


Verbal Baselining: Within-Subject Consistency of CBCA Scores across Different Truthful and Fabricated Accounts
[La lĂnea base verbal: la congruencia intrasujeto de las puntuaciones del CBCA en diferentes relatos veraces e inventados]
Jonas Schemmel1,a, Benjamin G. Maier1,a, Renate Volbert1, and 2,a
1Psychologische Hochschule Berlin, Germany; 2Charité – Universitätsmedizin Berlin, Institut für Forensische Psychiatrie, Germany
https://doi.org/10.5093/ejpalc2020a4
Received 12 February 2019, Accepted 5 November 2019
Abstract
Statement Validity Assessment (SVA) proposes that baseline statements on different events can serve as a within-subject measure of a witness’ individual verbal capabilities when evaluating scores from Criteria-based Content Analysis (CBCA). This assumes that CBCA scores will generally be consistent across two accounts by the same witness. We present a first pilot study on this assumption. In two sessions, we asked 29 participants to produce one experience-based and one fabricated baseline account as well as one experience-based and one fabricated target account (each on different events), resulting in a total of 116 accounts. We hypothesized at least moderate correlations between target and baseline indicating a consistency across both experience-based and fabricated CBCA scores, and that fabricated CBCA scores would be more consistent because truth-telling has to consider random event characteristics, whereas lies must be constructed completely by the individual witness. Results showed that differences in correlations between experience-based CBCA scores and between fabricated CBCA scores took the predicted direction (cexperience-based = .44 versus cfabricated =.61) but this difference was not statistically significant. As predicted, a subgroup of event-related CBCA criteria were significantly less consistent than CBCA total scores, but only in experience-based accounts. The discussion considers methodological issues regarding the usage of total CBCA scores and whether to measure consistency with correlation coefficients. It is concluded that more studies are needed with larger samples.
Resumen
El Statement Validity Assessment (SVA) propone que las declaraciones sobre diferentes eventos pueden servir como una línea base intrasujeto de la medida de las capacidades verbales individuales de un testigo al evaluar las puntuaciones del Criteria Based Content Analysis (CBCA). Esto implica que las puntuaciones del CBCA serán congruentes en dos relatos del mismo testigo. Presentamos un primer estudio piloto sobre este supuesto. Se pidió a 29 participantes en dos sesiones que elaboraran un relato verdadero (línea base) y otro inventado, además de un relato verdadero y otro inventado (cada uno en situaciones diferentes), arrojando un total de 116 relatos. Se planteó la hipótesis de una correlación al menos moderada entre la declaración fabricada y la verdadera, que indicaría una consistencia entre las puntuaciones en el CBCA de relatos inventados y experimentados y que las puntuaciones en el CBCA inventadas serían más consistentes porque la verdad incluye las características aleatorias de los hechos, mientras que las mentiras las construye totalmente el testigo. Los resultados mostraron que las diferencias en las correlaciones entre las puntuaciones en el CBCA de relatos experimentados y fabricados iban en la dirección predicha (cvivido = .44 frente a cinventado = .61), pero esta diferencia no fue significativa. Como se predijo, un subgrupo de criterios de CBCA relacionados con los hechos fue menos congruente que las puntuaciones totales de CBCA, pero sólo en los relatos de hechos experimentados. Se discuten las implicaciones metodológicas relacionadas con el uso de las puntuaciones totales del CBCA y si se debe medir la consistencia mediante el coeficiente de correlación. Se concluye que se necesitan otros estudios con muestras más grandes.
Keywords
Statement Validity, Assessment (SVA), Criteria-based Content, Analysis (CBCA), Consistency, Verbal baselining, Baseline statements, Within-subject measurePalabras clave
Statement Validity, Assessment (SVA), Criteria-based Content, Analysis (CBCA), Congruencia, LĂnea base verbal, Declaraciones de referencia, Medidas intrasujetoCite this article as: Schemmel, J., Maier, B. G., & Volbert, R. (2019). Verbal Baselining: Within-Subject Consistency of CBCA Scores across Different Truthful and Fabricated Accounts. The European Journal of Psychology Applied to Legal Context, 12(1), 35 - 42. https://doi.org/10.5093/ejpalc2020a4
schemmel.jonas@googlemail.com Correspondence: schemmel.jonas@googlemail.com (J. Schemmel).Criteria-based Content Analysis (CBCA; Steller & Köhnken, 1989; Volbert & Steller, 2014) is based on the assumption that the quality of experience-based statements is generally higher than the quality of fabricated statements (Undeutsch, 1967). The quality of a statement is indicated by the CBCA criteria compiled by Steller and Köhnken (1989) and revised by Niehaus (2008) and Volbert and Steller (2014) (see Table 1). Generally, meta-analyses have shown the assumed difference in CBCA criteria between experience-based and fabricated accounts (Amado, Arce, & Fariña, 2015; Amado, Arce, Fariña, & Vilariño, 2016; Masip, 2017; Oberlader et al., 2016). However, the number and type of content characteristics to be found in a statement are supposed to be determined not only by the veracity of the statement but also, inter alia, by the cognitive abilities and narrating habits of the statement provider (Nahari & Vrij, 2015; Schemmel & Volbert, 2016). Thus, Statement Validity Assessment (SVA) stresses that CBCA scores need to be evaluated “against the background of an individual’s . . . verbal competencies” (Steller & Köhnken, 1989, p. 218), thereby highlighting the relevance of within-subject measures when assessing individual statements (see also Köhnken, 2004). To account for these individual verbal capabilities, “verbal baselining” has been suggested as a procedure with which to assess individual verbal behavior (Greuel et al., 1998; Köhnken, 2004; Volbert, Steller, & Galow, 2010; Vrij, 2016). This study focuses on baseline statements on different events as a verbal baselining procedure within SVA, and is the first to address CBCA score consistency—that is, the correspondence of individuals’ CBCA scores across statements on different events—as its main precondition. Table 1 CBCA Criteria and Their Interrater Reliabilities as ICC (2,2) with 95% Confidence Intervals 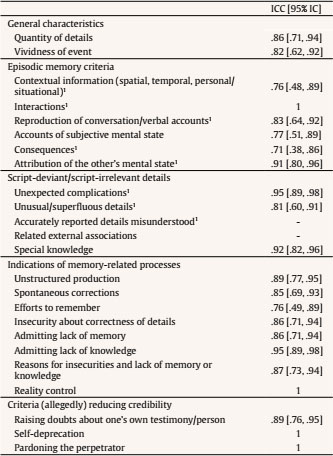 Note. 1Criteria directly encoding details of the event itself (event-related criteria). Verbal Baselining in SVA: Baseline Statements as Within-Subject Measures Elaborations on verbal baselining as a within-subject measure within SVA are rare. Offe and Offe (2000) have provided specific instructions, but only in German. They proposed asking the statement provider to produce one or more experience-based and/or false accounts about various personally relevant events. The CBCA scores of these baseline accounts could then be compared with the CBCA scores of the statement on the event in question (target account) and used as within-subject references. In short, the idea is that similarities between the target account and the experience-based baseline account and dissimilarities between the fabricated baseline and the experience-based target account will suggest the truthfulness of the target and vice versa. Other authors suggest asking only for experience-based biographical events and then checking whether the target account deviates from the baseline truthful account (Volbert & Steller, 2014). However, the underlying notion common to both approaches is to draw on at least one baseline statement to infer an estimation of an individual CBCA score (or profile) that a person is expected to achieve. Thus, the use of verbal baselining will generally require CBCA scores of individuals obtained from statements on different events to correlate, that is, to be consistent. CBCA Score Consistency as the Prerequisite of Verbal Baselining Approaches in SVA Verbal baselining approaches are therefore based (implicitly) on the assumption that a content analysis of one truthful or fabricated statement can to some extent predict the content quality of another truthful or fabricated statement. Thus, drawing on key concepts from personality psychology (“past behavior predicts future behavior”), CBCA scores might, to a certain degree, be person-specific (Schemmel & Volbert, 2017). Person specificity, in turn, is expected to be indicated by the consistency of CBCA scores across a person’s baseline and target statements.1 That is, CBCA scores contained in two truthful statements or two fabricated statements produced by the same individual are assumed to be similar, even if these statements refer to different events. Moreover, because some authors suggest using both experience-based and fabricated baseline statements (Greuel et al., 1998; Offe & Offe, 2000), they are clearly assuming that both experience-based and fabricated statements have CBCA score consistency. To the best of our knowledge, however, no studies have been conducted on this baseline statement approach in the context of SVA and its main precondition, that is, CBCA score consistency.2 In the following, we shall formulate three testable assumptions on CBCA score consistency across baseline and target accounts. Hypothesis 1: CBCA scores of experience-based and fabricated accounts will be moderately consistent Both telling the truth and lying can be considered to be cognitive-verbal tasks that should thus be influenced by stable person variables. The literature discusses the influence of the following variables on the verbal content of statements: age (Vrij, 2008), a general tendency to narrate autobiographical experiences (Nahari & Vrij, 2014), personality characteristics (Schelleman-Offermans & Merckelbach, 2010), and abilities to deceive/deception strategies (Vrij, Granhag, & Mann, 2010) (for a brief overview, see Volbert & Steller, 2014). However, producing a target account places different demands on the statement provider than producing a baseline account: following the verbal baselining procedure using baseline statements (cf. above), the statement provider is instructed directly by the interviewer to lie or tell the truth. Hence, the ground truth of the baseline is overt to both sender and recipient. Therefore, producing an experience-based baseline account under these conditions does not involve any special communication demands, and fabricating a baseline account does not include any deception demands (Köhnken, 1990; Sporer, 2016). We therefore assume that experience-based and fabricated CBCA scores will be fairly consistent overall, but only to a moderate degree (Cohen, 1988). Hypothesis 2: CBCA scores of experience-based accounts will be less consistent than CBCA scores of fabricated statements As mentioned before, both experience-based and fabricated statements have been suggested as baseline measures. Therefore, the question arises whether CBCA scores of experience-based baseline and target accounts versus CBCA scores of fabricated baseline and target accounts might differ in their consistency. Indeed, an analysis of the main processes involved in producing experience-based or fabricated accounts of personal experiences reveals one obvious, but significant difference: an experience-based statement is based on specific experiences, whereas a lie is based on general cognitive schemata and knowledge about the event type in question (Köhnken, 1990, 2004; Sporer, 2016), the witness’s deception ability (Köhnken, 1990; Vrij et al., 2010), and individual deception strategies (Maier, Niehaus, Wachholz, & Volbert, 2018). Hence, CBCA scores of fabricated accounts are influenced mainly by personal variables. In contrast, CBCA scores of experience-based statements are determined more strongly by actual event characteristics: truth-tellers can reproduce conversations only if there was a conversation; they will point out unusual details only if there was something unusual to notice; and so forth. These event characteristics should not covary systematically between two experience-based events. Thus, they should increase the random share of variance across experience-based, but not across fabricated baseline and target accounts. This should lower the relative influence of personal variables on CBCA scores contained in experience-based accounts. Note that we neither assume the influence of the witness’ personality on perceiving, encoding, and reporting event-related criteria in experience-based accounts to be zero, nor do we deny that personality might, in part, evoke specific responses resulting in some of the event-related criteria (such as conversations). This is why we do not argue that event-related criteria in experience-based statements should not be consistent at all, but only consistent to a lesser degree. In summary, we assume that CBCA scores of experience-based baseline and target statements will be less consistent than those of fabricated statements. Hypothesis 3: The differential consistency of CBCA scores will be determined mainly by event-related criteria Following the considerations above, we assume that event-related CBCA scores in experience-based baseline and target statements will show a weaker correlation compared to the correlation between the corresponding total CBCA scores contained in experience-based statements. In contrast, we consider that event-related CBCA criteria in “fabricated” baseline and target statements will mainly reflect person-related cognitive processes. Therefore, they should correlate at a level comparable to the total CBCA scores found in fabricated baseline and target statements. If, finally, a lower consistency between two experience-based CBCA scores is due at least partially to the unsystematic influence of the event itself, the difference in consistency of experience-based and false statements tested in Hypothesis 2 should be more pronounced when only event-related criteria are included. Criteria are defined as event-related if they directly reflect incidents and details of the event itself. This is assumed for “contextual information”, which is determined by the specific surroundings and temporal setting that a witness finds rather than creates him- or herself; “verbal and nonverbal interactions”, which require the presence of another person who can be addressed and who shows a (verbal) reaction determined by him or her rather than by the witness; “consequences of the event”, which are by definition determined by the event itself as they happen to the witness ; “attribution of the other’s mental state”, which is, by definition, illustrated by the concerned other’s behavior and not by the witness; “unexpected complications”, which are defined as not foreseen by the witness before they happen to her or him; and, finally, “unusual or superfluous details and accurately reported details misunderstood”, which represent special features of the surroundings or aspects of the event that are perceived and remembered by the witness, but not created. The other criteria, such as accounts of own mental state or criteria summarized as indications of memory-related processes (cf. Table 1), were categorized as more person-related. The current study therefore aims to investigate the consistency of CBCA scores as a precondition of using baseline statements on different events as within-measures in SVA. Specifically, we derived three testable hypotheses on the consistency of experience-based and fabricated accounts, on the differential consistency of experience-based versus fabricated accounts, and on the differential consistency of event-related versus total CBCA scores. For a preliminary investigation, we designed a pilot study within the context of a larger study on CBCA scores. Thus, the results presented here can be viewed as indications, but they need to be replicated in studies with larger sample sizes. Participants The sample consisted of 29 participants who completed 116 interviews (one of the initial 30 participants did not attend the target interview and had to be excluded). Each participant produced four statements (one experience-based baseline, one experience-based target, one fabricated baseline, and one fabricated target statement) following the procedure depicted below. Participants were 16 females and 13 males with an average age of 35.8 years (SD = 12.02, range 18-57 years). Their educational background was diverse with an emphasis on higher education (21 participants had an upper secondary school and/or a university degree, one was still attending upper secondary school, four had completed a vocational training, three had completed middle school—Realschule). German was the native language of 26 subjects; the remaining 3 had lived in Germany since early childhood. Participants were recruited via university mailing lists (4 participants), an online study participants’ recruitment platform (“vp-gesucht.de”; 1 participant), and small advertisements on EBay (24 participants). 3 The study was announced as an experiment on the relationship between creativity and linguistic expression in describing personal events offering an opportunity to earn between 25€ and 50€. All participants received either 50€ or, if applicable, 25€ combined with a student credit for participating in all three sessions. Procedure Each participant attended a preparatory session followed by two separate interview sessions (baseline and target). Within each interview session, participants had to report one event based on actual experience (experience-based condition) and one event based on fabrication (false condition). In the preparation session, participants were given a list of nine negative, highly emotional events (i.e., being attacked by another person or an animal, being the victim of a criminal assault, having a serious accident, medical intervention, death of a loved one). They had to choose two actual experiences and two events they had not experienced. One experience-based and one fabricated event was randomly assigned to one of the two interviews, respectively. Participants were then asked to prepare an experience-based and a false account for the first interview. Also, in order to establish a high level of motivation, they were told that if their statements were good enough, they would be invited to participate in a second interview session with additional compensation. The baseline interview followed within 2 weeks of the preparation session. Participants were asked to produce the experience-based as well as the fabricated account selected in the preparation session in as much detail as possible. Interviews were semi-structured with an open question to elaborate the central event of the statement followed by three specific questions on details of the report. Note that the interviewer was the second author who had already instructed the participants in the preparation session. Moreover, the interviewer explicitly asked for the experience-based or the fabricated story. Thus, it was obvious to the participants that the interviewer was aware of the ground truth of the respective accounts. This procedure corresponds to baseline interviews in the field where witnesses are also instructed to report an actual experience or to fabricate a lie. The order of truths and lies was randomized across the sample. After the interview, participants were told that they had “qualified” for a second interview session (target interview), and that this interview would be conducted by a psychological expert on credibility assessment. Participants were instructed to prepare the remaining experience-based and false event previously chosen in the preparation session. Moreover, they were told that the expert interviewers would not be informed about the ground truth of their statements. It was also announced that they would receive an additional compensation of 25 Euros if they were able to convince the expert interviewer that both of their statements were experience-based. Within the following 2 weeks, the target interview took place in the office of psychologists specialized in credibility assessment. The interviewer—actually a research assistant—was announced as a psychological expert on credibility assessment whose task was to determine the veracity status of each statement. Interviewers in the target interview were blind to the veracity status. The task for participants was to produce the experience-based and fabricated statements in as much detail as possible. Again, the order of truths and lies was randomized. Because the blinded interviewer could not tell them which statement to start with, the randomized order was emailed to the participants beforehand. The target interviews were again semi-structured like the baseline interview and the number of questions was restricted to three. Note that the task in the target interview corresponded with that in real evaluations in the field: the interviewee had to convince the interviewer of the truthfulness of her or his statement(s) while the interviewer aimed to find out the ground truth. After the target interview, participants were fully debriefed. All participants received the full amount of financial compensation (total of 50€) regardless of their performance. Measures All statements were audio-recorded, transcribed verbatim, and coded by the first author and a research assistant. Prior to rating the transcripts, the research assistant received a 2-week training in CBCA scoring by the first author to ensure a consistent and standardized approach when rating each criterion. Training included reading and discussing relevant literature containing detailed descriptions and examples of the relevant criteria. Both raters also rated several transcripts not contained in the current study until they had achieved a satisfactory interrater reliability (ICC > .40). They then independently coded each of the transcripts for CBCA criteria.4 Both raters were blind to the veracity status of the accounts, did not know in which interview session (baseline or target) the account had been produced, and had no information on the participants or interviewer. CBCA compilation. Raters used a revised version of the CBCA compilation based on Volbert and Steller (2014). It differs from the original compilation suggested by Steller and Köhnken (1989) in three main aspects: (a) logical consistency was removed because it was regarded as a prerequisite rather than a quality criterion (Greuel et al., 1998); (b) unusual and superfluous details were combined into one rating because their overlapping definitions have been discussed as impairing interrater reliability (cf. Anson, Golding, & Gully, 1993; Hauch, Sporer, Masip, & Blandon-Gitlin, 2017; Roma, Martini, Sabatello, Tatarelli, & Ferracuti, 2011); finally, (c) criteria were arranged along the assumed psychological processes underlying CBCA scores (Volbert, 2015) which only affected the order in which the criteria were rated, not their definition. Rating process. Ratings followed a standardized procedure. Raters first coded the absolute frequency of each criterion before weighing each occurrence of single criteria (0 for nonexistent, 1 for weak, and 2 for pronounced). Subsequently, they rated each criterion on a 4-point scale ranging from 1 (absent) to 4 (very pronounced) with reference to the whole account. This stepwise procedure was chosen to ensure raters went through the same structured assessment process and based their ratings on specific text passages. The relevant CBCA assessment included in the further analysis was the final scale rating because this allowed a more fine-grained assessment of the respective criteria and has been recommended in a recent meta-analysis on the reliability of CBCA (Hauch et al., 2017). Ratings were done in 15 stages.5 Within the first 8 stages, raters independently coded 20 accounts per stage. After each rating stage, the two raters’ CBCA codings were checked for each statement and—if necessary—debated. To enhance reliability, raters made sure their codings referred to the same text passage (an aspect often ignored in other studies; cf. Sporer, 2012) and checked whether they basically agreed on the relevance of a specific text passage although they had just assigned it to a different criterion (Tully, 1998). Because agreement improved after the first 8 stages, raters coded 30 instead of 20 accounts within rating stages 9 to 15. Otherwise, the procedure remained the same. Reliability analysis. As suggested in a recent meta-analysis (Hauch et al., 2017), reliabilities of the criteria ratings were estimated using intraclass correlation coefficients (ICC; Shrout & Fleiss, 1979) of type ICC (2,2) (two-way random, average measure) with consistency as the measure of conformity. ICC (2,2) was chosen because reliability results should be applicable to a (fictitious) population of trained raters and the ratings were to be averaged. The criteria “related external associations” and “accurately reported details misunderstood” were not coded indicating that they were not to be found in this sample. They were consequently excluded from further analyses. We calculated ICCs using the R package “irr” (Gamer, Lemon, Fellows, & Singh, 2012) implemented in the statistical software R (v.3.4.1; R Core Team, 2017) run in RStudio (v. 1.1.383; RStudio Team, 2017). For the 116 statements included in the current study, ICCs of the remaining criteria varied between .71 and 1.0 (cf. Table 1). Hence, reliability was good to excellent (Ciccetti, 1994). Prior to the analyses, the two raters’ scores were averaged for each criterion included in the analysis. Alpha was set as 5% for all statistical analyses. For each account, the CBCA criteria were summed up to a total CBCA score resulting in 29 total CBCA scores for each of the four conditions (experience-based baseline, experience-based target, fabricated baseline, fabricated target). Table 2 presents the mean total CBCA score for each of these four conditions as well as absolute differences between them. Correlation coefficients were then compared with the R-package “cocor” (Diedenhofen & Musch, 2015). Table 2 Mean CBCA Sum Scores and Standard Deviations by Veracity Statusand Interview Session 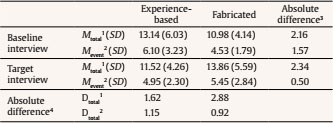 Hypothesis 1: CBCA Scores of Experience-based and Fabricated Accounts Will Be Moderately Consistent Pearson product-moment correlations were calculated between the total CBCA scores of the experience-based baseline and the experience-based target accounts (ct) as well as between the total CBCA scores of the fabricated baseline and the fabricated target account (cf). The total CBCA scores of the experience-based statements correlated at ct(27) = .44, 95% CI [.14, 1.0)], p = .009 (one-tailed); total CBCA scores of the fabricated statements correlated at cf(27) = .61, 95% CI [.37, 1.0], p < .001 (one-tailed). Thus, in line with our assumptions, ct was moderate and cf was high in this sample (Cohen, 1988). Hypothesis 2: CBCA Scores of Experience-based Accounts Will Be less Consistent than CBCA Scores of Fabricated Accounts Even though cf = .61 and ct = .44 differed in the predicted direction on a descriptive level (cf > ct), this difference did not attain statistical significance (z = -1.08, p = .14, one-tailed; cf. Steiger, 1980). Hypothesis 3: The Differential Consistency of Experience-based and Fabricated CBCA Scores Will Be Determined mainly by Event-related Criteria For each account, contextual information, interactions, conversations, consequences, attribution of the other’s mental state, unexpected complications, and unusual/superfluous details event-related CBCA-criteria were summed to an event-related CBCA subscore. Table 2 presents the mean event-related CBCA scores for baseline and target accounts. Pearson product-moment correlations were calculated between the event-related CBCA score of the experience-based baseline and the experience-based target accounts (ct;event) as well as between the event-related CBCA scores of the fabricated baseline and the fabricated target account (cf;event). Strictly speaking, Hypothesis 3 consisted of three assumptions: first, for experience-based baseline and target accounts, we assumed that event-related CBCA scores would show a weaker correlation than total CBCA scores. Second, for fabricated baseline and target accounts, we expected event-related CBCA scores and total CBCA scores to correlate at a similar level. Third, we expected that the difference between correlations of event-related CBCA scores in experience-based versus fabricated accounts would be higher than the correlations of total CBCA scores in experience-based versus fabricated accounts. In line with Hypothesis 3, event-related CBCA scores showed a weaker correlation than total CBCA scores with experience-based statements at ct = .44 and ct;event(27) = .24, 95% CI [-.08, 1.0], p = .10 (one-tailed). This difference between ct and ct;event was statistically significant (z = 1.83, p = .03, one-tailed; cf. Steiger, 1980). As predicted, event-related CBCA scores were thus less consistent than total CBCA scores in experience-based accounts. Second, in contrast to this finding, event-related CBCA scores with fabricated statements correlated at a similar level as the total CBCA scores at cf;event(27) = .55, 95% CI [.29, 1.0], p = .001 (one-tailed). Nonetheless, the difference between cf and cf;event was not statistically equivalent with .01 as equivalence interval (p = .23; cf. Counsell & Cribbie, 2015, p. 296). The assumption of a negligible difference between cf and cf;event could thus not be confirmed statistically in the current sample. Third, on a descriptive level, the difference between ct;event = .24 and cf;event = .55 was clearly larger than the difference between ct = .44 and cf = .61. However, like the difference between ct and cf, it did not attain significance (z = -1.6, p = .06, one-tailed) in this sample. To summarize, only the weaker correlation of event-related CBCA scores across experience-based statements (when compared with total CBCA scores) was in line with our predictions. Unplanned Analyses: Within-subject Correlations In the current article, CBCA sum scores were used. In order to check for ecological validity of the sum score, we calculated mean within-subject correlations for experience-based and fabricated accounts. If their patterns correspond with the one by the sum score correlations, this speaks against an ecological fallacy when using the sum score. To calculate within-correlations, the criteria were treated as nested within each participant resulting in 4 columns (experience-based and fabricated baseline and experience-based and fabricated target statement) and 24 rows (one for each criterion) per participant. Using intra-class correlations, we then correlated the two columns with CBCA scores obtained from experience-based statements and the two columns with CBCA scores obtained from fabricated statements. These participant-wise within-subject ICCs were averaged. In the current data set, the pattern for between-correlations was paralleled descriptively by the one for within-correlations: Mean ICCwithin for CBCA-total scores across experience-based vs. fabricated accounts were .53 vs. .59; mean ICCwithin for event-related CBCA-scores across experience-based vs. fabricated accounts were .50 vs. .59. Nevertheless, the differences were not as pronounced as they were in the case of between-correlations. Because these calculations were merely explorative and meant for illustration, no tests for statistical significance were conducted. Within Statement Validity Assessment (SVA), the CBCA score of a target account is not considered to be decisive per se, but needs to be referred to the baseline verbal behavior of the statement provider (Köhnken, 2004). Textbooks on SVA suggest asking the statement provider to produce an experience-based and/or a fabricated baseline statement on a different personal event whose CBCA score can then be compared with the one contained in the target statement (cf. Offe & Offe, 2000). The implicit assumption in this approach is that CBCA scores are to some extent person-specific, thereby resulting in a consistency of CBCA scores across statements about different events (Schemmel & Volbert, 2017). The current study is the first to address this assumption. We hypothesized that even though both experience-based and fabricated accounts are at least moderately consistent (Hypothesis 1), fabricated CBCA scores are more consistent than experience-based CBCA scores (Hypothesis 2). We assumed this to be due to the influence of event-related CBCA characteristics (such as “unexpected complications”) on experience-based but not on fabricated accounts (Hypothesis 3). Before further discussing the results and implications of this study, a cautionary note is necessary. Research indicates that correlations can be inaccurate in small sample sizes and may tend to stabilize at Ns much larger than 29 (for typical scenarios in psychology with regard to experience-based effects and confidence levels, they stabilize at approximately N = 250; cf. Schönbrodt & Perugini, 2013). Also, equivalence tests as applied when testing Hypothesis 3 usually require more power through being based on a larger sample size (Counsell & Cribbie, 2015). Therefore, as already stressed above, the results presented here should be understood as merely tentative and as a first step toward a theory-driven and empirically based conceptualization of verbal baselining using baseline statements in SVA. Large-scale studies will be needed to draw conclusions relevant for practitioners in the field. In the current pilot sample, CBCA scores of experience-based baseline and experience-based target statements showed a moderate correlation, whereas those contained in fabricated baseline and fabricated target statements showed a high correlation. If these results can be replicated in future research, the basic requirement of using verbal baselining in SVA, that is, the consistency of CBCA scores, would be met. Moreover, both coefficients differed in the predicted direction, even though this difference did not attain statistical significance. Given more robust empirical evidence, the higher consistency of fabricated statements would speak for their preferred use. However, SVA often deals with sexual violence cases where witnesses might be confused by the instruction to lie. Interviewers therefore will often have to rely on experience-based baselines. It might thus be useful if interviewers could differentiate more consistent criteria from less consistent criteria. One possible approach is the identification of event-related criteria which share less systematic personal variance and should thus not be used as baseline measures. Notably, event-related CBCA scores contained in experience-based accounts were in the current study significantly less consistent than total CBCA scores in experience-based statements. This was not, however, the case for event-related versus total CBCA scores in fabricated accounts, indicating that the difference between event-related versus total CBCA scores might be due to varying demands when telling the truth versus lying. Nonetheless, the difference between experience-based and fabricated event-related CBCA scores was not significant. Thus, the assumption that event-related criteria drive the different consistency scores of experience-based and fabricated accounts could not be definitely corroborated in this pilot sample. Some Methodological Considerations The results of the current study need to be replicated through further research on CBCA score consistency. In the following, we discuss two methodological considerations that might be relevant for future research designs. They concern the use of total CBCA scores and the downsides of correlations as indexes of similarity. To begin with, the current study based its calculations on total CBCA scores. Even though widely used as an index for overall content quality, this approach has been criticized mainly due to its lack of ecological validity (Hauch et al., 2017). Yet, the ecological validity of summing up CBCA scores depends largely on the underlying coding of the single criteria. Binary presence ratings not allowing for any weighting of criteria clearly do not match coding procedures in the field, whereas weighted measures and ratings do come close. Thus, total scores seem to be appropriate as long as they are based on the latter coding procedures. Nonetheless, total CBCA scores might increase the probability of ecological fallacies by making unjustified conclusions on an aggregated data level. Two approaches can be taken to deal with possible ecological fallacies. First, rather than just computing a total score, subscales can be defined based on theoretical considerations (such as calculating a sum score consisting of event-based criteria). The second and more data-driven option is to calculate within-person next to between-person correlations like in the current article (cf. the unplanned analyses in the results section). Ecological fallacies are indicated by substantial differences between the mean sample within-ICC and the between-correlation. Thus, in order to ensure the ecological validity of total CBCA scores, future research should drop binary presence ratings, derive meaningful CBCA subscales, and possibly consider between- as well as within-correlations. Second, only reporting correlations as measures of consistency might impair the ecological validity of consistency studies. Indeed, many studies on personality use Pearson product-moment correlations as an index for consistency. However, these refer to the stability of interindividual differences. Hence, strictly speaking, the current study investigated the relative consistency of CBCA scores (Fleeson & Noftle, 2008) whereby the reference is always a sample/population of others. Correlations certainly contain valuable information especially if the interest is in consistency as a general phenomenon or rather as a possible general characteristic (of a given sample). Notably, however, practitioners in the field do not have sample scores at their disposal, but have to base their decisions on the few accounts produced by one current witness. This raises the question regarding how group results such as correlations can be used to infer the behavior of individuals in the field (Faigman, Monahan, & Slobogin, 2014; Nahari et al., 2019). Given the restricted amount of group information, practitioners might (intentionally or not) compare the CBCA score of a baseline directly with the CBCA score of a target statement. Consistency would then most likely be defined as the degree to which both absolute CBCA scores are the same. A low absolute difference between the CBCA scores of, for example, an experience-based baseline and the target statement would suggest the truthfulness of the latter one. This corresponds to the definition of absolute consistency formulated by Fleeson and Noftle (2008), and consequently requires different statistical parameters. Absolute consistency can be indicated by small to zero absolute within-subject differences of CBCA scores contained in baseline and target statements (Schemmel & Volbert, 2017). However, this might yield results that differ from the correlation pattern of relative consistency. In the current data, for example, absolute differences of CBCA scores were larger in fabricated than in experience-based accounts (see absolute differences displayed in Table 2). Hence, contrary to the results on relative consistency, CBCA scores of experience-based accounts were more consistent than those of fabricated accounts when consistency was based on absolute differences. This was probably due to the unexpected finding that participants produced more CBCA criteria in their fabricated target than in their fabricated baseline statements while there was no such effect for experience-based accounts (cf. below). Whether these results can be replicated is an empirical question. Nonetheless, it can already be concluded that CBCA score consistency in a sample might vary depending on how similarity is defined (see also Schemmel & Volbert, 2017). Hence, research should examine the implementation of the baselining procedure in the field to shed more light on which comparison procedure is applied. Moreover, especially against the background of recent calls to consider group-to-individual inferences (Nahari et al., 2019), results must be communicated carefully, because correlations should not be confused with absolute measures—both might even yield contradictory results. Prospects CBCA score consistency is only the precondition for using baseline statements as references when judging target statements in the field. The essential question remains whether baseline statements in fact improve CBCA judgments and credibility assessment. One way to investigate this could be to present baseline statements before having perceivers judge a target statement. Another promising research design would include more statements per person so that consistency scores could be calculated and, subsequently, baseline statements could be used to statistically predict the veracity of a target statement (Dahle & Wolf, 1997). Moreover, little is known about if and how baseline procedures are in fact applied by experts in the field. This is an important point, because the way individual baseline information is applied may well differ from the procedure presented here. Presumably, experts often do not explicitly ask for experience-based and false baseline statements. Instead, in the context of a biographical survey, the witness is often asked for experience-based experiences, not fabricated ones. These are then combined to form an intuitive experience-based baseline. However, should CBCA scores in experience-based statements indeed prove to be less consistent in better powered replication studies, this would call for caution in the use of experience-based baselines especially referring to event-related criteria (cf. above). In short, more insight is needed into whether and how baseline statements are used as a part of credibility assessment in the field. These insights might help to enhance the ecological validity of study designs and thus enable research to provide practitioners with guidelines on how to use baseline statements effectively in the field. Limitations As already mentioned, due to the low sample size, the present results must be regarded as preliminary, and studies with more power are needed. Moreover, the design of the present pilot study is not without its limitations. First, an unexpected trend emerged in the data because in contrast to fabricated target statements, experience-based target statements did not contain more CBCA scores compared to experience-based baseline statements (cf. Table 2). Whereas this might be a result of the low statistical power, it might also have emerged due to an (un-)conscious trade-off. Participants might have been more motivated to prepare and present the fictitious rather than the experience-based event, simply because it needed preparing and the task was perceived as more difficult. Future studies should thus consider including just one target statement. Such a design would not only prevent such a trade-off but would also enhance the study’s ecological validity. Moreover, in the current study, we could not control for “experience-based lying”, in which participants change actual experiences only slightly by adding false details instead of fabricating whole new accounts. Future studies should control for partly truthful events with quasiexperimental designs (that assign participants to groups based on their actual experience of a specific event, e.g., Volbert & Lau, 2013) or by applying mock-crime paradigms (e.g., Gödert, Gamer, Rill, & Vossel,2005). Conclusion The current pilot study aimed to investigate the consistency of CBCA scores as a precondition of using baseline statements on different events as within-measures in SVA. Within-measures have largely been ignored in CBCA research so far. Thus, this study is meant as a first step that will hopefully encourage more powerful studies that highlight within-subject comparisons in CBCA research (Nahari et al., 2019). Such studies should address not only CBCA score consistency but also—and maybe even more importantly—whether baseline statements actually improve the evaluation of the target statement. aConflict of Interest aThe authors of this article declare no conflict of interest. Notes 1 Note that this definition of consistency deviates from others in the credibility assessment literature in which consistency often refers to different statements by one or more persons on the same event—that is, within-statement or statement–evidence consistency (for an overview, see Vredeveldt, van Koppen, & Granhag, 2014). 2 Even in the general context of personality assessment, CBCA score consistency has—strictly speaking—no equivalent, because CBCA scores are other-ratings (by the expert) referring to the results (CBCA scores) of different tasks (baseline vs. target statements) performed by the same individual (witness). Therefore, CBCA score consistency as the basis for the baseline statement approach has yet to be investigated either conceptually or empirically. 3 The data for the current study were collected as part of a larger study with 90 participants producing 360 statements (Maier et al., 2019). However, 60 participants received a training on CBCA criteria between the first and second interview sessions and were thus not included here. Participants also completed personality questionnaires that are not considered in the current study. 4 As already stated above, the current study was part of a bigger data collection. Overall, 90 participants produced 360 statements. These were all assessed by the two raters, even though only 116 were included in the current study. The statements relevant for the current study were randomly distributed within the whole sample 5 This refers to the total of 360 statements. Cite this article as: Schemmel, J., Maier, B. G., & Volbert, R. (2020). Verbal baselining: Within-subject consistency of cbca scores across different truthful and fabricated accounts. The European Journal of Psychology Applied to Legal Context, 12, 35-42. https://doi.org/10.5093/ejpalc2020a4 References |
Cite this article as: Schemmel, J., Maier, B. G., & Volbert, R. (2019). Verbal Baselining: Within-Subject Consistency of CBCA Scores across Different Truthful and Fabricated Accounts. The European Journal of Psychology Applied to Legal Context, 12(1), 35 - 42. https://doi.org/10.5093/ejpalc2020a4
schemmel.jonas@googlemail.com Correspondence: schemmel.jonas@googlemail.com (J. Schemmel).Copyright © 2026. Colegio Oficial de la Psicología de Madrid





 PDF
PDF e-PUB
e-PUB CrossRef
CrossRef JATS
JATS Print
Print Send
SendEMAIL ALERT
The European Journal of Psychology Applied to Legal Context is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License








