


Understanding Comics. A Comparison between Children and Adults through a Coherence/Incoherence Paradigm in an Eye-tracking Study
[Comprendiendo cómics. Una comparación entre niños y adultos a través de un paradigma de coherencia/incoherencia en un estudio de movimientos oculares]
Lorena A. MartĂn-Arnal1, JosĂ© A. LeĂłn1, Paul van den Broek2, and Ricardo Olmos1
1Universidad AutĂłnoma de Madrid, Spain; 2University of Leiden, The Netherlands
https://doi.org/10.5093/psed2019a7
Received 11 February 2019, Accepted 15 April 2019
Abstract
Theories about visual narrative understanding accentuate the difference between patterns of reading comprehension in children and adults when they read text and images. This study was conducted to explore the differences in eye movement patterns when children and adults read different comic stories using a coherence/incoherence paradigm. A total of 63 participants, 31 children (10-12 years old) and 32 undergraduate university students from the Universidad Autónoma de Madrid, read 20 comic stories, each of them with both coherent and incoherent versions, for the two ending frames. Fixation durations, number of fixations, and number of regressions were recorded by an eye-tracker, Tobii x-120. A crossed random effects model was applied. Results showed that even though children reach a similar level of understanding than adults they spend more time and have longer fixations than adults, showing more effort to reach the whole comprehension of the stories. Besides, results do not detect significant differences between eye movements’ patterns in peak and release for the two groups studied, and therefore both components of the visual narrative grammar are considered equally relevant in the understanding of comics.
Resumen
Algunas teorĂas sobre la comprensiĂłn narrativa visual acentĂşan la diferencia entre los patrones de comprensiĂłn lectora en niños y adultos ante la lectura de textos e imágenes. Este estudio se realizĂł para explorar las diferencias en los patrones de movimientos oculares cuando los niños y adultos leen diferentes historias de cĂłmics utilizando un paradigma de coherencia/incoherencia. Un total de 63 participantes, 31 niños (de 10 a 12 años de edad) y 32 estudiantes universitarios de la Universidad AutĂłnoma de Madrid, leyeron 20 historias de cĂłmics, cada una de ellas con dos finales, coherente e incoherente. La duraciĂłn de las fijaciones, el nĂşmero de fijaciones y el nĂşmero de regresiones fueron registrados en un Tobii x-120. Se aplicĂł un modelo de efectos aleatorios cruzados. Los resultados mostraron que los niños, a pesar de que obtienen un nivel de comprensiĂłn similar al de los adultos, muestran un mayor esfuerzo para alcanzar la comprensiĂłn completa de las historias, como lo indican el mayor nĂşmero y tiempo de las fijaciones. Por otra parte, los resultados tampoco detectan diferencias significativas entre el patrĂłn de movimientos oculares del peak y del release entre los dos grupos estudiados, por lo que ambos componentes de la gramática narrativa visual se consideran igualmente relevantes en la comprensiĂłn de comics.
Palabras clave
Comprensión lectora, Gramática narrativa visual, Comprensión de cómics, Movimientos oculares, Seguimiento visual, Paradigma de coherencia/incoherencia, Niños y adultos.Keywords
Reading comprehension, Visual narrative grammar, Comic comprehension, Eye movements, Eye tracking, Coherence/incoherence paradigm, Children and adults.Cite this article as: MartĂn-Arnal, L. A. , LeĂłn, J. A. , Broek, P. V. D. , & Olmos, R. (2019). Understanding Comics. A Comparison between Children and Adults through a Coherence/Incoherence Paradigm in an Eye-tracking Study. PsicologĂa Educativa, 25, 127 - 137. https://doi.org/10.5093/psed2019a7
Correspondence: lorena.martin@uam.es; loreleimajere@gmail.com (L. A. MartĂn-Arnal).Reading comprehension is one of the most complex human activities. It is the product of many processes, strategies, and previous knowledge involved during reading in order to elaborate a complete mental representation (León & Escudero, 2017). This complexity is described by several theoretical models aimed at understanding the cognitive and linguistic processes involved during reading comprehension, such as the Construction-Integration Model (Kintsch, 1988), the Landscape Model (van den Broek, Rapp, & Kendeou, 2005), the Structure-Building Framework Model (Gernsbacher, 1996), or the Event-Indexing Model (Zwaan & Radvansky, 1998). In these models, cognitive processes are described as mental activities that engage to maintain both, local and global textual coherence, applied to pronouns, sentences in the text, and across larger text distances, but often applied to texts. However, there is little research on image or comics’ comprehension, focused on analyzing whether visual comprehension of comics involve cognitive processes, mental representations, strategies, or previous knowledge similar to text reading comprehension. Research in the field is also interested in building some models that propose explanations about how visual comprehension of comics and images occur (e.g., Cohn, 2013b; Cohn, Jackendoff, Holcomb, & Kuperberg, 2014). Some researchers have proposed models that understand cognitive processes on visual narrative comprehension as an organization with a hierarchic constituent structure called Visual Narrative Grammar (VNG) (e.g., Cohn, 2013a; Cohn et al., 2014). For example, Cohn and Bender (2017) claim that “VNG draws an analogy between the structure of sequential images and the structure of sentences; those panels take on functional “grammatical” roles that can be organized into hierarchic constituents” (Cohn & Bender, 2017, p. 2). This VNG resembles other previous models called “story grammars” for verbal narratives stories (see León, 1986, for a complete revision; Mandler & Johnson, 1977; Rumelhart, 1975; Stein & Glenn, 1979; Thorndyke, 1977), which grouped sentences into constituents based on characters’ goal-directed events, as well as temporary and causal relationships among events. VNG establishes an analogy between the sequential frames of a comic and the organization of a written sentence (Cohn, 2013a). More specifically, Cohn (2013b) consider that visual narratives have argued sequences of images—like those in comics—are organized by a narrative “grammar” using constituent structures that go beyond linear coherence relationships between individual images (e.g., Cohn, 2013b; Cohn et al., 2014). Then, VNG posits a structure that follows the subsequent narrative schema: a narratively coherent comic would have four main parts, similar to written stories. These four main parts would be: establisher— beginning of a narrative structure that sets up the context—, initial—beginning of the action, it starts the interaction―, peak— the action itself, the highpoint of the narrative sequence—, and release—conclusion, the consequences of the action that dissolve the narrative tension (Cohn, 2013a). This can be better understood with the help of the next example (Figure 1). Figure 1 Example of the Structure of a Visual Sequence with four Narrative Constituents.  Another important thing about VNG is that it postulates a merging between narrative structure and meaning that cannot be split up (Cohn et al., 2014; Cohn & Kutas, 2015; Cohn, Paczynski, Jackendoff, Holcomb, & Kuperberg, 2012). Every one of these four parts has its importance. The “release”, for example, gives the final clue to the comprehension of the whole story, as forward connections of events―connections with the consequences of events―tend to have more recall than backwards connections in films (or comics) and in written narratives (León et al., 2015; León & Pérez, 2001; van den Broek & Lorch, 1993; van den Broek, Lorch, & Thurlow, 1996). The “peak” is seen as one of the most important parts, because the action itself happens within it (Cohn et al., 2014). The “establishers” and “initials” are also important, as Gernsbacher (1996) postulated with the Structure Building Framework theory, where the first step to construct comprehension of units that are larger than a word or image is laying a foundation, hence, readers/viewers have to spend more time and number of fixations on these first parts of stories. Given the importance of these theories for visual understanding, our study will deal with this VNG considering these four components (establisher, initial, peak, and release), where we will apply a paradigm of coherence vs. incoherence for the two most important components (peak and release). Eye Movements in Children and Adults when Reading Text and Comics In the last decade several experiments aimed to describe cognitive processing through eye tracking (e.g., König et al., 2016), which have proven to be a good measure of reading (Rayner, 2009). Eye movements during reading are under direct cognitive control (e.g., Rayner, 1978, 1998). This direct cognitive control is revealed when a reader fixates―which words they skip or regress to and where they land in words―and by analyzing how long they fixate on words. Both provides a great deal of useful information about moment-to-moment processing during reading. As such, our understanding about our reading skill and about how this process is developed has been learnt greatly by monitoring readers’ eye movements and by attempting to infer the basic cognitive processes underlying reading. Moreover, although there are several different paradigms when searching for images studies (Rayner, 2009), very little research analyse deep comprehension with images, particularly if they lean on eye movements control. Thus, the aim of this study dives deep into the relation between age and coherence when adults and children read comic strips without any word. There is an extensive literature about differences in reading processing when comparing beginners and skilled readers who read sentences or texts. For example, opposing beginners to skilled readers, children who are at the beginning of the reading process have longer fixations, shorter saccades, more re-fixations, and make many regressions (e.g., Huestegge, Radach, Corbic, & Huestegge, 2009; Vorstius, Radach, & Lonigan, 2014). Patterns of eye movements revealed that children (from grades 2 to 6) showed some difficulty decoding words while reading (see Blythe, 2014; Leinenger & Rayner, 2017 for reviews). There is evidence suggesting that developing readers are less efficient at identifying printed words (e.g., Aghababian & Nazir, 2000). However, results of studies using the “disappearing text paradigm” have revealed that children as young as seven years old can capture visual information similarly to skilled adult readers (Blythe, Liversedge, Joseph, White, & Rayner, 2009). Other studies have demonstrated that, even for beginner readers, more exposure to a given word speeds identification and eye movements are under direct cognitive and linguistic control (e.g., Hyönä & Olson, 1995; Joseph, Nation, & Liversedge, 2013). Visual extraction, then, occurs at a normal rate, but beginner readers simply encode less visual information than skilled adult readers on a given fixation. That is to say, they take in visual information at the same rate, but from a reduced region (Leinenger & Rayner, 2017). Results of studies that used the “moving window paradigm” to directly investigate developing readers’ perceptual spans support the idea that developing readers take in less visual information per fixation. These and other authors also say that reading skill influences the perceptual span, since the difficulty of encoding the fixated word could lead to a reduction in the span for beginning readers (Häikiö, Bertram, Hyönä, & Niemi, 2009; Rayner 2009; Rayner & Duffy, 1986). These studies confirm that developing readers have smaller perceptual spans, which reach adult size around fourth grade (Häikiö et al., 2009; Rayner, 1986). A possible explanation for this reduced perceptual span could be that it changes as a function of text difficulty, instead of being a consequence of different eye movements’ patterns between children and adults. Thus, the size of the perceptual span can be reduced when more attention and resources are used to process the foveal word. In fact, skilled readers could seem beginner readers when they are presented texts that are too difficult for them (Rayner, 1986). This suggests that beginner readers have smaller perceptual spans because of the difficulty they experience processing foveal words (Leinenger & Rayner, 2017). Regarding reading processes in scene or images perception there are controversial findings due to the different paradigms and the conditions and design controls of the experiments. Across different cultures, readers need congruence when they are trying to understand any story, no matter if it is text, comic, or any other format. There is a need of semantic and structural/syntactic coherence. If one of them is missing, both, text and image reading, can be affected (Cohn, 2014a; Rayner, 2009; Yang, Wang, Chen, & Rayner, 2009). Some results could be taken from the little research on sequence images or comics. Cohn (2014b), for instance, found a correlation between the ability to order images correctly and the age and experience of the participants when reading comics. Some recent research points out that eyes are guided by the saliency of the scene. That is, they tend to fixate unusual parts of scenes first. As far as researchers have known, beginning readers use to have longer fixations, shorter saccades, and more regressions than skilled readers (Rayner, 2009). There are also differences in patterns of reading comprehension for sentences and images in children and skilled readers (Leinenger & Rayner, 2017). Thus, given that there are not previous research on differences between children and adults, this will be one of the main objectives of this study. Objective The aim of this study was to analyse how two frames of comic stories—peak and release—affect online selective processing of story comprehension—e.g., number of fixations, fixation duration, and regressions—through a coherent/incoherent paradigm of short four frames comic strips, and how these patterns relate to strategies children and adults use for reading comprehension. To do so, we will present the participants some four frames comic strips, changing their sense of coherence by varying the relative positions of the two main characters in the two last frames―peak and release. Therefore, our main hypotheses is that reading comprehension—and its eye-tracking patterns—will be affected by both, the age of participants and the coherence of stimuli. Resulting from this idea, there are some main research questions and some derived—also interesting—research questions that we would like to answer:
Participants We recruited for this study a total of 63 participants, 32 undergraduate university students from the Universidad Autónoma de Madrid with an age range from 18 to 24 years old (5 male, 15.60%; 27 female, 84.40%), who received a reward for their participation, and 31 children from 10 to 12 years old (12 females, 38.71%; and 19 males, 61.29%), from the Hipatia Fuhem school in Madrid. All of them volunteered for the experiment and had good natural or corrected vision. Their native language was Spanish. All participants gave a written consent according to Autónoma University’s Human Subjects Review, and an authorization of the parents and the educational centre-only for the children. Design There are three independent variables in our design: coherence—coherent vs. incoherent—, frame—peak vs. release—, which are both within―subjects variables, and age group—adults vs. children—, which is a between-subjects variable. The construct that we are studying, reading comprehension, was operationalized through several DVs: on one hand, four eye-tracking measures as an on-line procedure and, on the other hand, an off-line procedure consisting of a success/error test to check if participants understood stories properly, as described below. The on-line eye-tracking measures were: mean fixation duration —mean duration (milliseconds, ms) of the fixations on each of the two frames—; number of fixations —the sum of all fixations that participants make on AOI (areas of interest), defined as each of the frames, peak and release—; total fixation time—the total duration of all fixations on a frame, which encompasses both, durations and frequency of fixations—; and number of regressions in—the sum of times that one of the frames was revisited after the first fixation on each one of them. Second pass fixation time proved to be an important measure of deeper processing—higher order processing—, cognitive and intentional, during reading (Jian, Wu, & Su, 2014); it is important for comprehension (Rayner, 1998) and for integration of information (Mason, Tornatora, & Pluchino, 2013). Moreover, total fixation time on pre-specified areas of interest―like the ones in this experiment—is a useful measure to reveal how readers look at the whole AOI during the entire trial. It shows how much time is spent fixating it (Hyönä, 2010); thus, it was decided to use it to ensure the whole reading/viewing process is englobed in this study about comprehension, that is why total fixation time is included in the analysis. However, first pass fixations are also important for initial processing of features of the images and texts (Jian et al., 2014), that is why mean fixation duration is also included, despite the fact that it could sound redundant together with total fixation time. The off-line measure was operationalized with a question about the detection of any anomaly in the comic, where it was, and which that anomaly was. Participants were asked to tell if they saw something weird or the whole comic strip made sense. Materials and Apparatus An eye-tracker Tobii–x120, which runs at 120 Hz, was used to register eye movements in the present study. Besides, stimuli were presented on a 15” computer screen. There was no need of a chin, because Tobii–x120 allows to move within a 30 x 22 x 30 cm cube—width, height, and depth—, being at 70 cm of distance from the screen. Stimuli used in this study were ten comic strips created and drawn by us—and three more trial strips—. Each stimulus tells a different story. The structure of each stimulus follows Cohn’s (2013b) Visual Narrative Grammar (VNG) pattern: establisher, initial, peak, and release. All four of them appeared at the same time on the screen, in order, as a comic strip. Coherence was manipulated by changing the position of the characters either on the peak or on the release—thus, creating three coherence conditions: “coherent”, where both frames were correct, “incoherent peak”, where the peak had the change of the character’s position, and “incoherent release”, where the release had the change of the character’s position. Final stimuli appeared as shown in the examples of Figure 2―the purple arrow did not appear on the presentation of the stimuli. Figure 2 Structure of a Visual Sequence with Narrative Constituents in the Three Versions Analysed in this Study: Coherent Version, Incoherent Peak Version, and Incoherent Release Version. 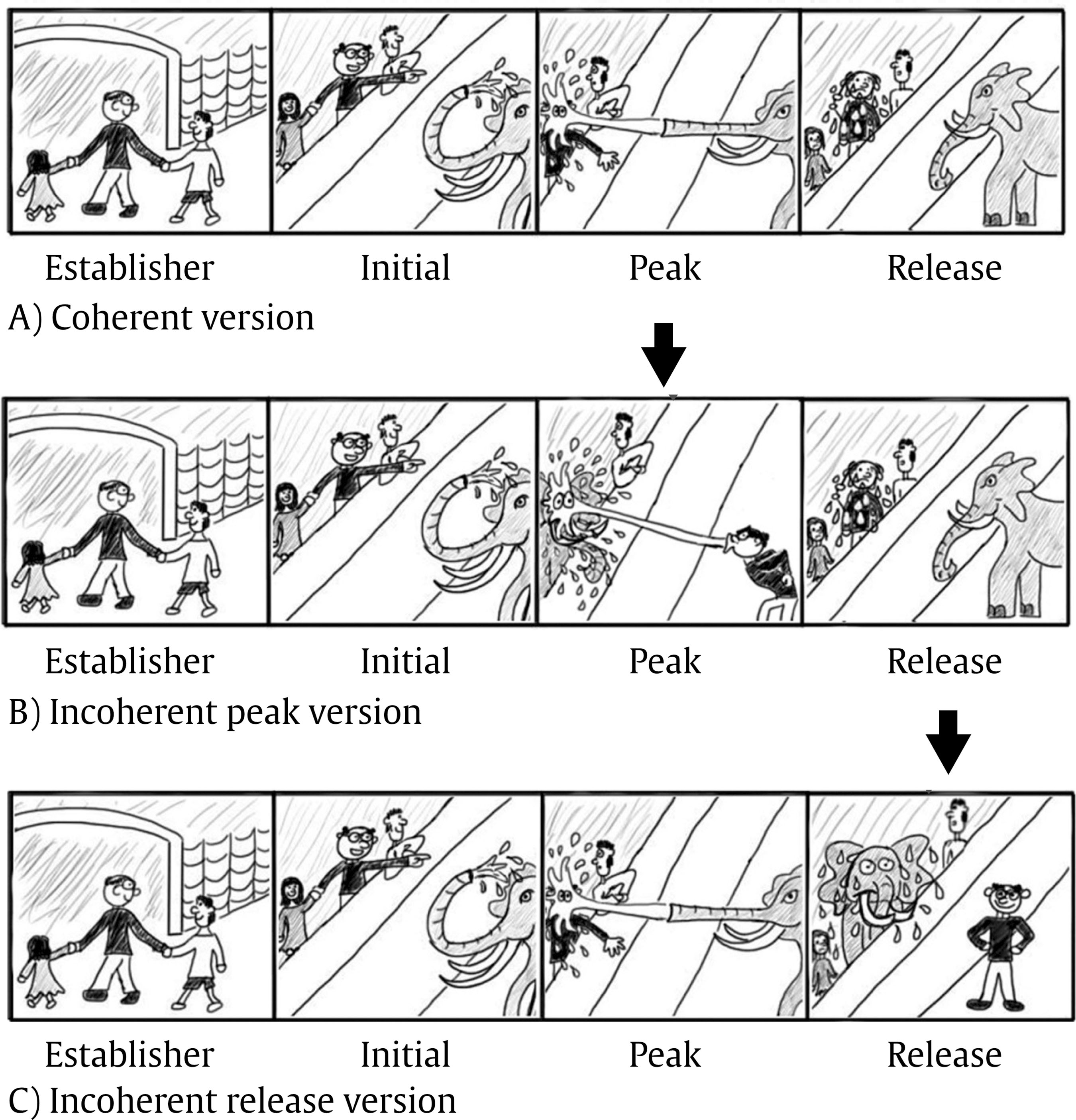 Procedure The experiment was administered to participants individually. Each participant, after reading the details of it and signing the informed consent, was seated in front of the visualizing screen, where the corresponding stimuli would be presented. The eye-tracker was situated under this screen, without any obstruction of the participant’s line of sight towards it. When a participant was seated and comfortable, instructions were presented on the screen, with all the time he/she needed to read them, and any doubt about them was solved. They were warned about the three trial stories before the real test. Besides, they were informed that their oral answers would be recorded starting to record at that moment, in order to transcribe them afterwards. Once there were no doubts, participants were shown their eyes on the screen and they were briefly explained how the machine worked, captured and followed their pupils, allowing them to slightly move, move their eyes, blink, and wink an eye to check it. After that, we proceeded with a nine-dot calibration, which we repeated as many times as needed until it reached the most optimal adjust. When the calibration succeeded, participants were aware of not moving beyond the imaginary window explained before, so the eye-tracker did not lose their gaze. The next step was beginning the test. The presentation sequence of the stimuli was randomized, as well as the presentation of the coherence version of each stimulus. Therefore, all subjects viewed every stimulus in one of its three versions; besides, subjects viewed all coherence versions, but only one of them for each stimulus. Stimuli appeared on screen as follows:
Evaluation and Statistical Analysis Once all the oral answers were transcribed for the off-line measure—correct or incorrect answers depending on the correct/incorrect detection of an anomaly—, they were categorized into: a) “correct”, when they detected an anomaly based on an incoherent frame; b) “incorrect”, when there had been no detection of an anomaly that was there, due to a misunderstanding of the story, or when there had been a detection of an anomaly that was not there, due to other weird or illogical explanations; and c) “ambiguous”, when the anomaly had been detected, but the answer had been illogic or when there had been a detection of an anomaly that was not there, due to a new, logical explanation. In this last case, answers of this kind were less than a 2.50% of the total sample, so the final decision was to treat them as “incorrect”, giving as a result a final categorization of correct/incorrect answers. Both, these and the data from the four on-line eye movements’ measures—namely, mean fixation duration, number of fixations, total fixation time, and number of regressions in—were statistically analysed with the SPSS v23 software, offering results that are shown next. As we have two random effects, a crossed random mixed model (Hoffman & Rovine, 2007) was conducted to study our coherence, age group, and frame factors. The two crossed random effects were items―comics―and subjects. A total of 15 parameters were estimated. Twelve fixed effects were analysed―the intercept, the age group effect, the frame effect, the coherence effect (two parameters), and the interactions between age group and coherence (two parameters), age group and frame, frame and coherence (two parameters), and age group, frame, and coherence (two parameters) effects. Also, three random effects were estimated: two random intercept variances for items and subjects respectively and level-1 residual variance. Concerning the distribution of the measures, mean was 3.87—by image— for number of fixations, 347 ms for mean fixation duration, 1,345 ms for total fixation time, and 1.02 for number of regressions in. Standard deviation was 2.14 for number of fixations, 100 ms for mean fixation duration, 809 ms for total fixation time, and .902 for number of regressions in. The asymmetry index was 1.04 for number of fixations, 1.889 for mean fixation duration, 1.05 for total fixation time and .717 for number of regressions in. Hence, there was some indication of positive skew in the distribution of all the measures (i.e., violation of normality), but the amount of skewness was similar for all conditions, and given that it is reasonable to think that it will not constitute an important problem in the estimations of model parameters (Pardo & San Martin, 2015). There were also occasional outliers but not enough to affect the analyses. We conducted analyses on both the log-transformed data and the untransformed data with identical patterns of results. Therefore, we have reported the results of analyses in the untransformed data. Table 1 Fixed and Random Effects for Age Group, Coherence and Frame for Mean Fixation Duration, Number of Fixations, and Total Fixation 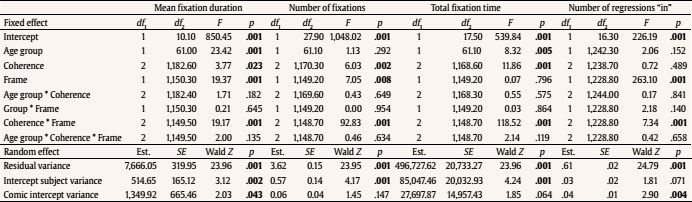 Correlations between the four eye tracking variables were also measured for all the frames and conditions, for all the frames dividing the sample into the three different conditions, and for peak and release only, with the total sample and dividing it into the three conditions too. Results always showed high correlations (p < .001) between number of fixations and total fixation time, and between mean fixation duration and total fixation time, but not between mean fixation duration and number of fixations. These results were expected, because mean fixation duration (first pass measure) is, in fact, part of total fixation time, and this and the number of fixation are both global measures (first pass and second pass measures). Success/Error Beginning with the off-line measure, it starts from very acceptable percentages of success in the answers: On one hand, adults had a mean of success in the answers of the causal question of 88.43%, their median was 90%, and ranged from 70% to 100%, except for one participant, who succeeded in 60%. This indicates that all but one adult that underscored beneath 65%—number of successes considered acceptable in previous literature (e.g., León, 2003; León y Escudero, 2003; León y Pérez, 2001; León, Solari, Olmos y Escudero, 2011)—had a high comprehension of the stories. On the other hand, children obtained a mean of successes of 71.94%, a median of 80%, and ranged from 70% to 100%. In this case, there were seven exceptions, with 30%, 30%, 40%, 40%, 50%, 50% and 60% of success, beneath the acceptable 65%. This data lead us to think that comprehension of the stories was also high for children, except for these seven cases. Therefore, given that the number of participants with success under an acceptable percentage is very low—eight participants that represent less than a 13% of the total sample—we decided not to drop these participants, in order to have a more realistic sample. Notwithstanding, most of the analyses were replicated, suppressing these eight participants to be sure that they were not adding noise to the data, and no substantial change was found. Hence, it is worth saying that the registered eye-tracking data are attributable to deep comprehension processes in a way that will be explained in further sections. Eye Movements Results First of all, the analysis was divided into two groups: a) only the coherent condition was analyzed to see whether there were differences due to the age group independent variable―i.e., between children and adults―and due to the frame independent variable―i.e., between the peak and release means, along with establisher and initial means. Random comic and subjects intercept variances were included in the mixed model, too. The same approach was taken with the analyses of all the measures: mean fixation duration, number of fixations, total fixation time, and number of regressions in―all of them defined in the previous section―, and it seized a baseline with which to b) compare the results obtained from our experimental paradigm with the three set variables. Hence, a second mixed model was conducted for each of the three variables. In this model, three independent variables were analyzed: age group―children and adults―, frame―peak and release―, and coherence―coherent, incoherent peak, and incoherent release. Again, random effects for subjects and comics intercepts were included. All the fixed effects and random effects are shown in Table 1. Coherent version Mean fixation duration. Only the age group fixed effect was significantly different from zero, F(1, 59) = 7.42, p = .008. The average fixation duration for coherent comics for children was 353 ms (SE = 9.70) while for the adults it was 331 ms (SE = 9.80). Besides, only marginally significant differences in fixation duration means were found between establisher (M = 343, SE = 10.40), initial (M = 331, SE = 10.30), peak (M = 340, SE = 10.30) and release (M = 354, SE = 10.30) frames, F(3, 727) = 2.52, p = .057. There was no significant interaction found between age group and frame effects, F(3, 727) = 1.28, p = .283. The random effects showed that subjects intercept variance was significant (σ2subject = 409.880, Wald Z = 2.280, p = .023) and comic intercept variance was marginally significant (σ2comic = 625.146, Wald Z = 1.796, p = .072). The estimated residual variance was 7,282.223 (Wald Z = 19.027, p < .001). Mean fixation durations are shown in Figure 3. Figure 3 Mean Fixation Durations for Children and Adults and All the Four Frames for Coherent Stories: 1 (establisher), 2 (initial), 3 (peak), and 4 (release). 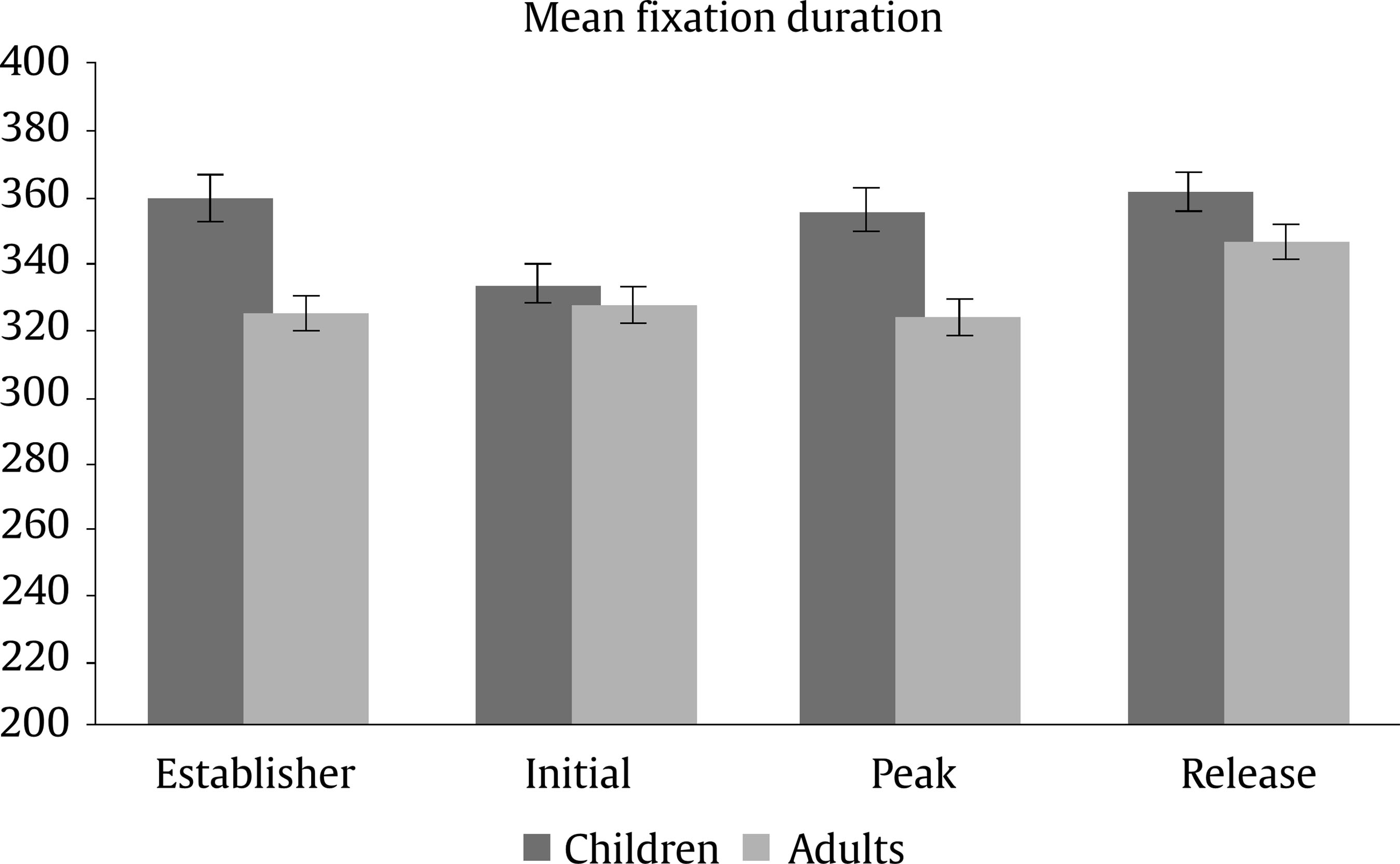 Number of fixations. Results only showed a significant main effect of the frame condition, F(3, 735) = 22.16, p < .001. The release (M = 4.33, SE = 0.1) received on average more fixations than the peak (M = 3.95, SE = 0.1). There was only a marginally significant effect for the age group variable, F(1, 63) = 3.45, p = .068. There was no significant effect for the interaction between age group and frame conditions, F(3, 735) = .35, p = .790. The random effects showed that subjects intercept variance was significant (σ2subject = .196, Wald Z = 2.316, p = .021) and comic intercept variance was not significant (σ2comic = 0, Wald Z = 0, p = 1). The estimated residual variance was 3.494 (Wald Z = 19.133, p < .001). Mean fixation durations are shown in Figure 4. Figure 4 Number of Fixations for Children and Adults and all the Four Frames for the Coherent Condition: 1 (establisher), 2 (initial), 3 (peak), and 4 (release). 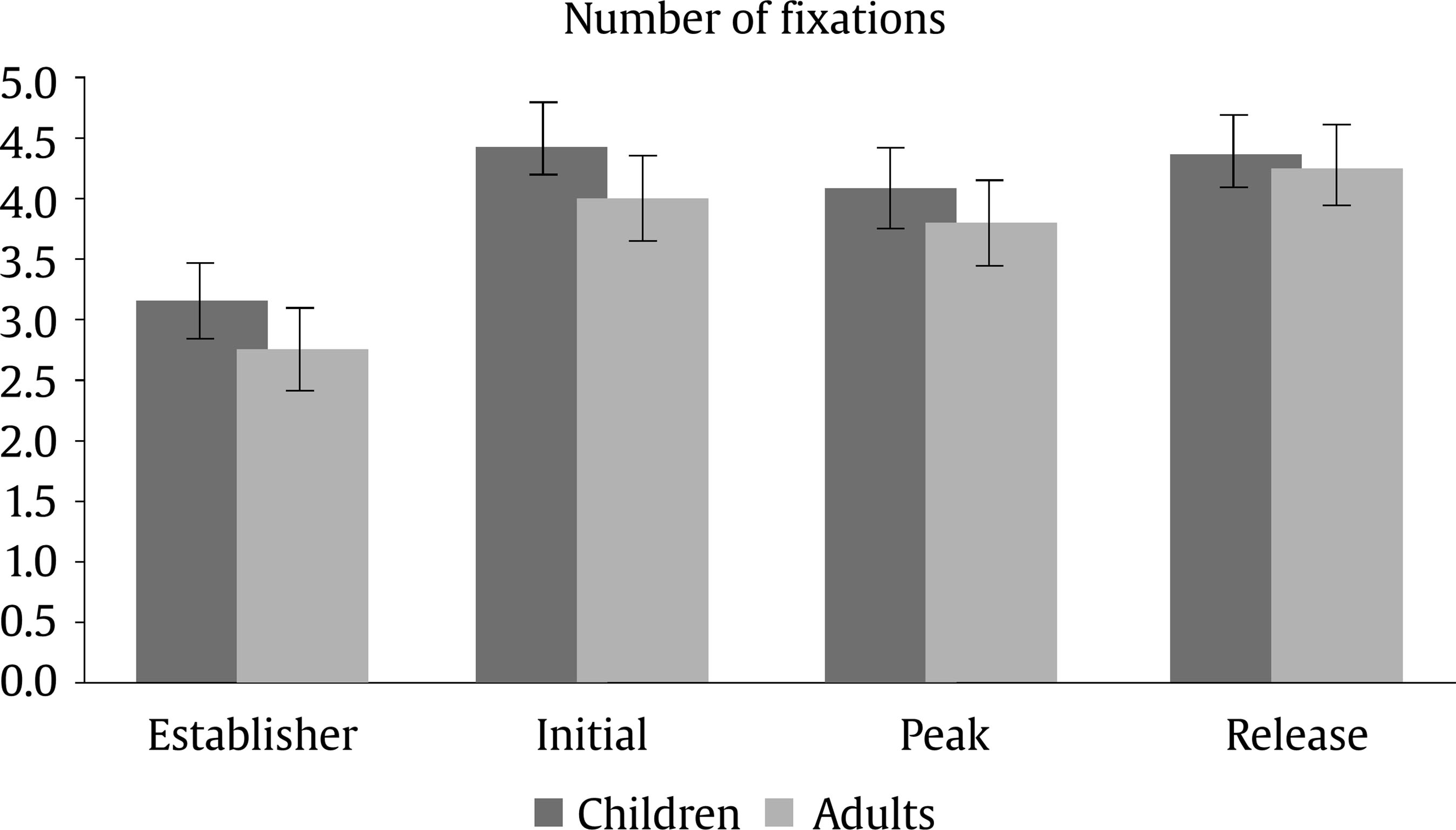 Total fixation time. Results showed significant main effects of the frame variable, F(3, 727) = 18.63, p < .001, and the age group variable, F(1, 60) = 10.17, p = .002. For the frame, the release (M = 1,521, SE = 53.10) showed more total fixation time (ms) on average than the initial (M = 1,406, SE = 53.40), the peak (M = 1,337, SE = 53), and the establisher (M = 1,018, SE = 54.50), in that order. For the age group, children (M = 1,419, SE = 44.30) showed more total time (ms) on average than adults (M = 1,222, SE = 45). There was no significant effect of the interaction between age group and frame conditions, F(3, 726) = .33, p = .807. The random effects showed that subjects intercept variance was marginally significant (σ2subject = 21,061.070, Wald Z = 1.940, p = .052) and comic intercept variance was not significant (σ2comic = 750.201, Wald Z = 0.219, p = 827). The estimated residual variance was 483,709.602 (Wald Z = 19.016, p < .001). Total fixation times are shown in Figure 5. Figure 5 Total Fixation Time for Children and Adults and all the Four Frames for the Coherent Condition: 1 (establisher), 2 (initial), 3 (peak), and 4 (release). 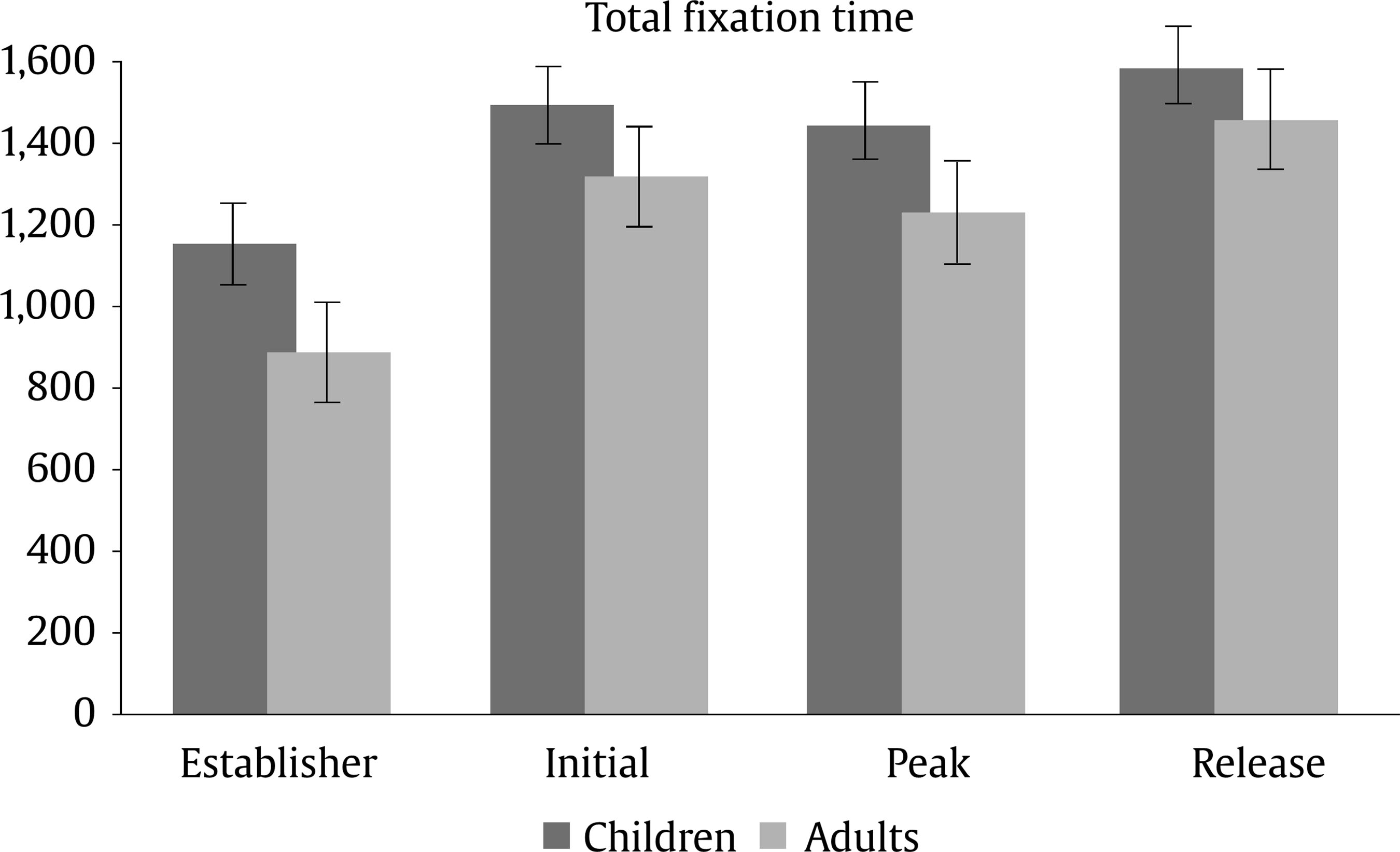 Regressions in (times revisited). Results only showed significant main effects of the frame variable, F(1, 380) = 73.44, p < .001, where the peak (M = 1.38, SE = .1) showed more regressions in than the release (M = .70, SE = .1). There was no other significant effect, neither of the age group condition, F(1, 407) = 0.37, p = .54, nor of the interaction between age group and frame conditions, F(1, 380) = 2.25, p = .13. The random effects showed that subjects intercept variance was significant (σ2subject = 0.055, Wald Z = 2.067, p = 0.039) and comic intercept variance was not significant (σ2comic = 0.033, Wald Z = 1.417, p = .157). The estimated residual variance was 0.656 (Wald Z = 13.789, p < .001). The number of regressions in is shown in Figure 6. Figure 6 Number of Regressions in for Children and Adults and the Two Final Frames for the Coherent Conditions: 3 (peak), and 4 (release). 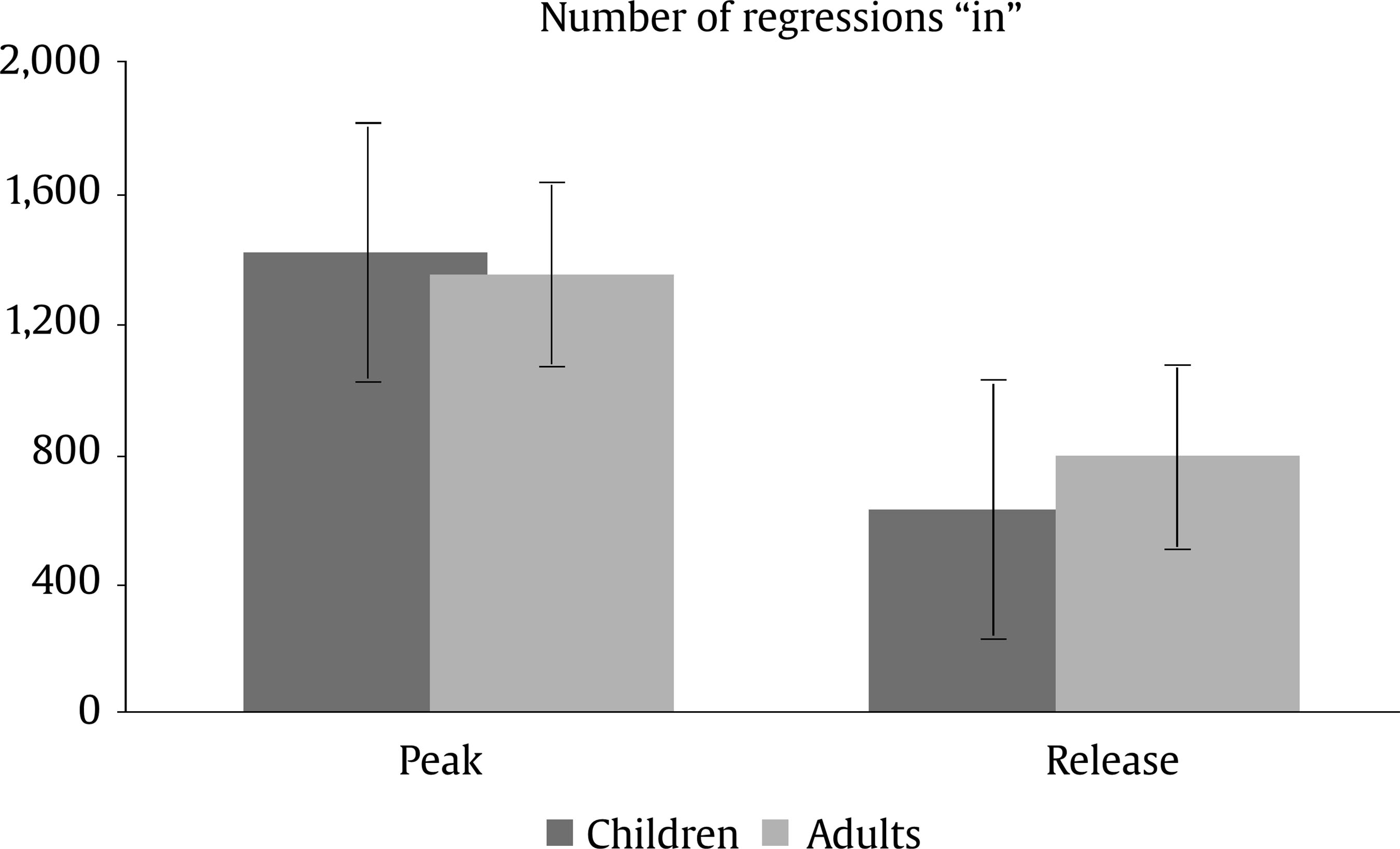 Complete analysis version (coherence vs. incoherence) Mean fixation duration. The main effect of age group was significant (p < .001), as children’s fixation durations (M = 375, SE = 12.80) were longer than adults’ fixation durations (M = 338, SE = 12.80). The interaction effect between coherence and frame was also significant (p < .001). The three-factor interaction was not significant, F(2, 1150) = 2.00, p = .135). Table 2 and Figure 7 show the results. Table 2 Means and SE for Age Group, Coherence, and Frame for Mean Fixation Duration 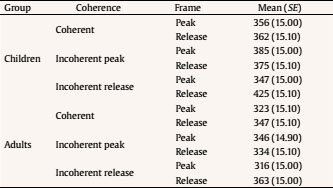 Figure 7 Mean Fixation Durations for Children and Adults together and the Two Final Frames for the Three Conherent Conditions: Peak (dark grey column) and Release (light grey column). 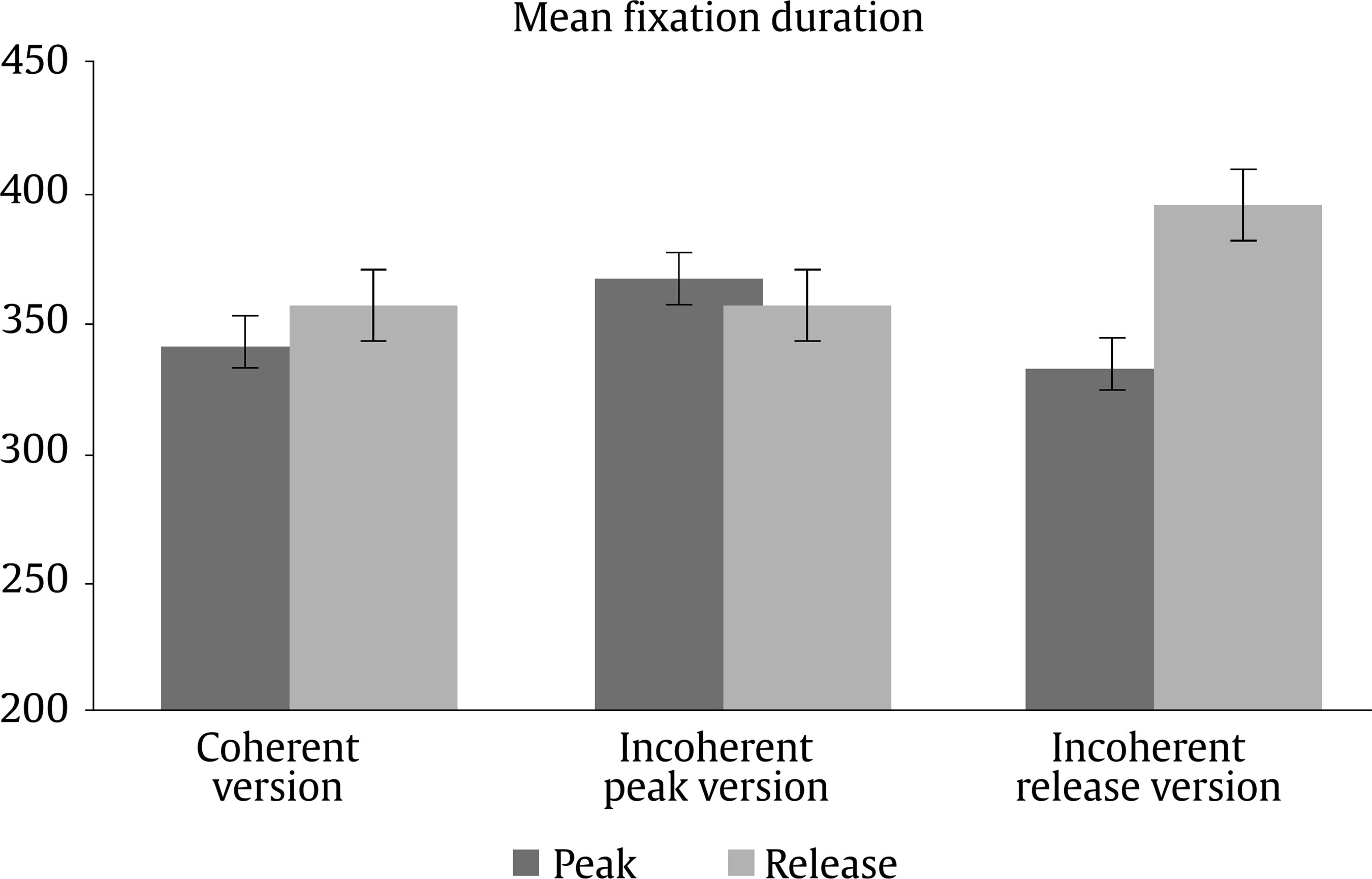 The interaction effect was clear as incoherent peak showed a different pattern than incoherent release. Simple effects showed that peak and release fixation duration means did not differ significantly in the coherent and incoherent peak conditions, while they did significantly differ in the incoherent release condition. The mean difference for the coherent condition was 15 (p = .090), being the release the frame with longer durations. The mean difference for the incoherent peak condition was 12 (p = .176), being the peak the one with longer fixations. The differences between coherent and incoherent peak conditions only differ in 3 ms. However, the mean difference for the incoherent release condition was 63 (p < .001), being the release the one with longer fixations and longer than any other frames in any other conditions. The differences between coherent and incoherent release conditions differ in 48 ms. Thus, comparing the differences between both frames using the coherent condition as a baseline, the distance with incoherent release condition is higher than that with incoherent peak condition. Number of fixations. The interaction effect between coherence and frame was significant again (p < .001). The three-factor interaction was not significant, F(2, 1149) = 0.46; p = .634. Table 3 and Figure 8 show the results. Table 3 Means and SE for Age Group, Coherence, and Frame for Number of Fixation 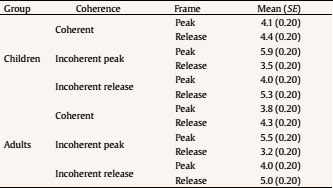 Figure 8 Number of Fixations for Children and Adults together and the Two Final Frames for the Three Coherence Conditions: Peak (dark grey column) and Release (light grey column). 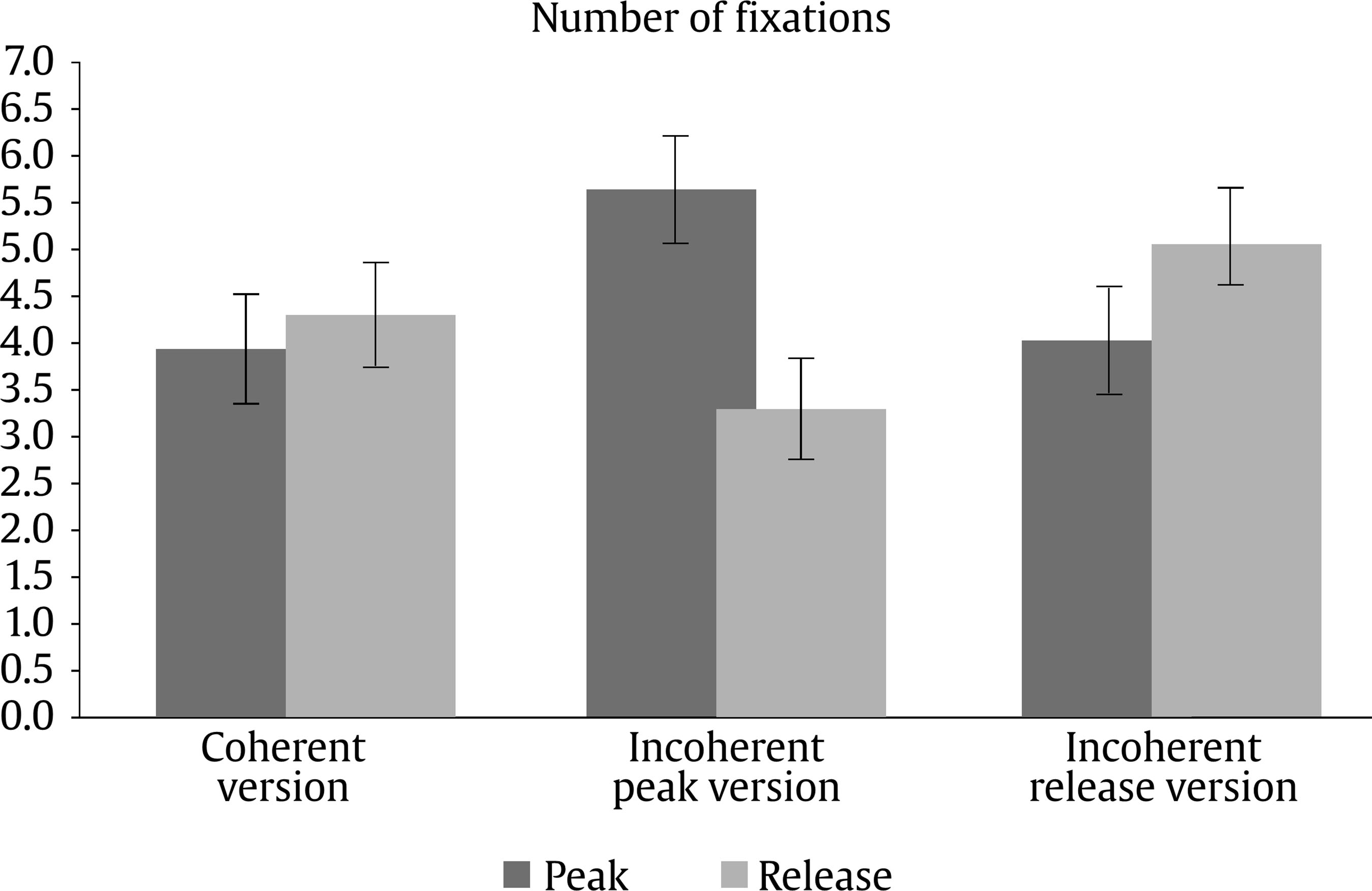 The interaction effect was clear again. Simple effects showed that number of fixations on peak and release differed significantly in the coherent, incoherent peak, and incoherent release conditions. However, these differences were not under the same significance level: while the p level for the coherent condition was p = .046 (mean difference = .38, p < .05), it was p < .001 for both the incoherent conditions (mean difference for the incoherent peak = 2.33 and mean difference for the incoherent release = 1.1). Besides, as we can see in Figure 8, despite the significances of the differences, the pattern, again, was: for the coherent condition and the incoherent release condition, the release was the frame with more number of fixations, while for the incoherent peak condition the opposite was happening, it was the peak the one with more fixations. Also, the distance between the difference in coherent and incoherent peak conditions (1.95 fixations) is higher than that in coherent and incoherent release conditions (0.63 fixations). Total fixation time. The main effect of age group was significant (p = .005) once again, as children’s total fixation time (M = 1,684, SE = 79.50) was longer than adults’ total time (M = 1,442, SE = 79). The interaction effect between coherence and frame was significant again (p < .001). The three-factor interaction was not significant, F(2, 1149) = 2.14; p = .119. Table 4 and Figure 9 show the results. Table 4 Means and SE for Age Group, Coherence, and Frame for Total Fixation Time 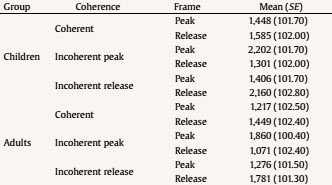 Figure 9 Total Fixation Time for Children and Adults together and the Two Final Frames for the Three Coherence Conditions: Peak (dark grey column) and Release (light grey column). 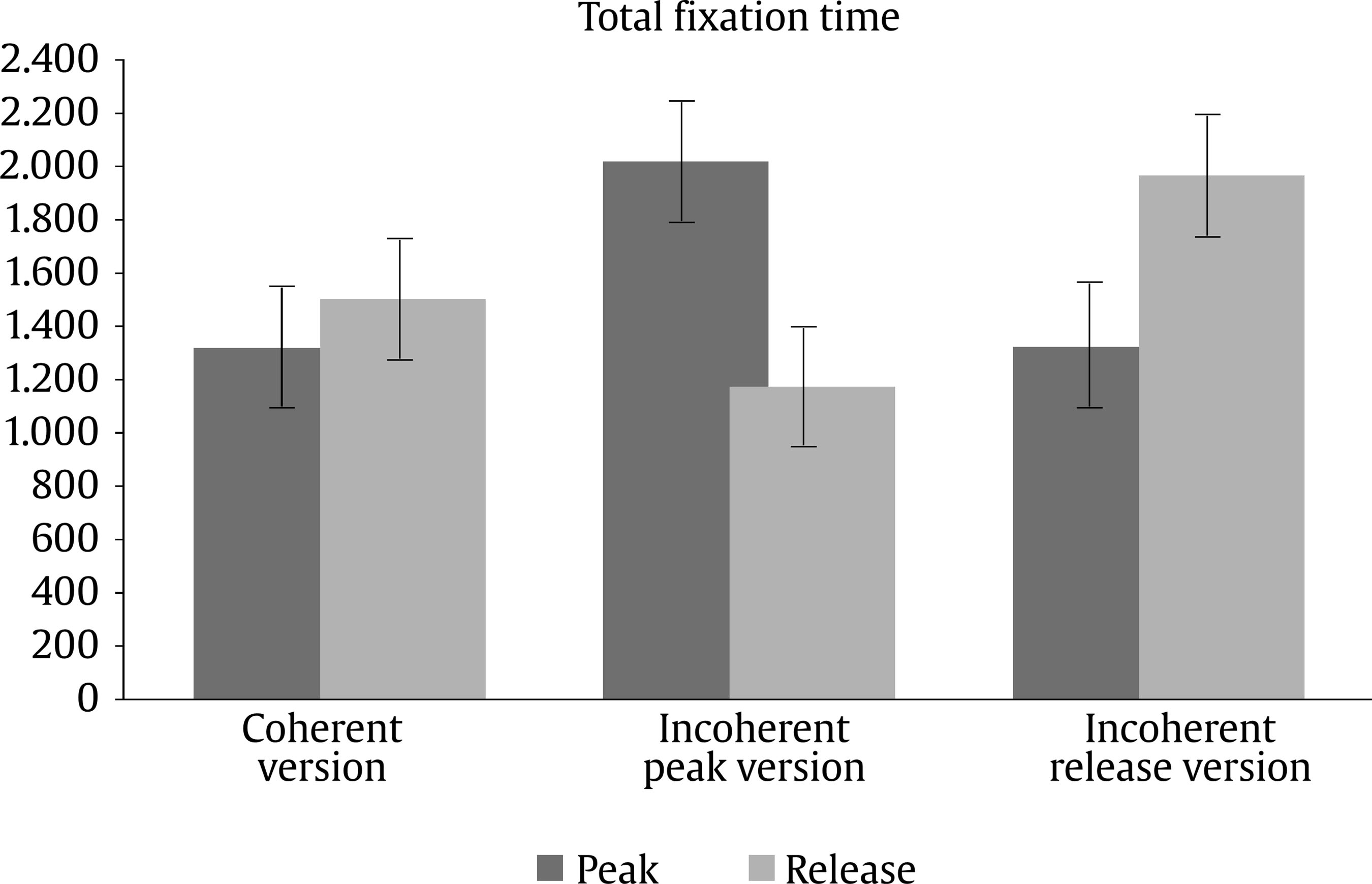 The interaction effect was once more, very clear. Simple effects showed that peak and release fixation duration means differ significantly in the coherent (mean difference = 184, p = .009), incoherent peak (mean difference = 845, p < .001) and incoherent release (mean difference = 629, p < .001) conditions. Besides, as we can see from Figure 9, the pattern was the same as for mean fixation duration and number of fixations: for the coherent condition and the incoherent release condition, the release was the frame with more total fixation time, while for the incoherent peak condition it was the peak the one with a higher total time. Once more, comparing the differences between both frames using the coherent condition baseline, the distance with incoherent peak condition (661 ms) is higher than that with incoherent release condition (445 ms). Regressions in (times revisited). Only frame main effect was significantly different from zero, F(1, 1229) = 263.10, p < .001. However, non-significant differences in number of regressions in were found, nor for age group condition, F(1, 1242) = 2.06, p = .152, neither for coherence condition, F(2, 1239) = 0.72, p = .489. There was a significant interaction between coherence and frame, F(2, 1229) = 7.34, p = .001. The three-factor interaction was not significant, F(2, 1229) = 0.42, p = .658. The estimated means and standard deviations (SD) are shown in Table 5 and Figure 10. Table 5 Means and SE for Age Group, Coherence, and Frame for Number of Regressions in 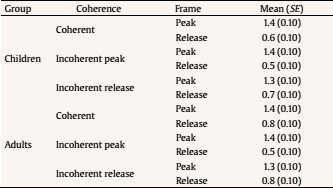 Figure 10 Number of Regressions in (NoRI) for Children and Adults together and the Two Final Frames for the Three Coherence Conditions: Peak (dark grey column) and Release (light grey column). 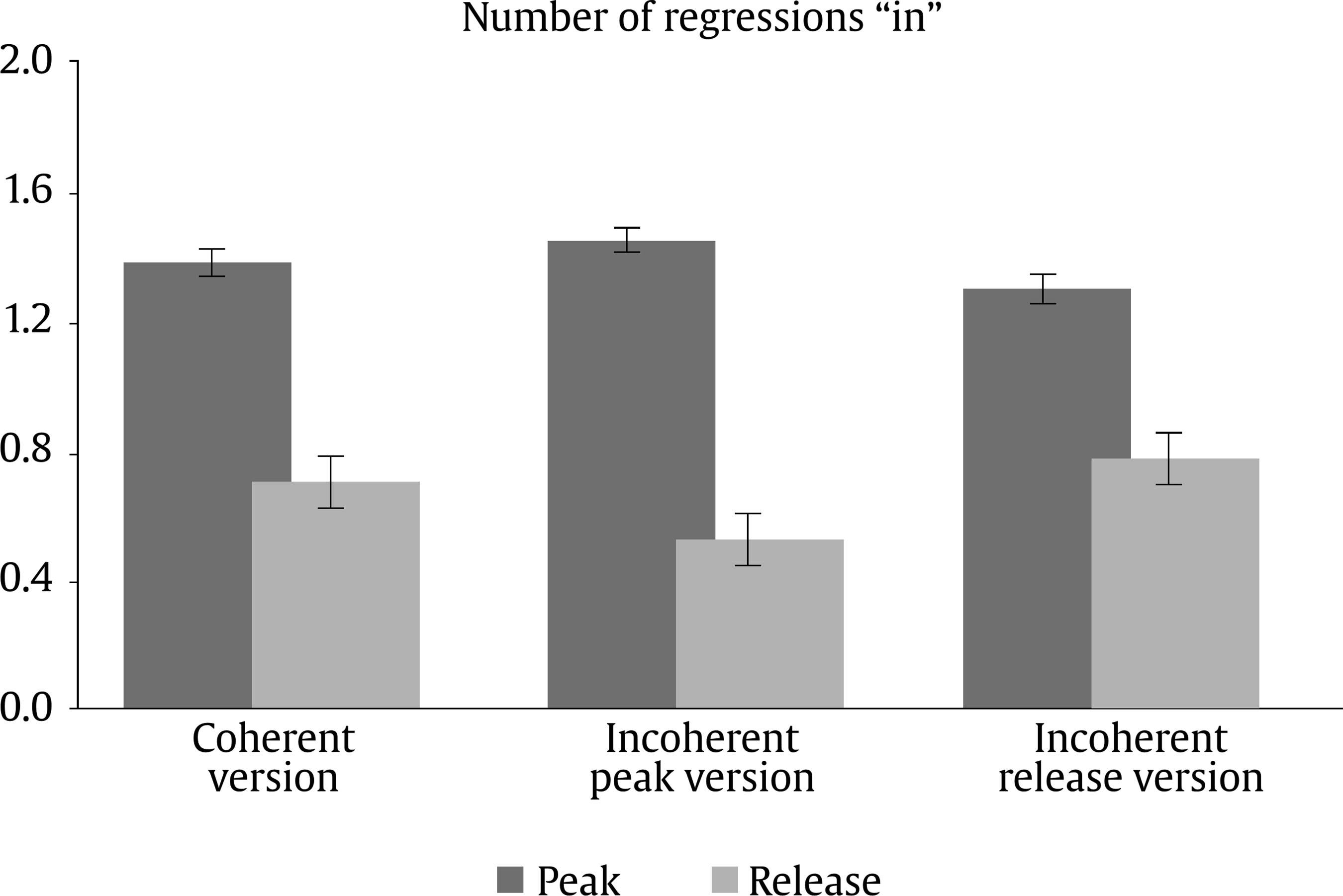 The interaction effect, as shown in Figure 10, was clear as incoherent peak showed a different pattern than incoherent release. Simple effects showed that all differences between peak and release were significantly different for the three coherence conditions. However, this difference was higher for the incoherent peak condition (M = 0.93, SE = 0.10) than for the other two conditions, coherent (M = 0.68, SE = 0.10) and incoherent release (M = -0.53, SE = 0.10), being the peak higher than the release in all conditions. This time, using the coherent condition as a baseline, the distance with incoherent peak condition (0.25 regressions) is less than that with incoherent release condition (1.21 regressions). Curiously, neither coherent peak differed from incoherent peak (MD = 0.07, p =.367), nor coherent release differed from incoherent release (MD = 0.07, p =.367). However, incoherent peak significantly differed from coherent peak of the incoherent release condition (MD = 0.15, p = .048), being higher the NoRI―number of regressions in― for the peak on incoherent peak condition, and incoherent release significantly differed from coherent release of the incoherent peak condition (MD = 0.26, p < .001), being higher the NoRI on release of the incoherent release condition. In addition, coherent release significantly differed from coherent release of the incoherent peak condition (MD = 0.19, p = .015), being higher the NoRI for the release on coherent condition. Some interesting patterns regarding the “coherent” version only―which means normal comic reading―were found. First finding is that children, despite they reach very good percentages of success and almost the same level of understanding than adults―72% vs. 88%―, spend more time when reading. Thus, their reading abilities seem to be less efficient, as happens with beginner readers. Therefore, to answer our first research question, children had more and longer fixations than adults, so it seemed that their eye movements’ patterns showed more effort to reach the whole comprehension of the stories. Furthermore, this variable did not interact with the others in any of the analyses that were made. This gives us some clues: first, to address the second research question, there is no difference between eye movements patterns on peak and release due to the age differences of the two participant groups; second, this difference between children and adults remains the same for all the coherence versions, which leads to the conclusion that children are sensitive to coherence changes in the same way as adults are. Therefore, taking in account for a moment the coherence conditions, this, as an answer to the fifth research question, points out that children and adults are not affected differently by incoherence. Thus, this experiment seems to be proving that there is a control of eye movements in order to reach the best understanding of the stories, like some authors already argued (Luke, Nuthmann & Henderson, 2013; Schotter, Tran, & Rayner, 2014) and we advanced in previous sections of this paper. Nevertheless, it is a new―and surprising―finding that this fact is similar for both, children―assuming that they are less skilled―and adults―assumed to be more skilled―, and that there is no difference at all between them. Of course, these conclusions were drawn from the absence of interaction between conditions of the age group and the other variables’ conditions, so they should be taken carefully. It is not so central, but also worth mentioning that establishers or initials―never both of them but always one―, are often among the most and longest visited frames, so it seems that people need to figure out the beginning of each story along with the release of them. These findings agree with some authors’ point of view (e.g., Gernsbacher, 1996; Gernsbacher, Varner, & Faust, 1990). Gernsbacher (1996) postulated a theory about comprehension to build cohesive mental representations called the Structure Building Framework. According to this theory, the first step to construct comprehension of units larger than a word or image is laying a foundation. To do this, readers and viewers spend more time reading the first words of clauses, sentences, or paragraphs or viewing the first images of comic strips or picture stories (Gernsbacher, 1996). Thus, children and adults of this experiment could be setting this foundation of the representation in memory by spending more time and number of fixations on the establishers or the initials. This is also coherent with the “advantage of first mention” idea (Carreiras, Gernsbacher, & Villa, 1995), where the first mentioned participant is accessed first, regardless of its semantic role or syntactic position. Moreover, Gernsbacher (1996) also defends that this effect does not happen when the coherence of the story is called into question. Yet in this study, despite not being echoed in the Results section not to make them too long, no increment in the number or length of the fixations was found in establishers and initials when the coherence was manipulated, so this importance of first ideas seems to be a relatively stable effect. These patterns of eye movements could set a baseline where the release of the story seems to lead to some wrap-up processes, giving the conclusion―and “releasing” the tension―to the rest of the story, like they release the tension in Cohn’s (2013b) comics, as the author finds out. In van den Broek et al. (1996), they found for films that for adults the forward connections an event has have a stronger impact on the recall of events than backward connections. This means that the connections of an event with its consequences influence memory more than the connections with its antecedents; same happens for written narratives (van den Broek & Lorch, 1993). This could be in line with the findings about the release of the story as a conclusive process, where participants try to give a global sense to the whole story. Still, going one step further, an important finding in this study is that the processing of the peak and release, respectively, does not occur in isolation but, in fact, the processing of the one is influenced by the processing of the other. Therefore, conclusions about these components should take into account that they are mutually dependent and they interact. This statement will be detailed in further paragraphs. Concerning the “complete version” analysis, there were also some interesting findings. With regard to fixations (duration and frequency), it was found that the coherent/incoherent paradigm has an effect over the eye movement patterns of people. All incoherent versions increase their number and duration of fixations for their incoherent frames (peak or release), as expected from the beginning so, to address the third research question, incoherent frames seem to be more complex than coherent frames. Besides, what we find more surprising about this new outcome is the effect of the incoherent frames over the processing of other parts or frames of the stories. Some coherent frames in their incoherent versions of the story decrease in number and duration of fixations, what leads to answer the fourth research question, as the incoherence interacts with the coherent frames in such a way. Thus, incoherence draws reader’s attention, indeed, as it would be expected; nevertheless, it also takes attention out of the other frames in the incoherent peak version. It is also worth mentioning that, for incoherent release, the effect is not significant, although it follows the same direction. Therefore, it may be thought that this could be an effect of the sample size and maybe with a larger sample this effect could be significant. However, it could also simply be as it is: the effect appears for the incoherent peak version and not for the incoherent release version, but there is not enough data to answer these questions, so they will be addressed in further research. As far as data show, then, people’s eye movements patterns tend to focus on semantically incoherent parts of the comic strips, captivating their eyes more and longer than to other coherent parts of the scenes. Thus, as previous authors pointed out (Becker, Pashler, & Lubin, 2007; Clifton, Staub, & Rayner, 2007; Harris, Nefs, & Grafton, 2008; Rayner, 2009; Staub & Rayner, 2007), semantical incongruence attracts viewers’ attention. Implausible events yield longer times (Joseph et al., 2008; Rayner et al., 2004), as it happens in this study, even if the context is a fantasy-like context (Warren, McConnell, & Rayner, 2008). Besides, ambiguous information gets longer fixations (Altmann, Garnham, & Dennis, 1992; Rayner & Sereno, 1994). Even more, some studies about errors and motivation (Cimpian, 2010; Zentall & Morris, 2012) show that the threat of making mistakes raise the number of fixations people make. Maybe this could be an explanation of the high number of fixations on the incoherent information, as people want to be sure about what they are viewing, not to make any mistakes when asked. Completing the discussion about the study, results from regressions will be now approached. As can be seen from data, peak always receives more regressions than release. This may be because release is the last picture, so participants do not have to leave it to finish viewing, as it happens with peak. Furthermore, despite all the changes that will be next mentioned, regressions’ patterns seem to be relatively stable, as Rayner (2009) and other authors previously mentioned, as they seem to keep this general pattern regardless of these small differences we mention. However, what happens when we change the coherence of the story structure? Are regressions also sensitive to these changes, as it happens with fixations? Results seem to show that, indeed, incoherence takes attention, again, out of the other frames for the incoherent peak condition. However, this does not happen for incoherent release condition, but the effect, once more, follows the same direction. Incoherent peak/release do not receive more regressions than their coherent versions, though they receive more than coherent peak/release from the opposite incoherent conditions; consequently, changing the coherence of both makes the other receive fewer regressions than usual, again. Besides, it is also important to mention that when the peak is incoherent, the release receives fewer regressions than the other two releases. Therefore, the incoherence of both pictures disturbs the reading patterns, so both affect comprehension, as ambiguous information constrain people to make more regressions, like in previous theory (Altmann et al., 1992; Rayner & Sereno, 1994). Thus, for “regressions in”, there might be an interaction of both incoherent conditions, but only when something more is incoherent. However, there is a new discovery, not so central, but also interesting: only incoherence of peak affected release in such a way that eye movement patterns are even below its “usual” “coherent” condition; therefore, peak may be moderating the eye movements patterns on the release in a different way that vice versa. This experiment was started trying to understand reading patterns and see if they differ between children and adults while reading comics, following a coherent/incoherent paradigm. Our objective was to find eye-tracking patterns that were accurate, reliable, and related to reading comprehension and higher order cognitive processes. Some of the outcomes we reached with this experiment show surprising conclusions and we have found significant results supporting this general idea of eye movements as a measure that is sensitive to narrative coherence and to different maturity levels. Thus, eye movements develop and change while people grow up, and respond to some high level cognitive strategies, reflecting different processes of deep comprehension. However, this is a new path that researchers have not come to explore deeply. There is not much information about it, yet we hope to have paved the way or, at least, shed a bit more light on reading comprehension and eye movements’ research. Cite this article as: Martín-Arnal, L. A., León, J. A., van den Broek, P., & Olmos, R. (2019). Understanding comics. A comparison between children and adults through a coherence/incoherence paradigm in an eye-tracking study. Psicología Educativa, 25, 127-137. https://doi.org/10.5093/psed2019a7 Funding: This study was supported by Grant PSI2013-47219-P from the Ministry of Economic and Competitivity (MINECO) of Spain, and European Union. References |
Cite this article as: MartĂn-Arnal, L. A. , LeĂłn, J. A. , Broek, P. V. D. , & Olmos, R. (2019). Understanding Comics. A Comparison between Children and Adults through a Coherence/Incoherence Paradigm in an Eye-tracking Study. PsicologĂa Educativa, 25, 127 - 137. https://doi.org/10.5093/psed2019a7
Correspondence: lorena.martin@uam.es; loreleimajere@gmail.com (L. A. MartĂn-Arnal).Copyright © 2026. Colegio Oficial de la Psicología de Madrid






 PDF
PDF e-PUB
e-PUB CrossRef
CrossRef JATS
JATS Imprimir
Imprimir Enviar
Enviar
ALERTA POR E-MAIL
La Revista de Psicología Educativa está distribuida bajo una licencia de Creative Commons Reconocimiento-NoComercial-SinObra Derivada 4.0 Internacional.com








