


Differential Length and Overlap with the Stem in Multiple-Choice Item Options: A Pilot Experiment
[La longitud diferencial y el solapamiento con el enunciado en las opciones de ítems de opción múltiple: un experimento piloto]
Giulia Casua and Carmen García-Garcíab
aUniversity of Bologna, Italy; bAutonoma University of Madrid, Spain
https://doi.org/10.5093/psed2018a20
Recibido a 21 de Julio de 2018, Aceptado a 22 de Octubre de 2018
Resumen
Los ítems de opción múltiple son ampliamente utilizados en contextos de evaluación muy variados. Un requisito muy importante para garantizar su validez es su correcta redacción, y para ayudar a conseguirlo se han desarrollado una serie de directrices. El objetivo de este estudio piloto experimental fue investigar el efecto del incumplimiento de dos de estas reglas, más concretamente, la longitud diferencial de la opción correcta comparada con los distractores y su solapamiento léxico con el enunciado. Para ello, se asignó aleatoriamente a 55 estudiantes a las condiciones de responder a ítems que respetaban o que incumplían las mencionadas directrices y se compararon las propiedades psicométricas conseguidas por los ítems. Los resultados indican que, en general, los ítems con incumplimientos tendían a ser más fáciles y a recibir menos respuestas aleatorias; no obstante, había pocas diferencias significativas y el tamaño del efecto era medio. Aunque de interés, estos resultados deben ser interpretados con cautela debido al escaso tamaño muestral. Se comentan las implicaciones para futuras investigaciones.
Abstract
Multiple-choice items are extensively used across different assessment contexts. A crucial ment for ensuring their validity is their correct development, and a number of item-writing guidelines have been proposed that support item developers. This experimental pilot study aimed to investigate the effect of violating two item-writing guidelines: the differential length of the correct option compared to distractors and its lexical overlap with the stem. Standard and flawed items, respectively adhering to and deviating from guidelines, were randomly assigned to 55 college students and compared in their psychometric ing. Results indicated that, in general, flawed items tended to be easier and less subject to random answers than standard ones, but significant differences were few. Discrepancies between standard
and flawed subtests approached statistical significance with medium effect sizes. Although of interest, findings must be cautiously interpreted due to the small sample size. Implications for future research are discussed.
Palabras clave
Directrices sobre redacción de ítems, Ítems de elección múltiple, Items con incumplimientos, Longitud de las opciones, Solapamiento léxico, Dificultad de los ítems.
Keywords
Item-writing guidelines, Multiple-choice items, Flawed items, Length of options, Lexical overlap, Item difficulty.
Cite this article as: Casu, G. & García-García, C. (2018). Differential length & overlap with the stem in multiple-choice item options: A pilot experiment. Revista Psicología Educativa, 25, 43-48. https://doi.org/10.5093/psed2018a20
Correspondence: giulia.casu3@unibo.it (G. Casu).
Introduction The wide use of multiple-choice (MC) items across different evaluation contexts highlights the importance of their correct development and usage. With the objective of enhancing the validity of scores obtained from MC items, fundamental guidelines for MC item construction have been developed by different authors. Haladyna and Downing (1989a) settled the basis for MC item-writing by analyzing 46 textbooks and other sources, and proposed 43 consensual guidelines. The same authors also reviewed more than 90 studies to explore the validity of their recommendations and found that more than half of the guidelines had not been investigated at all (Haladyna & Downing, 1989b). In a replication of the latter review, Haladyna, Downing, and Rodriguez (2002) validated and reduced the original taxonomy of 43 item-writing rules to 31 guidelines, which have recently been reorganized and updated (Haladyna & Rodriguez, 2013). Other taxonomies for developing MC items were developed by Frey, Petersen, Edwards, Teramoto Pedrotti, and Peyton (2005) and Moreno, Martínez, and Muñiz (2006), which basically comprised the same advice as Haladyna et al.’s (2002). The latest pieces of advice for developing MC items were proposed by Moreno, Martínez, and Muñiz (2015), who drew up previous guidelines based on validity criteria, resulting in 9 general guidelines that summarize and subsume the previous ones by the same authors (Moreno et al., 2006) and by Haladyna et al. (2002). Despite the availability of multiple guidelines, flawed MC items are commonly applied. For instance, MC items are frequently used that contain either no correct option or more than one correct option, excessive text in the stem, “all of the above” and “none of the above” options, distractors that appear poorly plausible or contain clues to the correct answer (Rodriguez, 1997). Violations of basic MC item-writing principles are also common in college entrance tests and exams (e.g., Atalmis, 2016; García, Ponsoda, & Sierra, 2011; Hijji, 2017). The importance of following the standard MC item-writing principles lies in that the usage of flawed MC questions negatively affects both tests and students (Haladyna & Rodriguez, 2013; Omer, Abdulrahim, & Albalawi, 2016; Pate & Caldwell, 2014), and introduces construct irrelevant variance (CIV) in the evaluation process (Downing, 2002, 2005). Indeed, CIV harms the evidence of validity of the assessment by interfering with the meaningful and exact interpretation of scores and negatively affecting the pass rate on the exam (Downing, 2002; Haladyna & Downing, 2004). Authors agree that the standard MC item-writing guidelines have been built on consensus among item-writing experts rather than on the results of empirical studies. Thus, there is a need for further studies that finally validate or refute the proposed MC item-writing guidelines, and examine their impact on different psychometric indices (e.g., Haladyna & Downing, 1989a; Haladyna et al., 2002; Moreno et al., 2015). Specifically, Downing (2002) underlined the need for experimental studies in which standard and flawed (i.e., manipulated) items designed for assessing performance on a single domain are randomly assigned to examinees. However, to the authors’ knowledge, research of this kind is still extremely rare (e.g., Caldwell & Pate, 2013). Objective and Hypotheses Following the claim by Downing (2002), this pilot study aimed to investigate whether the violation of two different guidelines for writing the options affected the psychometric functioning of MC items. The following MC item-writing guidelines by Haladyna and Rodriguez (2013) were considered: “Keep the length of options about equal” (guideline 20a) and “Avoid clang associations, options identical to or resembling words in the stem” (guideline 20c). As to guideline 20a, all item-writing authors agree in that item options must be homogeneous in length (Albano & Rodriguez, 2018; Gierl, Bulut, Guo, & Zhang, 2017). However, a common mistake is that the correct option is longer than distractors (Omer et al., 2016; Rodriguez, 1997). Reviewing the MC item tests developed by college teachers in four different countries, Carter (1986) found that at least one item had a longer correct option in 86% of tests. Results of nonexperimental studies on the effects of violating this guideline are nonetheless still inconclusive. In investigating the possibility of predicting the difficulty of the Test of English as a Foreign Language (TOEFL), Freedle and Kostin (1993) found that the length of the incorrect options was negatively related to the difficulty index (i.e., proportion of subjects correctly answering an item), suggesting a detrimental effect of a greater number of words in the distractors. Similarly, a meta-analitic study by Rodriguez (1997) found that a longer correct option made items easier. Nevertheless, more recently, Martínez, Moreno, Martín, and Trigo (2009) found no difference in difficulty between standard items and items with differential length of one option compared to the rest, or between items with differential length in correct vs. incorrect options. As to guideline 20c, previous observational studies analyzing the difficulty of TOEFL listening and reading comprehension items agree in that the lexical overlap with the stimulus or key text sentence makes the item easier when it occurs in the correct option, but makes the item more difficult when it occurs in a distractor (Freedle & Fellbaum, 1987; Freedle & Kostin, 1993, 1996; Ying-Hui, 2006). These guidelines were selected for the present study as they have been mentioned among the most effective ones in providing cues to examinees (Morse, 1998). As suggested by Moreno et al. (2015), the extra attention paid on an option that stands out from the others for its length or wording might overlap with the response a person would give had such difference not existed. Moreover, compared to other item-writing rules, these are more suitable to an objective operationalization. The distinctness of an option relative to the others because of its length or overlap with elements in the stem can indeed be easily expressed in terms of number of words. Specifically, we explored whether a correct option that was either longer (guideline 20a) or more highly overlapped with the stem (guideline 20c), compared to distractors, affected item difficulty, defined as the proportion of examinees correctly answering an item, and proportion of random answers reported by examinees. Reported random answers were used as an index of perceived item difficulty. Assuming that random answers are given when a task is perceived to be difficult, perceived item difficulty was expected to be negatively, at least moderately associated with actual item difficulty (Bratfisch, Dorni, & Borg, 1972; Hambleton & Jirka, 2006; Wolf, Smith, & Birbaum, 1995). Based on the above, the following experimental hypotheses were formulated. For guideline 20a, we hypothesized that: (1) items would be actually easier (i.e., have higher difficulty indices) when the correct option was longer than the distractors than when all options had approximately the same length; (2) items would be perceived as easier (i.e., the percentage of random answers reported by examinees would be lower) when the correct option was longer than the distractors than when all options had approximately the same length; and (3) items would be actually easier and perceived as easier (i.e., have higher difficulty indices and a lower percentage of random answers reported by examinees) as the visibility of the differential length (defined as a higher difference in the number of characters between the correct option and the longest distractor) increased. For guideline 20c, we hylothesized that: (1) items would be actually easier when the lexical overlap with the stem was higher in the correct option than when all options were approximately equally overlapped with the stem; (2) items would be perceived as easier when the lexical overlap with the stem was higher in the correct option than when all options were approximately equally overlapped with the stem; and (3) items would be actually easier and perceived as easier as the visibility of the lexical overlap between the correct option and the stem (defined as a higher difference in the number of words lexically overlapped with the stem between the correct option and the most overlapped distractor) increased. MethodParticipants Fifty-five (65.5% females) Psychology students with a mean age of 23.7 years (SD = 6.8, range 19-52 years) participated in the study by completing one of four forms of a college MC test in basic Psychometrics. Forms A and B were completed by 15 (27.3%) and 14 (25.5%) examinees, respectively, whereas both Forms C and D were responded by 13 (23.6%) students. Instruments The questionnaire was composed by 18 MC items developed by methodology experts to assess student performance in basic Psychometrics. Each item consisted of a question- or sentence-completion stem, followed by 3 vertically formatted options, only one of which was correct. Two versions of the questionnaire were designed. In the standard version, all items adhered to MC item-writing guidelines and showed adequate psychometric functioning as indicated by previous applications to large samples. In the flawed, manipulated version, half items contained violations of guideline 20a and the other half of guideline 20c. Violation of guideline 20a was defined as a surplus of 5 or more uninformative words (i.e., words with no information content, such as conjunctions, prepositions, pronouns, etc.) in the correct option compared to the longest distractor and was introduced in item # 1 to # 9. Violation of guideline 20c was defined as a surplus of 2 or more words lexically overlapped with the stem in the correct option compared to the most overlapped distractor and was introduced in items # 10 to # 18. Two independent methodology experts modified the standard items to introduce the guideline violation and ensured that each manipulated item included violation of one item-writing guideline only. Design and Procedure Four 18-item test forms were created to balance the levels (i.e., standard vs. flawed) of the independent variables (i.e., guideline 20a vs. guideline 20c) and control for order of presentation. Four items with violations of guideline 20a (items # 2, 3, 5, and 8) and four items with violations of guideline 20c (items # 11, 13, 16, and 17) were randomly assigned to Form A; the remaining manipulated items (items # 1, 4, 6, 7, and 9 for guideline 20a, and items # 10, 12, 14, 15, and 18 for guideline 20c) were assigned to Form B (Table 1). Form C and Form D contained the same items as Form A and Form B, respectively, but the order of presentation of the two halves of the questionnaire was reversed. Table 1 Experimental Design  Note. Flawed items included in each subtest are shown. Subtests were composed by standard or flawed items, depending on the test form received. For example, as to guideline 20a, subtest 1 was formed by items # 2, 3, 5, and 8, that were flawed in forms A and C and standard in forms B and D; subtest 2 was composed by items # 1, 4, 6, 7, and 9 that were flawed in forms B and D and standard in forms A and C. For guideline 20c, subtest 3 included items # 11, 13, 16, and 17 that were flawed in forms A an C and standard in form B and D; finally, subtest 4 comprised items # 10, 12, 14, 15, and 18 that were flawed in forms B and D and standard in form A and C. Test forms were randomly assigned to students, ensuring that an approximately equal number of examinees received each form. The questionnaire was applied to students during the last class of the Psychometrics course. Examinees were reassured that participation was voluntary and the questionnaire anonymous, and informed that the test score would neither be corrected for errors nor would in any way affect their Psychometrics course assessment mark. For each item, examinees were told that they could mark a cross in case of random answering or being insecure about the correct answer, as this would have helped the examiners to identify topics in need of reinforcement within the course program. MC item development was not a topic of the study program. Data Analysis To ensure the absence of order effects on examinees’ performance, one-way analysis of variance (ANOVA) was performed to compare test scores between test forms. Actual difficulty (i.e., proportion of correct answers) and perceived difficulty (i.e., percentage of random answers reported by examinees) were computed for each item, and their relationship was examined using bivariate correlations. The standard and flawed versions of each item were compared in their actual and perceived difficulty by performing a z-test. For each subject, the proportion of correct answers and reported random answers in four different subtests was calculated. Mean proportion of correct answers and mean percentage of reported random answers in each subtest were compared between the two experimental conditions (i.e., standard vs. flawed) using ANOVA. Finally, linear regression analyses were performed to investigate the influence of the visibility of the guideline violation on actual and perceived difficulty. For guideline 20a, the visibility of the violation was measured as the difference in the number of characters between the correct option and the longest distractor. For guideline 20c, the visibility of the violation was calculated as the difference in the number of words lexically overlapped with the stem between the correct option and the most overlapped distractor. A power analysis indicated that, with α = .05 (two-tailed), at least 52 cases were needed to reach enough power (.80) to detect a large effect size. Evaluation of estimates was based on both statistical significance (significance level set at p ≤ .05) and effect-size measures, Cohen’s d of 0.20 being considered small, 0.50 medium, and 0.80 large, and R2 and η2 of .01 being considered small, .09 medium, and .25 large (Cohen, 1988). Statistical analyses were performed with IBM SPSS 22 (SPSS Inc., Chicago, IL). Power analysis was performed with G*Power 3.1 (Faul, Erdfelder, Lang, & Buchner, 2007). ResultsOrder Effects No significant difference was found between test forms in total test scores, indicating the absence of order effects, F(3, 51) = 1.43, p = .25, η2 = .08 (Table 2). The higher mean score in Form B might be attributable to the lower mean percentage of reported random answers in items that make up this form (Table 3 and Table 4). Table 2 Mean Scores across Test Forms  Table 3 Item Descriptive Statistics by Experimental Condition for Guideline 20a 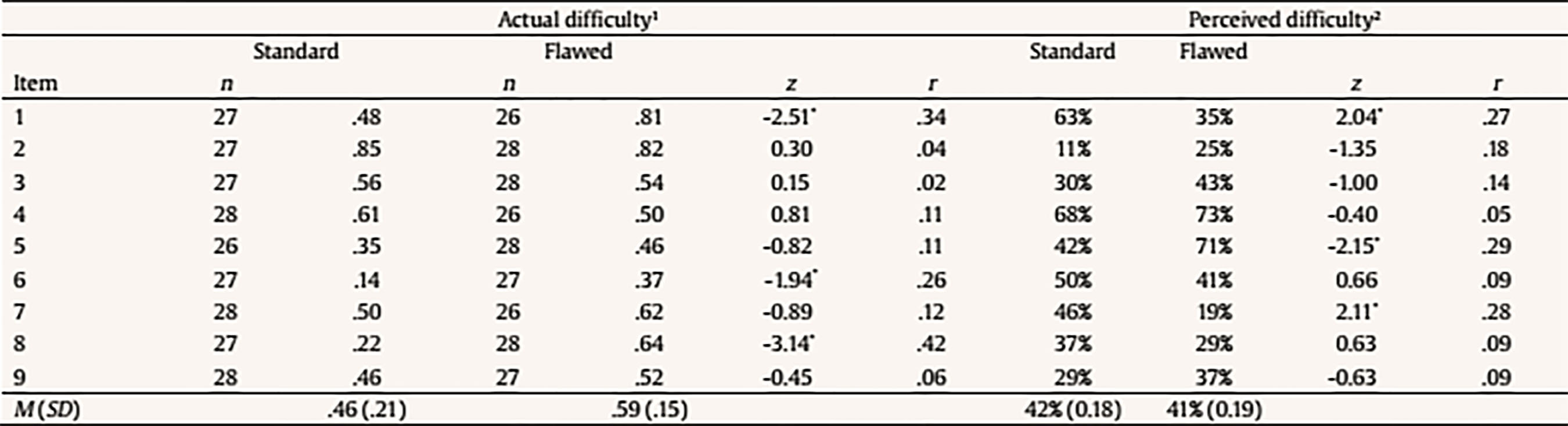 Note. 1Proportion of correct answers. 2Percentage of reported random answers. *p = .05. Table 4 Item Descriptive Statistics by Experimental Condition for Guideline 20c 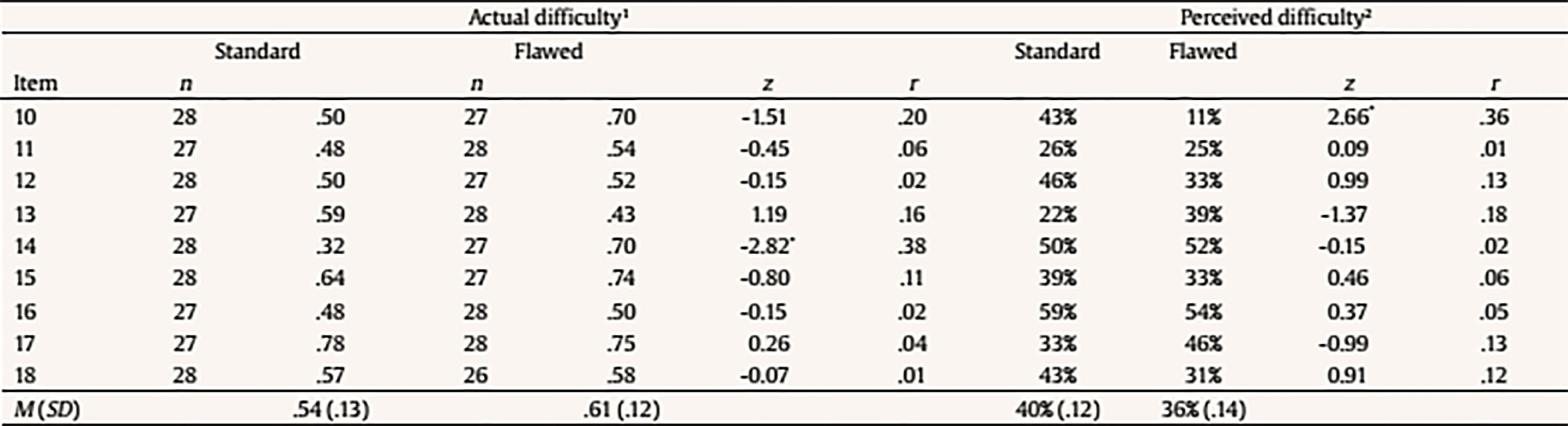 Note. 1Proportion of correct answers. 2Percentage of reported random answers. *p = .05. Guideline 20a Actual and perceived difficulty were moderately, although non-significantly, negatively correlated (r = -.41, p = .10). As shown in Table 3, the mean (actual) difficulty index was slightly higher for items with differential length of the correct option than for items with approximately same length options. As to individual items, six out of nine items were easier in their flawed version; however, the proportion of correct answers was significantly, moderately higher in the flawed than in the standard version for three items only. The mean proportion of random answers reported by examinees was almost equal between standard and flawed items. As to individual items, there was no clear pattern between item manipulation and perceived item difficulty. For both subtests 1 and 2, results of ANOVAs indicated that the difference in mean percentage of correct answers between the standard and flawed versions approached statistical significance (Table 5). In both cases, the flawed version tended to have a significantly higher percentage of correct answers, compared to the standard one, with a medium effect size. Table 5 Subtest Comparisons for Proportion of Correct Answers 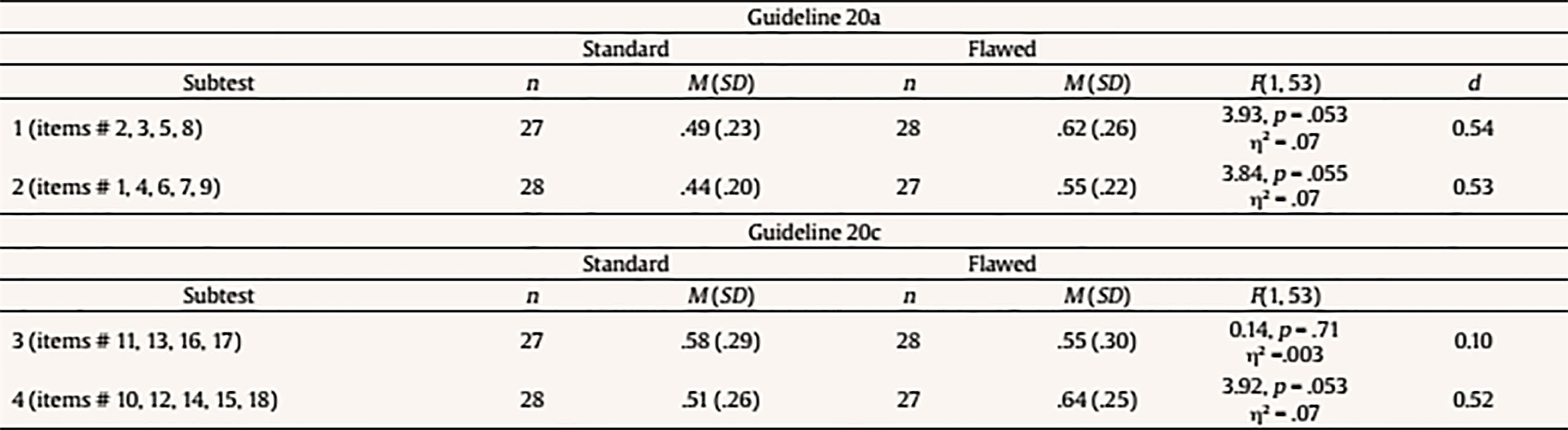 Finally, the visibility of the violation had no significant effects on actual difficulty, although the strength of the association was moderate, β = .33, R2 = .11, F(1, 16) = 1.89, p = .19, or on perceived difficulty, β = -.02, adjusted R2 = .00, F(1, 16) = .010, p = .93. Guideline 20c Actual and perceived difficulty were moderately, although non-significantly, negatively correlated (r = -.30, p = .23). Items in which the lexical overlap with the stem was higher in the correct option compared to distractors had a slightly higher mean (actual) difficulty index than standard items, in which all options were approximately equally overlapped with the stem (Table 4). As to individual items, seven out of nine items were easier in their flawed version; nevertheless, differences in item difficulty were negligible, and reached statistical significance in one item only, with a medium effect size. The mean proportion of reported random answers was slightly higher in standard items. Nevertheless, there was no clear relation between item manipulation and perceived item difficulty. For subtest 4, results of ANOVAs indicated that the flawed version tended to have a significantly higher percentage of correct answers, compared to the standard one, with this difference approaching statistical significance and being moderate in magnitude (Table 5). No significant effect of guideline manipulation was instead found for subtest 3. Finally, the visibility of the violation had no significant effects on actual difficulty, although the association was moderate in strength, β = .41, R2 = .17, F(1, 16) = 3.16, p = .09. Instead, a higher difference in the number of words lexically overlapped with the stem between the correct option and the most overlapped distractor was associated with a significantly lower perceived difficulty, with a large effect size, β = -.50, R2 = .25, F(1, 16) = 5.19, p = .04. DiscussionThis pilot study aimed to investigate whether the violation of two guidelines by Haladyna and Rodriguez (2013) for writing MC item options affected item psychometric characteristics. Actual difficulty (i.e., proportion of examinees correctly answering the item) and perceived difficulty (defined as the percentage of reported random answers) of a set of standard items (i.e., with no violations of any item-writing guideline) were compared to those of a flawed version of the same items (i.e., with violation of one of the two guidelines). The following guidelines were considered: “Keep the length of options about equal” (guideline 20a), and “Avoid clang associations, options identical to or resembling words in the stem” (guideline 20c). For guideline 20a, flawed items had differential length of the correct option, defined as a surplus of 5 or more words relative to the longest distractor. As to guideline 20c, lexical overlap between the correct option and the item stem was introduced in flawed items, and defined as a surplus of 2 or more words lexically overlapped with the stem compared to the most overlapped distractor. Results indicated that, for guideline 20a, the proportion of correct answers was in general higher for flawed than for standard items. However, this difference was statistically significant for three out of nine items only, with medium effect sizes. When considering comparable subtests, the proportion of correct answers was higher in subtests with differential length of the correct option, with these differences approaching statistical significance and being moderate in magnitude. Thus, altogether, flawed items tended to be easier than standard ones, as hypothesized. It must be nonetheless acknowledged that the differences in actual difficulty between standard and flawed items were not systematic. This partly contradicts meta-analytic findings by Rodriguez (1997), who concluded that a higher length of the correct option relative to distractors makes items easier, but is in line with more recent findings by Martinez et al. (2009), who found no differences between standard and flawed items. However, it must be noted that Martinez et al. (2009) included in their analyses also distractors with differential length compared to the rest of options. Most of all, these studies did not consider standard and flawed versions of a same item, which makes comparisons with previous evidence difficult to carry out. With respect to guideline 20c, the mean proportion of correct answers was slightly higher for flawed items compared to standard ones, suggesting that flawed items tended to be easier. Nevertheless, differences in actual item difficulty between standard and flawed items were minor, and reached the statistical significance in one out of nine items only, with a medium effect size. In addition, for this guideline one subtest only showed an almost significantly higher proportion of correct answers in its flawed version than in its standard version. Thus, we found no strong evidence in support of initial hypotheses that items containing lexical overlap between the correct option and the stem would be easier than the corresponding standard items. This contradicts previous findings that the lexical overlap with the stem makes the item easier when it is in the correct option (Freedle & Fellbaum, 1987; Freedle & Kostin, 1993, 1996; Ying-Hui, 2006). Again, it must be nonetheless noted that these studies did not have an experimental design, which makes comparisons with our findings problematic. With respect to perceived item difficulty, for both guidelines this index was negatively, moderately correlated with actual item difficulty, as expected. However, the mean proportion of random answers reported by examinees was almost equal between standard and flawed items for guideline 20a, while it was slightly lower for flawed items in case of violation of guideline 20c. In general, no clear pattern between item manipulation and perceived item difficulty could be observed for either of the two guidelines, which does not support initial hypotheses. Finally, we xamined whether the visibility of the guideline violation was associated with item psychometric characteristics. For guideline 20a, the visibility of the differential length of the correct option compared to distractors was unrelated to actual and perceived item difficulty, in contrast with hypotheses. For guideline 20c, a greater visibility of the lexical overlap between the correct option and the item stem was associated with a lower percentage of random answers reported by examinees. This was partly in line with hypotheses and in line with findings that the visibility of guideline 20c violation was a significant predictor of a lower item difficulty (Freedle & Kostin, 1993, 1996; Ying-Hui, 2006). To our knowledge, this pilot study was one of the first to use an experimental design to test the validity of MC item-writing guidelines. Altogether, findings suggest a tendency for MC items violating guidelines 20a and 20c to be easier and less subject to random answers than items with no violation of any guideline. Nevertheless, it must be noted that significant individual differences between standard and flawed items were only few in number, and discrepancies between flawed and standard subtests only approached statistical significance. This might be attributable to the small sample size, which limited statistical power (post-hoc achieved power was .44 in the present study), as the estimated effect sizes were medium according to Cohen’s criteria (Cohen, 1988). On the other hand, the true difference in psychometric functioning between standard and flawed items might be a null one, which needs to be addressed in future studies using larger samples. The limited sample size also precluded a comparison of standard and flawed items in their ability to discriminate between higher- and low-performing students, as each test form was completed by too few examinees. In addition to the small sample size, other limitations of this pilot study include that our findings refer to the performance of college students in a very specific domain. Moreover, examinees were informed that test score would not influence their final mark, which may have affected their motivation and performance, with potential consequences on results. In conclusion, although of interest, results of the present pilot study must be cautiously interpreted. Further studies on larger samples are required to definitely assess whether the violation of the examined guidelines is associated with lower item difficulty and less random answers, and to explore the effects of these violations on item discrimination. Future research should also investigate how the application of flawed items contributes to variance irrelevant to the construct being measured. Indeed, test-wiseness is an individual’s ability to take advantage of test characteristics and format that is unrelated to his/her knowledge or ability level; thus, examinees’ experience with MC items or their differential skill in taking tests might represent important sources of variance in test scores (Milman, Bishop, & Ebel, 1965; Papenberg, Willing, & Musch, 2017; Thorndike, 1951). Another factor potentially affecting MC test performance is an examinee’s cognitive style, especially in case of flawed MC items (Armstrong, 1993). Studies specifically designed to examine the effect of the above mentioned variables are therefore encouraged to increase our understanding of how examinees interface with flawed items. Cite this article as: Casu, G. & García-García, C. (2018). Differential length and overlap with the stem in multiple-choice item options: A pilot experiment. Psicología Educativa, 25, 43-48. https://doi.org/10.5093/psed2018a20 References |
Cite this article as: Casu, G. & García-García, C. (2018). Differential length & overlap with the stem in multiple-choice item options: A pilot experiment. Revista Psicología Educativa, 25, 43-48. https://doi.org/10.5093/psed2018a20
Correspondence: giulia.casu3@unibo.it (G. Casu).
Copyright © 2026. Colegio Oficial de la Psicología de Madrid






 PDF
PDF e-PUB
e-PUB CrossRef
CrossRef JATS
JATS Imprimir
Imprimir Enviar
Enviar
ALERTA POR E-MAIL
La Revista de Psicología Educativa está distribuida bajo una licencia de Creative Commons Reconocimiento-NoComercial-SinObra Derivada 4.0 Internacional.com








