that a statement became more plausible after the Model Statement, a negative score means that a statement became less plausible after the Model Statement. We label this the ‘plausibility change’ score Total Interview Analysis An ANCOVA utilizing a 2 (Veracity) x 2 (Model Statement Pre-Informed) x 2 (Types of Detail Pre-Informed) between-subjects design was carried out with plausibility after the final question as dependent variable. Preparation thoroughness, preparation time, motivation and site were covariates. The analysis revealed a main effect for Veracity, F(1, 189) = 32.74, p < .001, d = 0.80 (0.50, 1.08). All other effects were not significant, all Fs < 1.97, all ps > .162. Truth tellers’ stories (M = 4.71, SD = 1.45, 95% CI [4.49, 5.07]) were considered more plausible than liars’ stories (M = 3.62, SD = 1.26, 95% CI [3.28, 3.83]). After the Model Statement Analysis A second ANCOVA utilizing a 2 (Veracity) x 2 (Model Statement Pre-Informed) x 2 (Types of Detail Pre-Informed) between-subjects design was carried out with the plausibility change score as the dependent variable. Preparation thoroughness, preparation time, motivation and site were covariates. The analysis revealed a main effect for Veracity, F(1, 189) = 24.01, p < .001, d = 0.66 (0.37, 0.94). All other effects were not significant, all Fs < 3.11, all ps > .079. Truth tellers’ stories (M = 0.67, SD = 0.88, 95% CI [0.53,0.88]) gained more in plausibility after the Model Statement than liars’ stories (M = 0.10, SD = 0.84, 95% CI [-0.11, 0.23]). One sample t-tests comparing the scores with 0 (no change) showed that truth tellers’ stories became more plausible after the Model Statement, t(96) = 7.47, p < .001, whereas the plausibility of liars’ stories did not change, t(103) = 1.17, p = .244. Uninformed Truth Tellers – Informed Liars Comparisons The uninformed truth tellers – different types of liar comparisons are presented in Table 3. As a baseline comparison, we used the uninformed truth tellers – uninformed liars comparisons; these comparisons are presented at the top of Table 3. For the uninformed truth tellers – uninformed liars comparisons, both effects were significant, with effect sizes d = 0.63 for plausibility at the final question and d = 0.79 for plausibility change respectively. The effect sizes for plausibility after the final question were similar in the three remaining analyses. A somewhat different pattern emerged for the plausibility change variable, because the effect sizes became smaller if participants were informed about the types of detail. This demonstrates a small countermeasures effect, although it is important to note that even in these conditions liars’ stories were still considered less plausible than the truth tellers’ stories. Table 3 Statistical Results as a Function of Veracity: Comparisons between Uninformed Truth Tellers and Different Categories of Liars 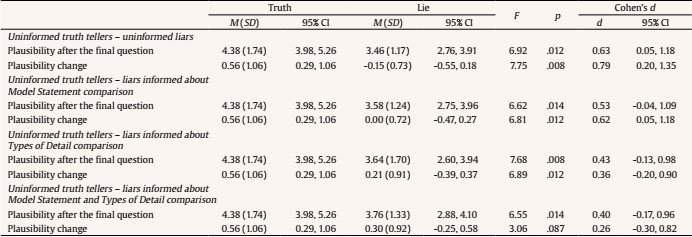 Note 1 Some changes were made compared to the pre-registration. First, we did not introduce the expected-unexpected questions distinction in the interviews as that would have made the interviews too long. Second, we split the countermeasure variables in two variables and thus ran a 2 x 2 x 2 design rather than a 2 x 4 design. Third, we did not code for core and peripheral details as the deception scenario we used is not suitable for this distinction (most, if not all, information would be considered core information). Fourth, in the pre-registration we refer to ‘complications’ and ‘plausibility of complications’. When discussing the coding scheme, we changed this into complications-low and complications-medium/high as we thought this to be less subjective than ‘plausibility’ (we discussed this possibility in the pre-registration). We discuss the plausibility variable and results in the Appendix of this article. Cite this article as: Vrij, A., Leal, S., Fisher, R. P., Mann, S., Deeb, H., Jo, E., ... Hamzeh, S. (2020). The efficacy of using countermeasures in a Model Statement interview. The European Journal of Psychology Applied to Legal Context, 12, 23-34. https://doi.org/10.5093/ejpalc2020a3 Funding: This work is funded by the High-Value Detainee Interrogation Group, DJF-15-1299-V-0010271 awarded to the University of Portsmouth (UK). Any opinions, findings, conclusions, or recommendations expressed in this article are those of the authors and do not necessarily reflect the views of the U.S. Government. References |
Cite this article as: Vrij, A., Leal, S., Fisher, R. P., Mann, S., Deeb, H., Jo, E., Campos, C. C., & Hamzeh, S. (2019). The Efficacy of Using Countermeasures in a Model Statement Interview. The European Journal of Psychology Applied to Legal Context, 12(1), 23 - 34. https://doi.org/10.5093/ejpalc2020a3
aldert.vrij@port.ac.uk Correspondence: aldert.vrij@port.ac.uk (A. Vrij)Copyright © 2026. Colegio Oficial de la Psicología de Madrid





 PDF
PDF e-PUB
e-PUB CrossRef
CrossRef JATS
JATS Print
Print Send
SendEMAIL ALERT
The European Journal of Psychology Applied to Legal Context is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License








