


Developing Biodata for Public Manager Selection Purposes: A Comparison between Fuzzy Logic and Traditional Methods
[El desarrollo de biodata para la selección de personal en puestos directivos de la Administración Pública: una comparación entre la lógica difusa y los métodos tradicionales]
Antonio L. García-Izquierdo1, Pedro J. Ramos-Villagrasa2, and María A. Lubiano1
1Universidad de Oviedo, Spain; 2Universidad de Zaragoza, Spain
https://doi.org/10.5093/jwop2020a22
Received 13 March 2020, Accepted 7 October 2020
Abstract
Biodata have been widely used in personnel selection for a long time, mainly due to their predictive validity in different contexts, low faking, and positive applicant reactions. At the same time, some disadvantages need to be highlighted, with discriminatory content representing a major concern. In order to shed light on these issues, the objectives of the present research are twofold: firstly, we aim to develop biodata items for personnel selection for the provision of managerial positions in Public Administration and, secondly, we aim to test the fuzzy logic method as a valid approach for the development of biodata scales, with a view to choosing the best biodata items in terms of job performance, fairness, and privacy, according with manager and applicant perspectives. Participants assessed 26 items according to traditional and fuzzy rules, resulting in 8 highly effective items. Then, both approaches were compared: fuzzy logic turned out to have similar results as the traditional approach. Finnally, future developments in research an practical implications in the field are suggested.
Resumen
Los datos biográficos (biodata) se han utilizado en la selección de personal durante mucho tiempo debido, principalmente, a su buena validez predictiva en diferentes contextos, a su bajo falseamiento y a las reacciones positivas de los solicitantes de empleo. No obstante, podemos destacar el posible contenido discriminatorio como su principal desventaja. Por tanto, los objetivos de la presente investigación son, en primer lugar, desarrollar empíricamente ítems válidos y justos para la selección de puestos directivos en la Administración Pública y, en segundo lugar, comprobar la utilidad de la lógica difusa en el desarrollo de escalas con biodata para elegir los mejores ítems en términos de desempeño laboral, equidad y privacidad, de acuerdo con las perspectivas de directivos y de solicitantes de empleo. Los participantes en el estudio evaluaron 26 ítems según reglas tradicionales y difusas, y se obtuvieron 8 ítems altamente efectivos. Posteriormente se compararon ambos enfoques: aunque la lógica difusa demostró cierta eficacia, logró resultados similares a los del enfoque tradicional. Finalmente, se proponen futuros desarrollos de investigación e implicaciones prácticas en esta materia.
Palabras clave
BiodataBiodata, Justicia organizacional, SelecciĂłn de personal, LĂłgica difusa, Directivos pĂşblicos, ValidaciĂłnKeywords
Keywords, Fairness, Personnel selection, Fuzzy logic, Public managers, ValidationCite this article as: García-Izquierdo, A. L., Ramos-Villagrasa, P. J., & Lubiano, M. A. (2020). Developing Biodata for Public Manager Selection Purposes: A Comparison between Fuzzy Logic and Traditional Methods. Journal of Work and Organizational Psychology, 36(3), 231 - 242. https://doi.org/10.5093/jwop2020a22
Public administrations must update by addressing human resources challenges in order to guarantee citizens an efficient service through the provision of high performance standards. This modernization requires an organizational transformation in which managers play a key role when implementing policies and decision making procedures (Castaño & García-Izquierdo, 2019), especially at a time when personnel trends are assuming greater importance as a result of open government and social responsibility movements that are having a major impact on management practices. Personnel selection methods in Spain are mainly traditional (e.g., Alonso et al., 2015), so they are more oriented to merit and knowledge than abilities or skills. While some biodata are used in Spanish public administration, mainly as merit ratings (Alonso et al. 2009), little is known about their use in terms of validity, transparency, and fairness. One of the reasons for the scarcity of information about biodata content is the lack of access to the items that have been used (Breaugh, 2009), an aspect that limits the impact of measurement evidences. Although we have access to information about questionnaires as a whole, the lack of specific information with regard to each individual item makes it difficult to choose biodata items that demonstrate sufficient validity, practicality, and legality. Biodata, defined as information about workers’ previous experiences, behaviours, and feelings in specific situations (Stokes, 1999) have been used in personnel selection for over one hundred years (Becton et al. 2009; Dean, 2013; Speer et al. 2020). Biodata information contributes to the selection process by screening out applicants in terms of fit to organizational demands and job description and specification. The use of biodata is also an attractive option in personnel selection because it combines acceptable validity with an inexpensive method of data gathering (West & Karas, 1999). Biodata are also easy to collect through application forms or résumés (Furnham, 2017), and it seems that applicants are not prone to fake their responses (e.g., Hough et al., 1990) when are asked to elaborate on them (Schmitt et al., 2003) and when such information can be verified (Harold et al., 2006). In addition, given the globalized use and dissemination of recruitment and selection social networks, such as LinkedIn (e.g., Aguado et al., 2019), there is an increasing need to conceptualize strong biodata that provides a basis for enhancing and facilitating personnel decision-making. In the present study, we aim to empirically develop biodata for personnel selection for managerial positions in public administration, taking into account existing Spanish legislation regarding equal employment opportunities. Consequently, we aim to develop useful biodata for the public sector, in terms of efficacy, transparency, and legality as, according to Breaugh (2009), biodata scales for personnel selection should be composed of items that are simultaneously valid, fair, and ensure privacy. Developing adequate biodata that complies with these requirements is a challenge for the research. In addition, as Ryan and Derous (2019) have pointed out, the use of technology can help us to improve personnel selection. In this case, we intend to study whether the use of fuzzy logic can help to choose the best biodata according to manager and applicant perspectives. Biodata Biodata theoretical background assumes behavioural consistency, i.e., the best predictor of future performance is past performance (Wernimont & Campbell, 1968). This implies that information about an applicant’s previous behaviour permits us to predict their future at the workplace. However, as Furnham (2008) has shown, practitioners avoid its systematic usage in personnel selection because of its perceived lack of validity, practicality, and legality. We will now describe how each of these concerns can be dealt with. Several studies have analyzed the validity of biodata with regards to job performance, reporting coefficients ranging from .20 to 50 (Harold et al., 2006). For example, Reilly and Chao (1982) have shown values of .40 (n = 2,504) and .23 (n = 320) for ratings and salary, respectively, in management positions. A meta-analysis by Bliesener (1996), based on 116 studies and 165 independent samples (N = 106,302), reported a true validity of .22, after making corrections for all analyzed artifacts. Previously, Hunter and Hunter (1984), using validity generalization, reported values from .26 (tenure) to .37 (supervisor ratings). Regarding the validity of biodata, Salgado et al. (2002) concluded that “biodata are one of the most valid predictors of personnel selection, and that their validity can generalize across organizations, occupations, and samples” (p. 182), after reporting true validity values between .46 (training) and .48 (job performance). However, the problem is more related with content validity: we know that biodata predicts job performance, but not really why. In addition, there is a lack of consensus about what constitutes biodata (Breaugh, 2009), ranging from verifiable biographical information to wider definitions including other aspects such as values, preferences, or skills. Wider definitions of biodata can overlap with other constructs like personality and/or abilities (Furnham, 2017). Cole et al. (2003) found that certain biodata related with academic achievement, work experience, and social activities are able to predict cognitive ability and personality. However, Mount et al. (2000) found that biodata based on job analysis increases the explained variance over cognitive ability (Rothstein et al., 2004). Although still open to debate, the evidence that biodata present enough validity as the best personality scales (Furnham, 2017) would appear to justify their use in personnel selection processes. Regarding the practicality of biodata, there are two main aspects involved during personnel selection processes: time demands and biodata scoring (Breaugh, 2009). Time demands depend mainly on the length of scales. Although many biodata scales are comprised of a large amount of items, research shows that shorter scales are also able to successfully predict job performance (e.g., Barrick & Zimmerman, 2005; O’Connell et al. 2002). Biodata scoring is another subject for debate among researchers, with three different coexisting approaches (Cucina et al, 2012), depending on its content development, namely, empirical, rational, and quasi-rational. The empirical approach matches the answer to each biodata with specific criteria, with the strength of this relationship being the mean of its weight. The main disadvantage of this scoring is that it is not based on any theoretical model, and therefore contributes to the problem of validity of biodata content. The rational approach implies assigning an a priori value after an examination of literature review or by subject matter experts. This approach offers some advantages, as its appropriateness in terms of legal basis permits a better construct comprehension and it can be easily extended to other contexts (Stokes & Searcy, 1999). However, its disadvantage is that it requires a long and detailed job description and specification (Allworth & Hesketh, 1999). The last approach we wish to deal with is the quasi-rational approach, which can be performed in at least two ways; firstly, by following an empirical approach and reviewing weights and modifying or dropping them according with theory and, secondly, by performing a rational and empirical approach, combining both to create a hybrid weight. The quasi-rational approach has the advantages derived from both previous approaches, given that it has demonstrated its relationship with criteria, as in the empirical approach, and is easier to explain and defend among non-experts (Mael & Hirsch, 1993). Regardless of the method chosen, it is advisable to compute relationships between biodata and criteria (Cucina et al.2013), given that Mitchell and Klimoski (1982) have referred to the loss of predictability of biodata over time, due to time moment and context effects (Dean & Russell, 2005), and in response to changes in job skills requirements, criterion measurement, and organizational policies for personnel selection. The third concern about biodata is legality. There are important cross-country differences in personnel selection legislation and practices, but we can see a common interest in legal protection against discrimination (Myors et al., 2008). In this regard, the European Union has developed several directives to avoid gender discrimination at work, and Spanish legislation has also provided various legal dispositions (García-Izquierdo & García-Izquierdo, 2007). Of significant interest is the recent legal provision (Royal Decree-Law 6/2019), which states that organizational equality plans must detail personnel selection, classification, and promotion processes. The protection of a specific collective (focal group) is intended to guarantee that assessments in personnel selection contexts are not biased against such socially underrepresented groups. Although initial research on biodata reports low adverse impact (e.g., Mumford & Stokes, 1992; Reilly & Chao, 1982; Van Rijn, 1992), biodata requires further in-depth study for at least two reasons. Firstly, specific biodata items about gender, age, or country of origin are now considered inappropriate (García-Izquierdo et al., 2015), given that they can easily activate stereotypes in management decisions and may lead to job discrimination (Castaño et al., 2019). Secondly, some research has shown that biodata present differential functioning, depending on the gender (Imus et al., 2011) and ethnicity (Dean, 2013) of respondents, which means that precautionary measures must include careful examination of existing legislation in different countries, in order to ensure that only adequate items are considered. Despite these necessary precautions, recent empirical evidence supports the idea that biodata present low adverse impact (Bradburn & Schmitt, 2019; Breaugh et al., 2014; Prasad et al., 2017), and may even improve the results obtained by means of personality and cognitive tests (Barrick & Zimmerman, 2005; Becton et al., 2012; Oswald et al., 2004; Ployhart & Holtz, 2008). We can therefore conclude that biodata, when carefully developed according with the law and the research, can prevent bias and adverse impact. Another relevant issue of interest to consider when using biodata is applicant reactions: the “attitudes, affect, or cognitions an individual might have about the hiring process” (Ryan & Ployhart, 2000, p. 566). Such reactions are an important concern, since they may influence an applicant’s intentions to accept job offers and to recommend the employer to colleagues (Truxillo et al., 2015). According with the meta-analysis performed by Anderson et al. (2010) with 38 samples from 17 countries (N = 29,141), biodata were considered among the ‘favourably evaluated’ selection methods, along with résumés, cognitive tests, references, and personality inventories, and were only exceeded by interviews and work sample tests. A previous meta-analysis, on this occasion performed with 86 independent samples (N = 48,750) by Hausknecht et al. (2004), found that face validity and perceived predictive validity are the main determinants of applicant reactions. A closely related and relevant topic when considering applicant reactions is fairness. Lack of fairness deals with negative applicant reactions that lead to undesirable outcomes, such as the loss of future candidates, a lower disposition to accept a job offer, the expression of negative opinions about the company, and the increased likelihood of litigation against the organization (Salgado et al., 2017). Taken together, all the aforementioned information demonstrates that practitioner beliefs about the low appropriateness of biodata lack sufficient foundation. We can therefore state the following conclusions: firstly, while accepting concerns about biodata content validity, its predictive validity is a remarkable strength; secondly, biodata may predict performance, even with few items; and finally, biodata present low adverse impact and can be designed to take existing legislation into account. Consequently, the present research aims to identify biodata than can be used in personnel selection and, in this case, for the provision of managerial positions in public organizations. In addition, we wish to investigate the use and advantages that fuzzy logic can provide when selecting biodata, with a view to choosing the best biodata in terms of job performance, fairness, and privacy, according with manager and applicant perspectives. Fuzzy Logic and Fuzzy Rule-based Systems Fuzzy set theory and fuzzy logic tools are currently effective in formalizing uncertainty in different areas of management (Hryhoruk et al., 2017) and human resources procedures (Ahmed et al., 2013). Indeed, there has been a steady increase in the application of fuzzy models in the areas of personnel selection, classification, and decision making, from the pioneering studies at the end of the 20th century (e.g. Hesketh et al., 1988; Hesketh et al., 1995), owing to their practical usefulness in addressing a variety of organizational management problems. Notable examples include multi-objective optimization on the basis of ratio analysis (MOORA; e.g., Brauers & Zavadskas, 2012); the Technique for Order of Preference by Similarity to Ideal Solution (TOPSIS; e.g., Shaout & Yousif, 2014); Fuzzy Analytic Hierarchy Process (FAHP; e.g., Longo et al., 2019); fuzzy set Qualitative Analysis (fsQA; e.g., Guedes & Gonçalves, 2019; Henriques et al., 2018); and Mandani Fuzzy Inference System (MSFI; e.g., Dropuli Ruzic et al.,2016). We will return to this last approach later. But first it would be useful to broadly explain the characteristics and basic concepts of fuzzy logic and fuzzy sets. Fuzzy logic provides a natural way of dealing with problems where the source of imprecision is the absence of sharply defined criteria of class membership (Zadeh, 1965a), as is the case with social sciences, where relations between variables are fuzzy, and even the variables may be fuzzy (Goguen, 1967). In this regard, Walsh et al. (2014) outlined that fuzzy logic reflects how people actually think by assigning gradations of meaning, as is the case in psychological measurement. Fuzzy logic was developed by Zadeh (1965b) in order to operate with lack of accuracy, when this inaccuracy is neither a random nor stochastic variable, but a vaguely defined class. This means a class or classes that do not possess sharply defined boundaries. In contrast to conventional set theory, where an object is required to be either a member of a set or not a member of that set, fuzzy sets make it possible to treat fuzziness in a quantitative manner. According to Zadeh (1965a), a fuzzy set is a class of variables with a continuum grade of membership, and is defined by its membership function, which represents a grade of membership between zero and one. The nearer the value of the membership function to one, the higher the grade of membership in the fuzzy set (Kaufmann & Gupta, 1991). In Figure 1, we can see a graphical representation comparing the membership function of a fuzzy set and a real number. Figure 1 Membership Function of a Fuzzy Set (left) and a Real Number (right). 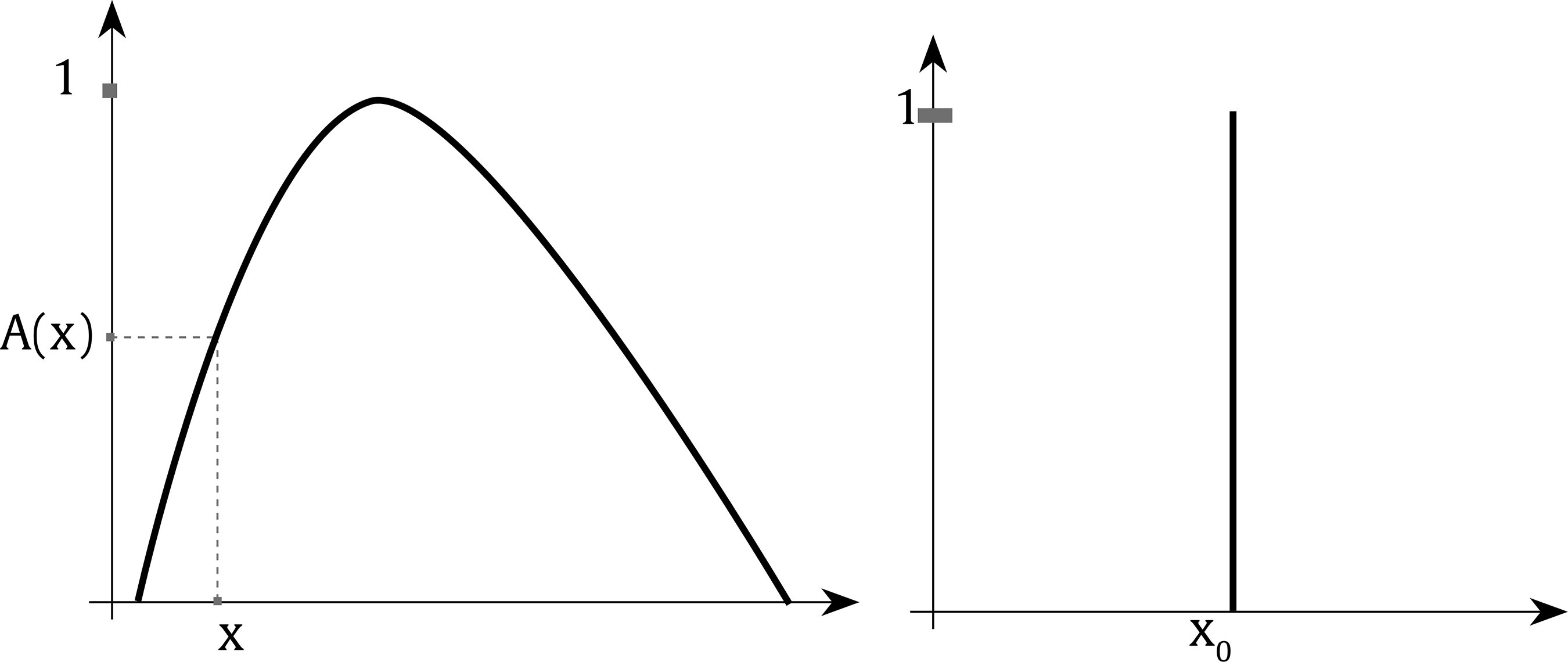 Zadeh (1972, 1973) considers that the key elements in the way human beings think are not numbers, but labels of fuzzy sets in which the transition from membership to non-membership is gradual rather than abrupt. He therefore created the linguistic variable concept, a variable that takes different values from natural language, which turned into computing with words (Zadeh, 1996), as a complement to numeric computation. For example, “validity” is a linguistic variable if its values are “low”, “average”, and “high”. These terms can be characterized as fuzzy sets, whose membership functions are shown in Figure 2 (e.g., Lee, 1990a, 1990b). Figure 2 “Validity” is a Linguistic Variable with Three Terms: “Low”, “Average”, and “High”. 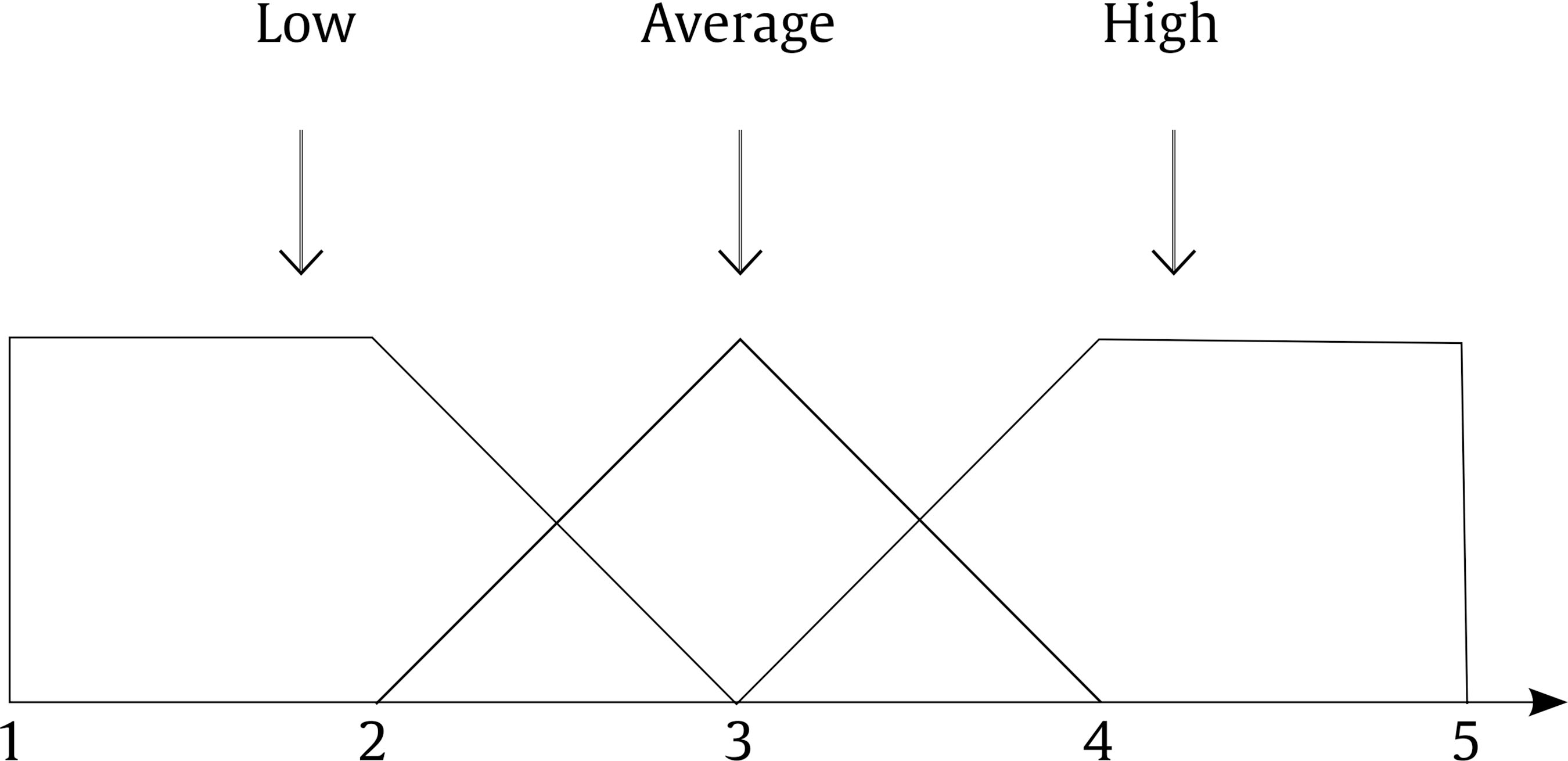 Computing with words has been widely used in many fuzzy application systems, such as decision making or control, due to the fact that it is often impossible or almost impossible to measure exact values. In some cases, there is a tolerance for imprecision that can be exploited to achieve robustness or a low-cost solution. The simplest membership functions are triangular and trapezoidal membership functions. The relationship between fuzzy variables is determined by rules such as “If x is A, then y is B”, where x and y are fuzzy variables. Essentially, a fuzzy logic controller (FLC) is a fuzzy logic-based system where fuzzy sets and fuzzy logic may be used either as the basis for the representation of different forms of knowledge about the problem, or to model the interactions and relationships among the system variables. These kinds of systems constitute an extension of classical rule-based systems, considering IF-THEN rules whose antecedents and consequents are composed of fuzzy logic (FL) statements rather than classical logic statements. In its simplest form, an IF-THEN rule follows the pattern “IF x is A THEN y is B” characterized by an IF part, called the “antecedent”, and a THEN part, called the “consequent”. The antecedent of a rule contains a set of conditions, while the consequent contains a conclusion. If the conditions of the antecedent are satisfied, then the conclusions of the consequent apply. Subsequently, a decision matrix is constructed with fuzzy rules in order to compare the data included in these rules. This process is called the “decision-making logic”, which simulates human decision making and infers fuzzy control actions employing fuzzy implication and the rules of inference in fuzzy logic. The typical configuration of a fuzzy logic control system has four main components (Passino & Yurkovich, 1998): a fuzzification interface, an inference engine, a fuzzy rule base (a set of IF-THEN rules), and a defuzzification interface (see Figure 3). Figure 3 Fuzzy System Controller. 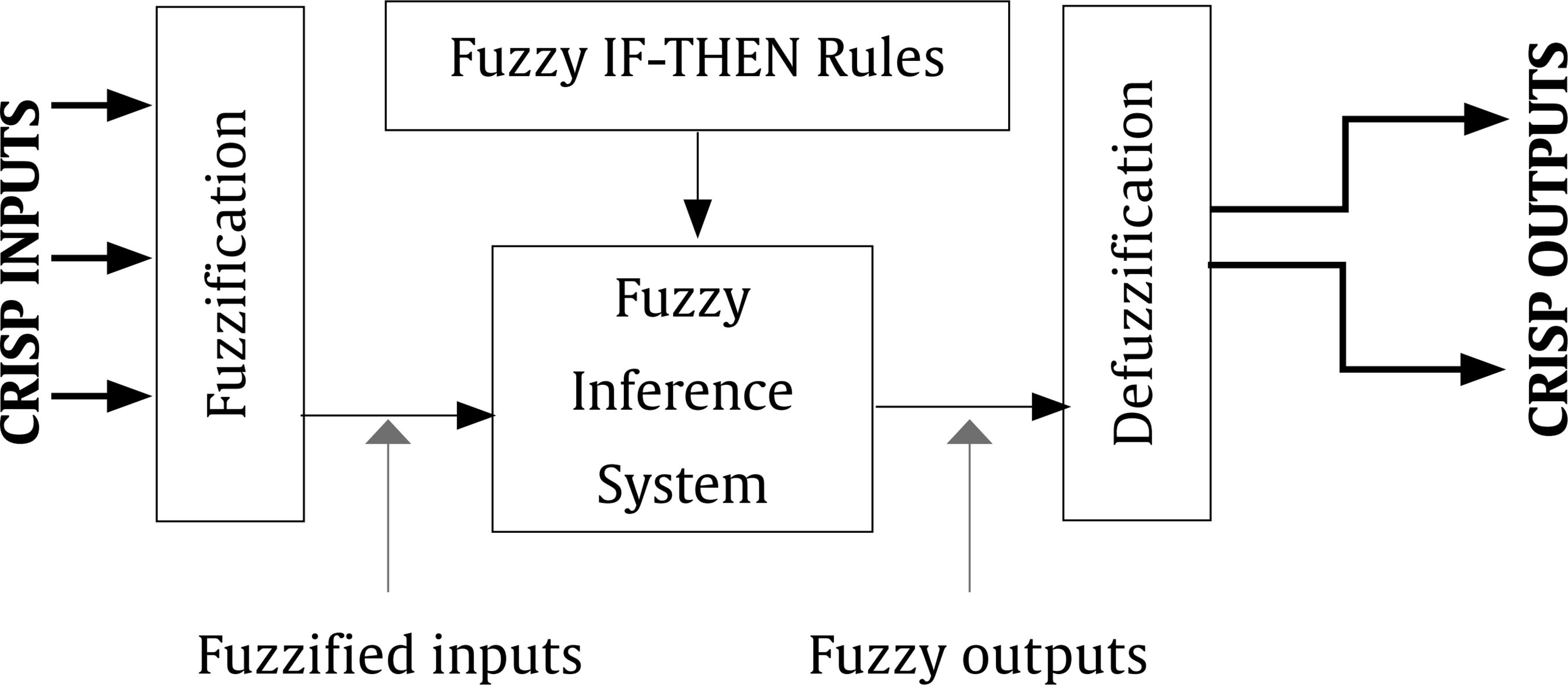 The fuzzification interface converts the crisp inputs to fuzzy sets. This is done by applying a fuzzification function that compares the input variables with the membership functions on the antecedent part, in order to obtain the membership values of each linguistic label. If the antecedent of the rule has more than one part, a fuzzy operator (T-norm for AND operation, and S-norm for OR operation) is applied to obtain a single membership value. The inference engine uses the IF-THEN fuzzy rules provided by experts to convert the fuzzy inputs into the fuzzy outputs. For this purpose, the fuzzy inference system combines (through a specific T-norm operator called implication operator) the membership values on the antecedent part to generate the qualified consequents of each rule, depending on its firing strength. A new aggregation operator is then performed to combine the results derived from all of the rules. Finally, the defuzzification interface converts the fuzzy conclusions, reached by the inference mechanism, into crisp outputs; that is, it evaluates which rules are relevant at the current time and then decides what the output should be. The fuzzy rule base holds the knowledge in the form of a set of partitions and fuzzy rules, and the defuzzification interface converts the fuzzy conclusions reached by the inference mechanism into crisp outputs. As Zadeh (2008, p. 2753) states: “Basically, fuzzy logic is a precise logic of imprecision and approximate reasoning”. The most important and commonly used type of fuzzy inference method is Mamdani’s fuzzy inference method. This method was introduced by Mamdani (1974, 1975) and his colleagues, motivated by Zadeh’s two seminal papers on fuzzy algorithms (Zadeh, 1968) and linguistic analysis (Zadeh, 1973). Another well-known inference method is the Takagi-Sugeno method of fuzzy inference process (Takagi & Sugeno, 1985). The main difference between the two methods lies in the consequent of fuzzy rules. Mamdani fuzzy systems use fuzzy sets as rule consequent (which we are going to use in this study), whereas Takagi-Sugeno fuzzy systems employ linear functions of input variables as rule consequent. Although fuzzy logic control has been one of the most active and fruitful areas for research on the application of fuzzy set theory for more than 40 years, state-of-the-art libraries to model fuzzy logic controllers still have major limitations in terms of licensing, cost, design, and implementation. In this study, we implemented the Mamdani-type fuzzy logic control with FuzzyLite (Rada-Vilela, 2018), a free open-source fuzzy logic control library that is simple and easy to use. To summarize, the fuzzy set theory proposed by Zadeh (1965a)appears to be an essential tool to provide a decision framework that incorporates the imprecise judgments that are inherent in the personnel selection process (Dursun & Karsak, 2010). However, despite many proposals for the use of a fuzzy approach in personnel selection, most of the research has been based on its theoretical framework and simulation data (Güngör et al., 2009; Jessop, 2004), and has been lacking in empirical data and adequate samples sizes. So, taking all the aforementioned into account, the present research aims to overcome these caveats and attempts to identify biodata than can be used in personnel selection for managerial positions in public organizations. In our desire to go beyond traditional measurement by means of Likert scales, we wished to investigate the use of fuzzy rule-based systems, with a view to choosing the best biodata in terms of job performance, fairness, and privacy according with manager and applicant perspectives. Participants This research includes two types of target group participants: public managers and applicants. Regarding managers, the public administration of the Principality of Asturias (Spain), a context that has promoted organizational research (e.g., Salgado & Cabal, 2011), provided the research team with a database of twenty senior managers from the regional government. All of them were contacted and informed about the purposes of the research. Twelve senior managers (60%) agreed to participate in this study. The other eight declined the invitation. The managers (50% women) were from different areas (e.g., health, training, taxes, financial management, and legal control). We consider them as senior managers, as their decisions impact on public policies and they supervise a large number of employees. Despite working in different areas, they have similar tasks and responsibilities. All of them have over 10 years of experience in managerial positions and personnel decision making. The applicants were 100 final-year undergraduates and graduate students from Asturias and Aragón, all of whom were looking for a job and were familiar with human resources academic content. Half of them had previous work experience, 45% (M = 4.09 years, SD = 5.30, mode = 1), the majority were women (73%), and the mean age was 24.73 (SD = 5.51). Procedure and Measurements The study consisted of two stages. Stage one aimed to identify adequate biodata to assess potential public managers and stage two aimed to evaluate manager and applicant perceptions of the biodata developed in stage one. In stage one, the research team gathered data from two focus groups composed of those managers playing the role of subject matter experts in order to give us information about which biodata items were considered relevant for use for public manager positions. The focus groups were led by a member of the research team, while the other two members recorded the session and took notes. The leader elicited reflections and thoughts from the experts by using open questions like “Which of your skills do you think have helped you when leading teams?”. The remaining research members compared their notes with the recordings after each meeting, in order to reach a high level of agreement (Cohen’s kappa = .89). At the end of this procedure, 26 biodata items were identified. Subsequently, in the second stage of the study the biodata proposed by the focus group were included in a questionnaire to ask the participants (the same managers and the recruited applicants) about their perception of the degree to which each biodata was able to: (1) predict job performance, (2) ensure fairness, and (3) protect the privacy of respondents. Every biodata item was evaluated according to the following three dimensions on a Likert scale, from 1 (totally disagree) to 5 (totally agree). The questionnaire was sent by e-mail to the managers, and all of them (100%) replied. Applicants filled out the same questionnaire as managers, but in paper-and-pencil format. Analysis First we analyzed the responses of the managers and applicants with descriptive statistics (M, SD), and then estimated the face validity value for each biodata from the average scores for performance, fairness, and privacy, hereinafter referred to as the “traditional approach”. We then proceeded with the development of fuzzy rules based on the same scores, using the FuzzyLite library (Rada-Vilela, 2018). The main elements involved are: the range of input crisp variables (performance, fairness, and privacy) is [1, 5], which is covered by three overlapping triangular and trapezoidal membership functions representing the labels: “low”, “average” and “high” (see Table 1 and Figure 2). The same scheme is also used for the output variable (validity). A total of 12 rules (e.g., If performance is average and fairness is average and privacy is average, then validity is average) were developed to find the optimal output, taking into account information given by the subject matter experts and the research team (the fuzzy rules can be found in the Appendix). A fuzzy validity estimation coefficient was compared with the traditional face validity estimation coefficient. The differences between both approaches were estimated using the lambda estimator. Table 1 Labels and Membership Functions of Input and Output Variables  Following the fuzzification process (see Figure 4), the antecedent of each rule was computed by selecting minimum value, since the inputs of the rule are combined via AND operation, implemented through the minimum T-norm, that is, µA∩B = min {µA(x), µB(x)} being µA and µB the membership functions of the fuzzy numbers A and B, respectively. In the implication step to compute consequent of the rule from given antecedent values, the minimum T-norm operator is used as an activation operator. The aggregation of the fuzzy outputs of all rules was then performed by using, in this case, the maximum S-norm, that is, µAUB = max {µA(x), µB(x)} (Figure 5). Figure 4 Process of Fuzzification of Crisp Inputs (for instance, µA(3.69)=0.00/Low + 0.31/Average + 0.69/High). 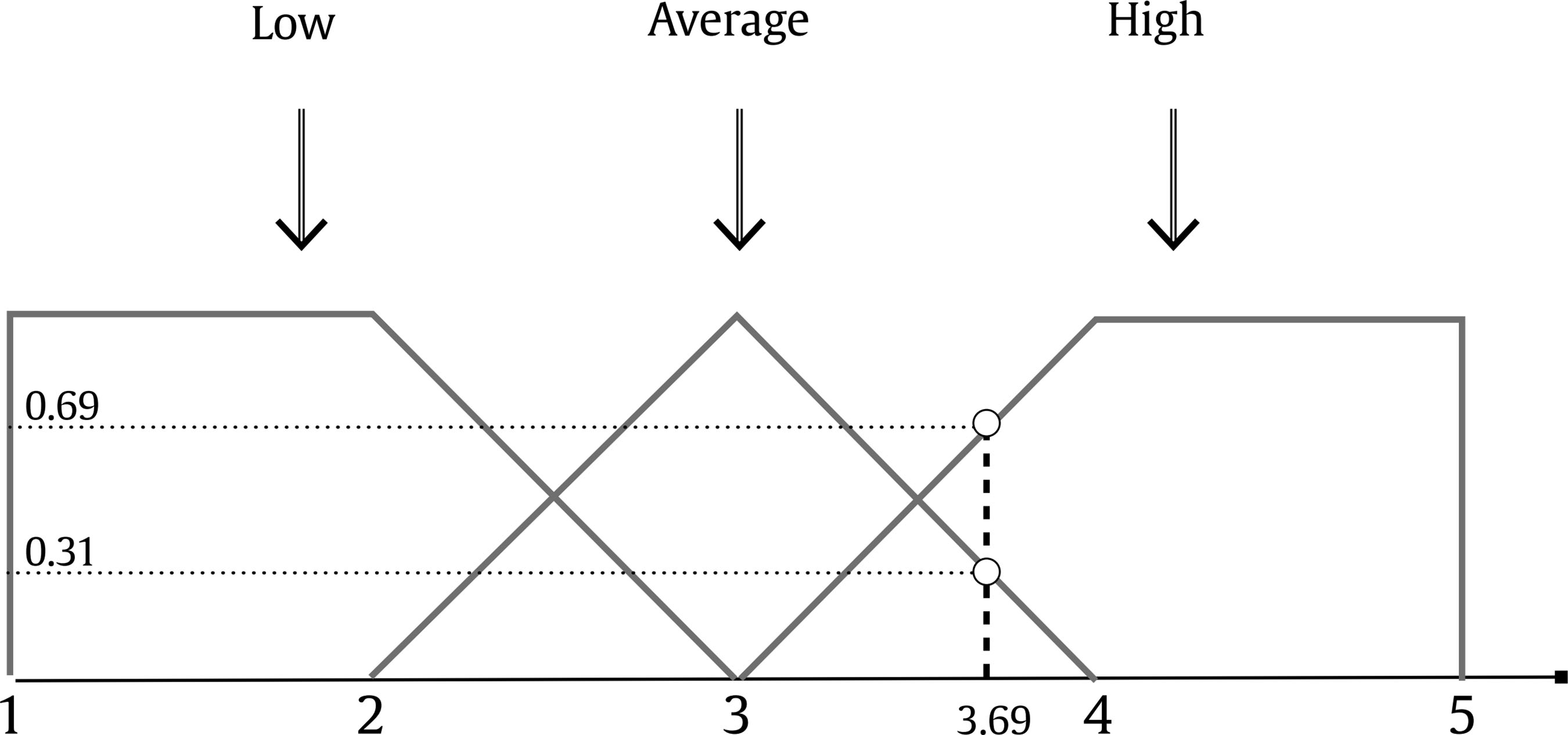 Figure 5 Fuzzy System Controller. 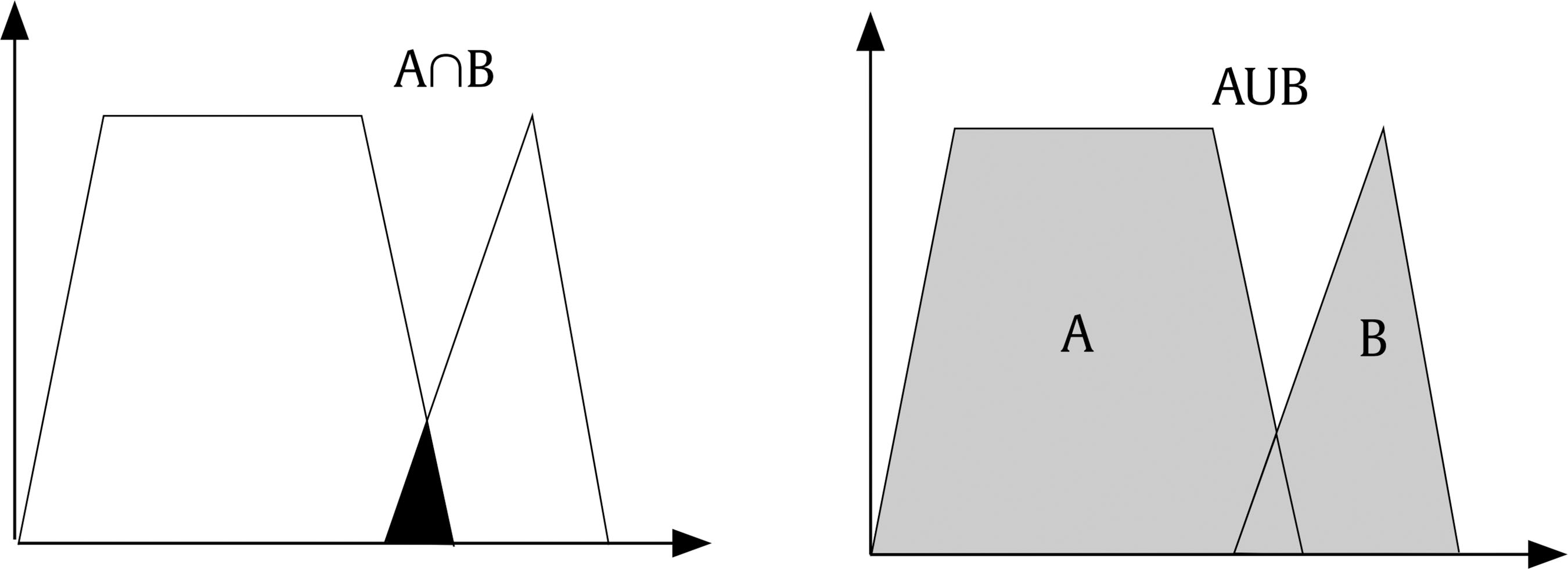 Having obtained the fuzzy outputs, the centroid method was applied to compute crisp output in the last defuzzification step. With the centroid method, the crisp output is chosen as the point where a vertical line would slice the aggregate set into two equal masses, that is, the centre of gravity (CoG). Mathematically, this can be expressed as Figure 6 Centroid Method for Defuzzification Process. 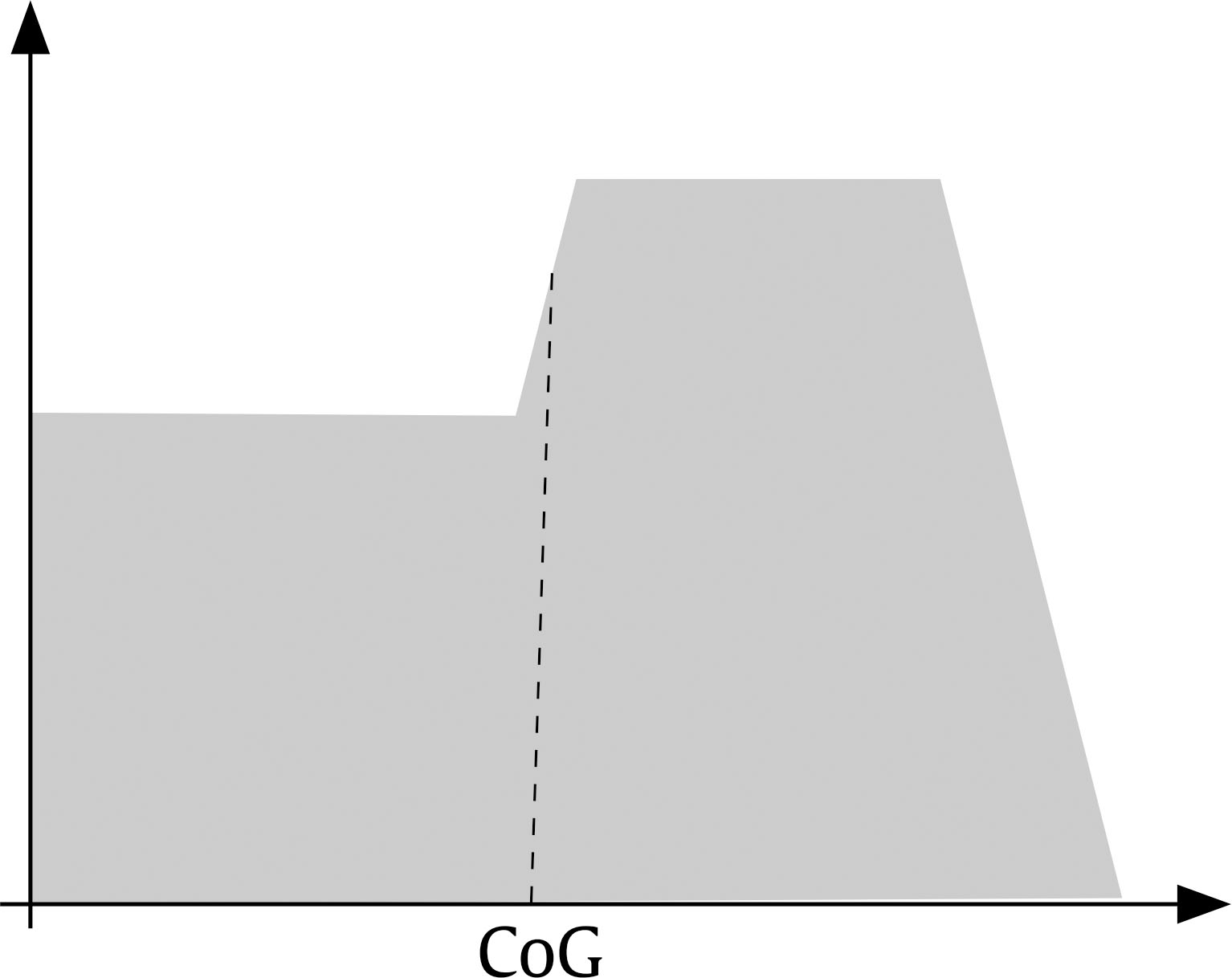 An example of the functionality of FuzzyLite is shown in Figure 7. We therefore conclude that the fuzzy approach can be used to improve personnel decisions, in terms of inclusiveness and equality, when using biodata in the selection process for public management positions. Figure 7 Example for Illustration of FuzzyLite Interface. 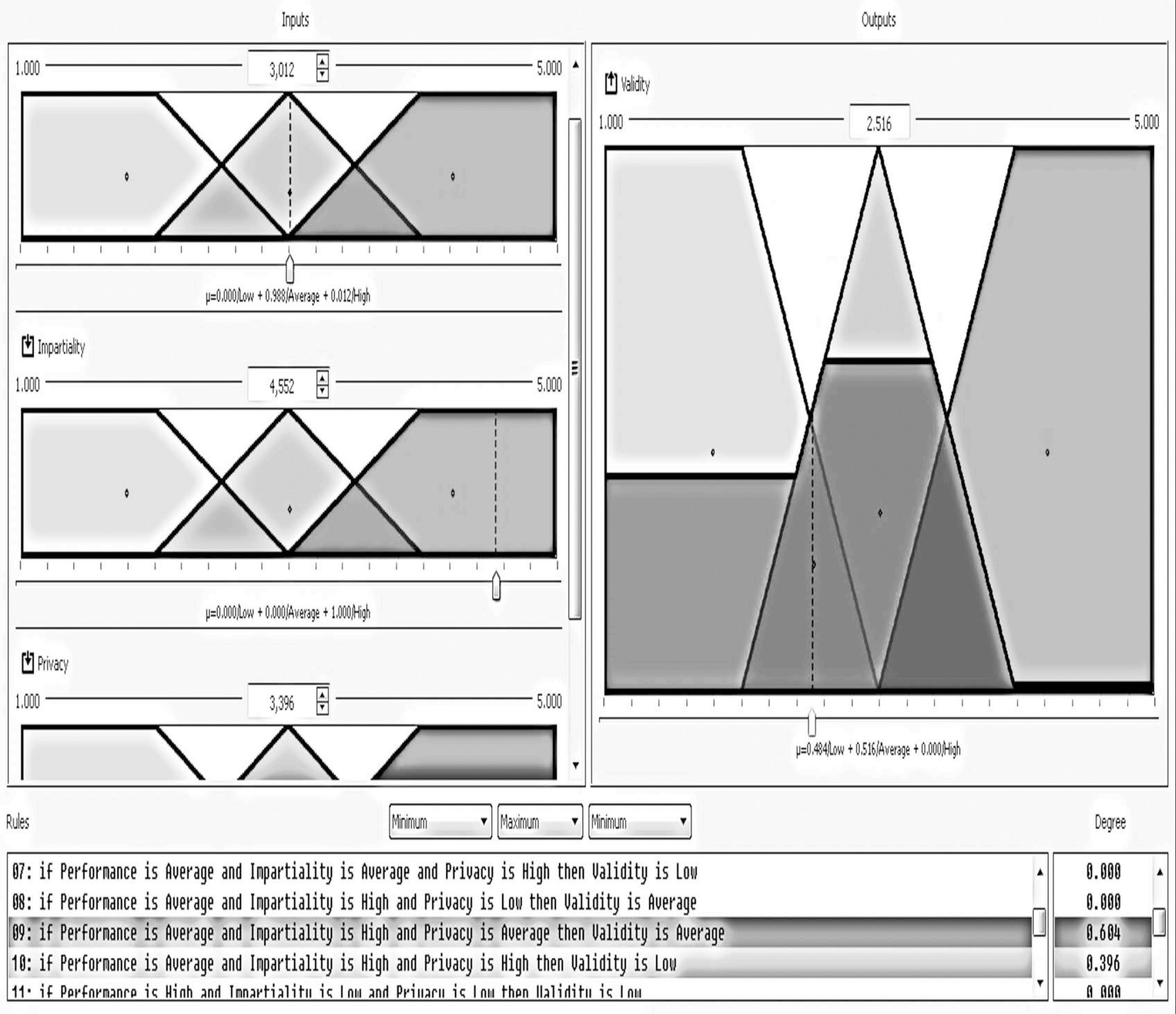 In stage one (focus group), we found 26 biodata items, which are shown in Table 2. The research team analyzed the content of this biodata, and classified them into five categories: (1) quality of experience, composed of the first fifteen items (e.g., “Have you delivered training for more than one hundred hours?”); (2) managerial competences, composed of four items, from the 16th to the 19th (e.g., “Do you consider yourself as creative when problem solving?”); (3) innovation and proactivity, from the 20th to the 22nd (e.g., “Do you think technology is a real help in public management?”); (4) social responsibility, composed of items 23 and 24 (e.g., “Should Public Administration be oriented to citizen service?”); and finally (5) transparency, with the two remaining items, 25 and 26 (e.g., “Do you agree that citizen’s charters should be compulsory for public services?”). After analyzing Table 2, we can conclude that 17 items (65.38 %) were verifiable biodata related with previous behaviour, and 12 items (46.15%) were job related, that is, related to performing a management position. Table 2 Biodata Identified through Focus Group with Public Managers 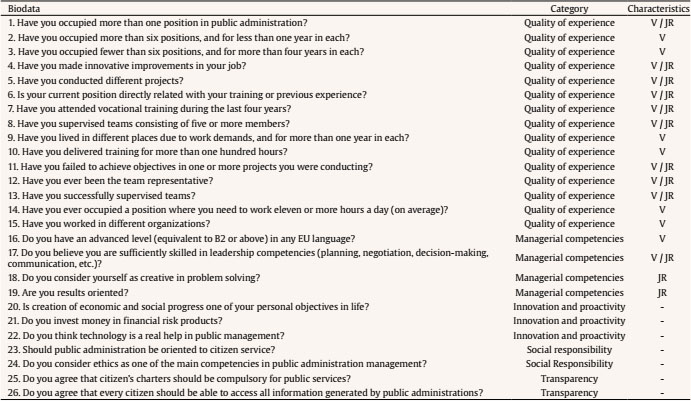 In stage two, all the biodata previously identified in stage one were applied to both managers and applicants. Respondents assessed their perception of each biodata in terms of performance, fairness, and privacy. The list of descriptive statistics of the items (M, SD) can be found in Table 3. As we can see, none of the items succeed in simultaneously fulfilling all of the requirements of job performance relatedness, fairness, and privacy. For example, item 17 is considered by managers as high in relation to job performance (M = 4.75) and fairness (M = 4.67), but one of the lowest in terms of privacy (M = 2.92). There are some discrepancies between managers and applicants. For example, item 17 was scored by managers as high in job performance (M = 4.75), high in fairness (M = 4.67) but low in privacy (M = 2.92), while applicants scored it high in job performance (M = 4.36), average in fairness (M = 3.70), and high in privacy (M = 4.04). Table 3 Assessment of the Biodata according with its Validity, Fairness, and Privacy 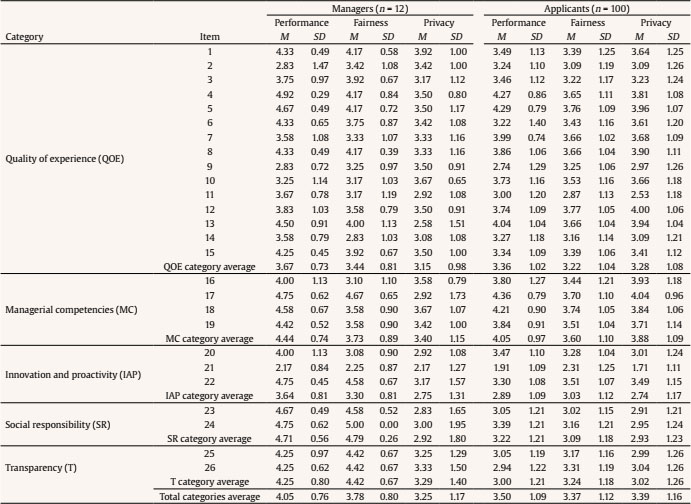 Continuing with discrepancies, applicants tend to give lower scores than managers (e.g., applicants only scored 4 or higher in 6 items, while managers scored 4 or higher in 17 items). Managers reported a higher mean in performance (Mmanagers = 4.05, Mapplicantss = 3.50) and fairness (Mmanagers = 3.78, Mapplicants = 3.37), while applicants reported a higher mean in privacy (Mmanagers = 3.25, Mapplicants = 3.39). According to standard deviations, managers present higher variability than applicants in their scores, as deviations ranged from 0.76 to 1.17 (managers) vs. 1.09 to 1.16 (applicants). When it comes to privacy, mean values are lower than the other two criteria, showing values below 4 in all biodata, except when talking about items 12 and 17 in the case of applicants. In general, standard deviations show more variability and higher than in job performance and fairness criteria. Focusing only on the biodata items with the higher scores (4 or more), managers assessed 17 items (65.38%) as characterized by high in performance, 11 items (42.31%) as high in fairness, and none (0.00%) as high in privacy. Applicants assessed 5 items (19.23%) as characterized by high in performance, none (0.00%) as high in fairness, and 2 items (7.69%) as high in privacy. Managers and applicants only agreed on 5 items (19.23%), and always related with performance (items 4, 5, 13, 17, and 18). Thus, we observed important differences in the assessment of biodata. After studying each criterion, we elaborated a composite measure including all the criteria, that is, performance, fairness, and privacy (i.e., perceived face validity) using two different methods: (1) traditional approach (i.e., mean value of the three criteria) and (2) fuzzy logic (i.e., applying fuzzy rules). The results shown in Table 4 once again demonstrate that managers report higher scores than applicants. For example, mean values are 3.64 (traditional approach) and 3.56 (fuzzy logic) for managers, while mean values for applicants are 3.40 for traditional and 3.43 for fuzzy logic. If we only trust the traditional method, we can choose items that score the mean or higher in both the manager and applicant sample, i.e., items 1, 4, 5, 6, 8, 13, 17, 18, and 22. Applying the same rationale for fuzzy logic, the items are 1, 4, 5, 8, 13, 16, 17, 18, 19, and 22. Both approaches agreed on 8 items (i.e., 1, 4, 5, 8, 13, 17, 18, and 22) which represents 30.77% of the total biodata items. Most of these are verifiable and job-related, except item 18, which is non-verifiable, and item 22, which is neither verifiable nor related to the work setting. Similarly, most are related with the quality of experience category and none belong to the social responsibility or transparency categories. Table 3 Perceived Validity of Biodata by Means of Traditional and Fuzzy Logic Approaches 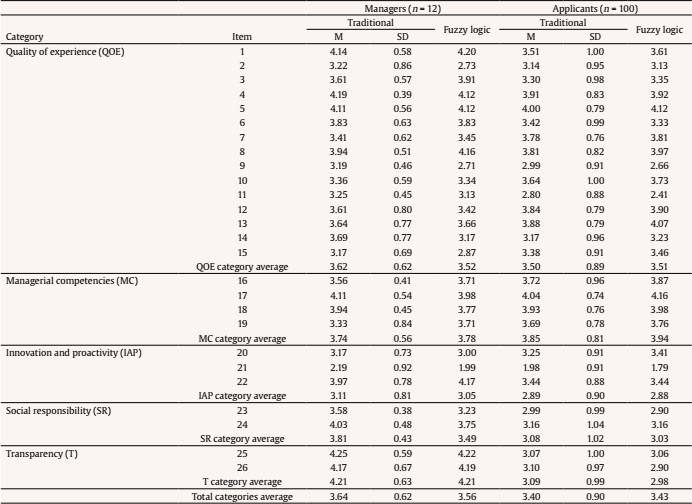 Given the fact that there are differences between managers and applicants, and between the two approaches (traditional vs. fuzzy), we wanted to further investigate the correspondence between them. We therefore classified the items as “inadequate” if they had face validity below the average, and “adequate” if they are at the average value of each category or higher. We used this criterion for making comparisons with the traditional approach because the fuzzy logic approach only gives us one data per biodata. We then made four comparisons: two comparisons between participants scores (managers vs. applicants), depending on the approach (traditional vs. fuzzy logic), and two comparisons between the approaches, depending on the type of participants who score. The results of the comparisons are shown in Table 5. As can be seen, managers and applicants performed different classifications, irrespective of the approach used (traditional or fuzzy), but there is an association between the type of participants according with the approach, i.e., the classification performed by managers using traditional and fuzzy methods (λ = .67, p ≤ .001), and by applicants (λ = .83, p ≤ .001) using both methods. These results indicate that managers and applicants are scoring in a substantially different way, and that the fuzzy approach is able to refine the scoring method in both collectives. The present study aims to identify the most effective biodata items to perform a personnel selection procedure for public manager positions according with manager and applicant face validity. In addition, we explore the use of fuzzy logic in an attempt to improve the selection of biodata. We can draw some conclusions from our results: (1) it is difficult to find biodata items that simultaneously fulfill all three criteria of performance prediction, fairness, and privacy; (2) privacy is considered low in all situations; (3) managers and applicants differ substantially in their assessment of biodata items; (4) most of the best-assessed items are verifiable and job related; (5) the fuzzy logic approach is related with the traditional approach, but shows different results; (6) combining both approaches, we can find 8 adequate biodata; (7) the chosen items mostly belong to the quality of experience category (5 items), followed by the managerial competencies category (2 items), and the remaining two belong to the innovation and proactivity categories (1 item). We will now discuss these findings. The difficulties encountered in finding a biodata item that is perceived as adequate for performance prediction, while at the same time ensuring fairness and guaranteeing privacy, may be explained by the findings by Furnham (2017), where biodata were considered lacking in terms of validity, practicality, and legality. Since no biodata meets all the criteria, practitioners tend to see this assessment technique as insufficiently appropriate. This can be seen as one of the caveats of the science-practice gap in biodata. To contribute to filling this gap, we encourage performing and reporting more research on biodata at item-level in applied contexts (Breaugh, 2009) in the way we present in this research. The findings also indicate that data privacy regarding almost all biodata items is not a fulfilled criterion in terms of face validity in both target groups: managers and applicants. These findings indicate that human resources specialists that design selection procedures for public manager positions should take a more careful approach to the issue of privacy and biodata. More research should be carried out in this regard, in order to gain a deeper understanding of what motivates individuals to consider some biodata items more private than others, and why they are unlikely to disclose this kind of information during a personnel selection procedure. The discrepancies between managers and applicants is another interesting issue. We can see in our results that applicants tend to assign lower validity scores than managers, yet both have a similar opinion as to which biodata items are useful. This result could be due to some artifacts, for example, sampling issues (differences in sample size, demographics, etc.). We believe that further research should be conducted to verify these differences in biodata scoring. Our results also show that items that are verifiable and job related obtain better scores than others. These results contribute to previous literature focused on identifying which biodata demonstrate a higher relationship with job performance or turnover (e.g., Becton et al., 2009; Cole et al., 2003; Schmitt et al., 2003). We can also affirm that we found positive reactions to this kind of biodata from both managers and applicants. We would therefore recommend limiting the use of biodata to those items regarded as verifiable and job-related (items 1, 4, 5, 8, 13, and 17) as good practice that helps to avoid negative applicant reactions and intention to litigate (Salgado et al., 2017). Regarding categories, we found that the chosen items are mostly from “quality of experience”, followed by “managerial competencies”, and the “proactivity and innovation” categories. These findings help us to establish which managerial competencies should be focused on when developing biodata scales. Table 5 Comparisons by Collective (managers vs. applicants) and Approach (traditional vs. fuzzy logic) 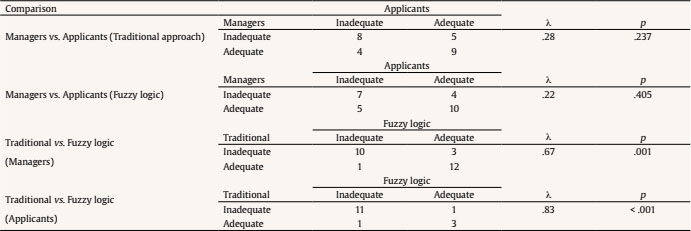 Note. An item is classified as adequate if its face validity is at the average value or higher. To summarize the aforementioned, our research findings indicate a number of practical implications, namely, (1) there are 8 items that may be useful in the selection of managers, although two of them should be discarded; (2) to ensure positive reactions, biodata items should be simultaneously verifiable, job-related, and related with respondents’ quality of experience; and finally, (3) we have obtained some fuzzy rules than may help in the decision process when choosing biodata, but consideration should be given to whether the added value of fuzzy logic justifies its use in applied contexts. In our study, we also wished to explore the use of fuzzy logic to choose biodata. Both approaches have reached similar outcomes, but with some slight differences. Using the traditional approach we found 9 appropriate biodata items, while using fuzzy logic we found 10. Differences were found with 3 items: item 6 is appropriate according with the traditional approach, but items 16 and 19 are appropriate according with fuzzy logic. Thus, when combining the traditional and fuzzy logic approaches, we found 8 effective biodata items (1, 4, 5, 8, 13, 17, 18, and 22) that fulfill the research-imposed criteria and could consequently be used in personnel selection procedures for public manager positions. Although we can conclude that combining traditional and fuzzy logic approaches improves biodata item selection, the results of our research suggest that practitioners may find some drawbacks to its use: (1) fuzzy data analysis requires training, which costs both time and money; (2) the benefit of using both approaches is minimal when compared to using only the traditional approach, which is faster and cheaper. Nevertheless, from a scientific point of view, we encourage further research on this topic. Although fuzzy logic may be seen as a hard-to-follow mathematical procedure, fuzzy logic could be useful for decision making in personnel selection when combining data or information from different sources and metrics, as when mixing qualitative (e.g., verbal, document, archival information) with quantitative (e.g., different test scoring methods), creating fuzzy rules and screening candidates according with such rules. Another approach that permits the combination of information from different sources for making decisions, which we have explored previously (García-Izquierdo et al., 2010), is the maximum entropy principle, but this also requires advanced statistical knowledge. We need to acknowledge that some methodologies are difficult to implement in applied settings, and recognize the need to fill this gap between science and practice. The present paper has some limitations that should be commented on. First, we are only examining perception, not the functioning of biodata. Further research should verify if the items we have found as adequate from the point of view of managers and applicants are able to predict job performance. However, we believe that our study represents a further step towards reaching a consensus as to which characteristics biodata items must present, at least in the public sector. Another limitation is related to the generalizability of our research findings. The manager sample size is small and pertains to a single organization, as we focused on only one administration in a local area of Spain. That said, the quality of the respondents, as experts, makes the results highly valuable. Conflict of Interest The authors of this article declare no conflict of interest. Acknowledgements This research would not have been possible without the cooperation of the applicants, experts, and managers who helpfully participated in the research. We want to thank Adrian Furnham (University College of London), Begoña Herminia Menéndez López (Universidad de Oviedo) and Dana Balas Timar (Aurel Vlaicu University of Arad) for their help and fruitful commentaries. Cite this article as: García-Izquierdo, A. L., Ramos-Villagrasa, P. J. & Lubiano, M. A. (2020). Developing biodata for public manager selection purposes: A comparison between fuzzy logic and traditional methods. Journal of Work and Organizational Psychology, 36(3), 231-242. https://doi.org/10.5093/jwop2020a22 Funding: This research was funded by Ministerio de Economía y Competitividad and Fondos Sociales Europeos (references PSI-2013-44854-R and MTM2015-63971-P); Cátedra Asturias Prevención (reference CATI-04-2018); Universidad de Oviedo (UNOV-12-MC-01) and Consejería de Economía y Empleo del Gobierno del Principado de Asturias and Fondos Europeos de Desarrollo Regional (reference FC-GRUPIN-IDI/2018/000132). References Appendix
|
Cite this article as: García-Izquierdo, A. L., Ramos-Villagrasa, P. J., & Lubiano, M. A. (2020). Developing Biodata for Public Manager Selection Purposes: A Comparison between Fuzzy Logic and Traditional Methods. Journal of Work and Organizational Psychology, 36(3), 231 - 242. https://doi.org/10.5093/jwop2020a22
Copyright © 2026. Colegio Oficial de la Psicología de Madrid






 PDF
PDF e-PUB
e-PUB CrossRef
CrossRef JATS
JATS Print
Print SEND
SEND






